gt-free-ocr-metrics/omnidocbench-qwen-ocr-logprobs
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/gt-free-ocr-metrics/omnidocbench-qwen-ocr-logprobs
下载链接
链接失效反馈官方服务:
资源简介:
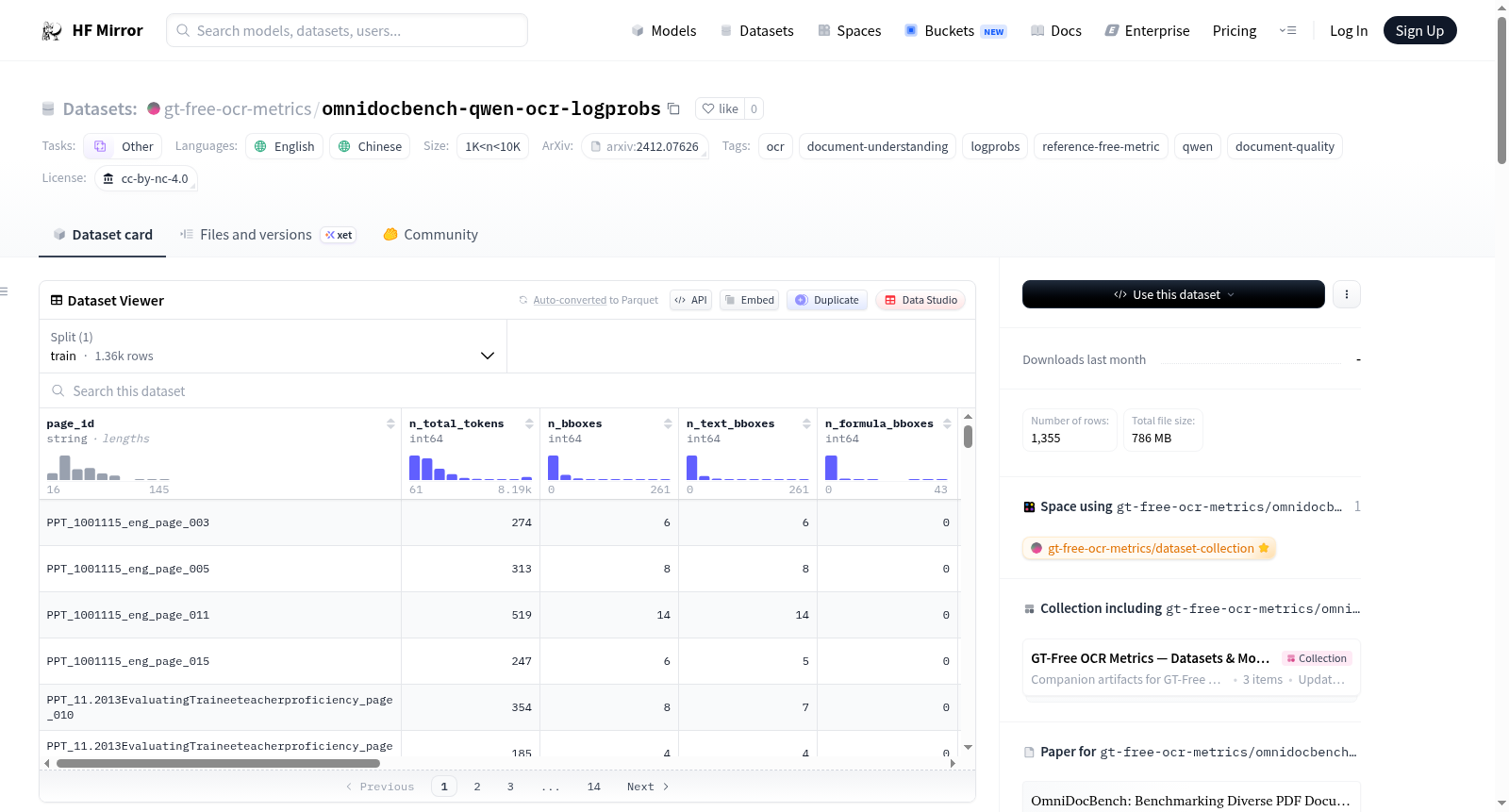
该数据集提供了由Qwen3.5-122B-A10B模型在OmniDocBench基准测试的原始页面扫描上运行的令牌级别和边界框级别的OCR日志概率。它是一个无参考的辅助信号,不依赖于真实文本,作为OmniDocBench渲染与比较研究项目的一部分发布。数据集包含1355个页面,覆盖了完整的OmniDocBench基准测试。数据集结构包括每个页面的令牌日志概率和边界框级别的统计信息,适用于研究无参考文档质量指标和不同文档类型的OCR不确定性。
This dataset provides token-level and bounding-box-level OCR log-probabilities produced by running Qwen3.5-122B-A10B on the original page scans of the OmniDocBench benchmark. It is a reference-free auxiliary signal — no ground-truth text is used — and is released as part of the OmniDocBench Render-and-Compare research project. The dataset contains 1,355 pages, covering the full OmniDocBench benchmark. The dataset structure includes per-token logprobs and per-bounding-box aggregated statistics, intended for research on reference-free document quality metrics and study of OCR uncertainty on diverse document types.
提供机构:
gt-free-ocr-metrics
搜集汇总
数据集介绍
构建方式
本数据集基于OmniDocBench基准测试中的原始页面扫描图像构建,未依赖任何地面真实文本标注。通过vLLM部署Qwen3.5-122B-A10B模型,在推理时启用logprobs和top_logprobs参数,逐令牌输出对数概率及前五候选。随后,依据OCR模型输出的HTML结构中<div data-bbox>属性所标记的边界框坐标,将生成的令牌按位置归属至对应的边界框,并聚合得到每个边界框内的统计量。最终形成覆盖1355页的全量数据集,包含令牌级与边界框级两个子集。
特点
该数据集的核心特点在于提供了一种无需参考标注的辅助信号——OCR模型内部的置信度分布,可作为文档质量评估的参考。数据涵盖文本、公式和表格三种元素类型,支持对复杂文档版面的细粒度不确定性分析。同时,数据集包含中英文双语文档,来源包括书籍、试卷、幻灯片、财务报告与学术论文,覆盖了多样化的真实场景。其边界框级别的统计量(如对数概率均值、最小值、最大值及香农熵均值、最大值)为研究OCR难度与文档布局的关系提供了量化工具。
使用方法
本数据集适用于无参考文档质量指标的构建与验证研究,可直接通过加载metadata.jsonl文件获取页面级与边界框级特征。利用ocr_logprofs目录下的逐令牌对数概率文件,可深入分析模型在特定文本区域的不确定性;借助per_bbox_logprobs目录中的边界框聚合统计,可构建基于布局元素的文档质量评估模型。数据集以JSON格式存储,便于与Python科学计算生态(如NumPy、Pandas)对接,支持批量处理与特征工程。
背景与挑战
背景概述
在文档智能理解领域,光学字符识别(OCR)技术已从简单的文本提取演进为对复杂版面结构的全面解析。2024年,上海交通大学与OpenDataLab联合发布了OmniDocBench基准数据集,旨在评估多语言、多类型文档(如书籍、试卷、幻灯片、财报与学术论文)的解析能力。在此基础上,本研究团队于2025年进一步推出了OmniDocBench Qwen OCR Log-Probabilities数据集,通过运行Qwen3.5-122B-A10B模型对原始文档扫描件进行OCR推理,提取了细粒度的token级与边界框级对数概率(log-probabilities)。该数据集的核心创新在于提供了一种无需参考文本的辅助信号,为研究者探索基于模型内部置信度的文档质量评估指标开辟了新路径,对推动文档理解评价体系从依赖人工标注向无参考自动化方向转型具有重要影响。
当前挑战
该数据集所解决的领域问题核心挑战在于:传统OCR评估高度依赖逐字符比对的参考指标,难以捕捉模型在文档不同区域(如文本、公式、表格)中的不确定性差异,且无法用于缺乏标注的实际场景。构建过程中面临多重挑战:首先,对数概率的置信度高度依赖特定OCR模型(Qwen3.5-122B-A10B),其分布特性难以直接迁移至其他架构,限制了方法的泛化性。其次,数据来源OmniDocBench在语言分布上存在显著偏差,英文文档占比过高,导致中文文档的校准结果可能偏离真实分布。再者,公式与表格边界框在多数页面中稀疏甚至缺失,使得针对这些元素的统计特征缺乏代表性。最后,分词器对数学符号与CJK字符的切分差异会扭曲逐token的统计量,增加了不确定性量化分析的复杂性。
常用场景
经典使用场景
OmniDocBench Qwen OCR Log-Probabilities数据集依托于OmniDocBench基准,提供了经由Qwen3.5-122B-A10B模型在原始页面扫描图上逐token与逐边界框的OCR对数概率信息。该数据集最经典的用途在于构建无参考的文档质量评估指标,利用模型内部的不确定性信号——即对数概率的分布特征——来间接度量OCR过程的难度与可靠性。研究者可以将这些logprobs作为特征,训练或设计无需真值文本即可评价文档解析质量的度量器,弥补传统依赖人工标注的评估方法在效率和扩展性上的不足。此外,该数据集还可服务于对OCR模型在不同文档类型(如书籍、试卷、幻灯片、财务报告)上预测置信度的系统分析,为理解模型的行为边界与改进方向提供数据支撑。
实际应用
在实际工业应用中,OmniDocBench Qwen OCR Log-Probabilities数据集的直接价值体现在文档质量监控与自动化流程优化方面。大型企业、金融机构或数字化服务商在批量处理票据、合同、研究报告等文档时,可以利用该数据集训练出的无参考质量评估模型,实时监测OCR输出的置信度水平,自动标记疑似低质量的识别结果以供人工复核,从而有效降低后期纠错成本。在数字图书馆、在线教育平台等场景下,对试卷、教材页面的识别可靠性进行按页评分,能够辅助决策是否启用更高成本的二次处理流程。此外,该数据集也能驱动基于置信度的自适应OCR管道设计,例如在低logprob区域(即模型不确定处)触发专用模型或规则补充解析,显著提升端到端文档数字化系统的鲁棒性。
衍生相关工作
该数据集的构建逻辑与发布工作已催生出多个方向的后续研究。一个重要脉络是围绕无参考文档质量指标的设计竞赛,研究者基于此数据集提出了新的度量公式,如将shannon熵与对数概率均值融合,用于更精准地预测OCR的字符错误率(CER)。另一类衍生工作致力于logprob特征的跨模型迁移,探索如何将Qwen模型的行为知识通过知识蒸馏或对抗训练传递到轻量级OCR模型中,在不增加推理开销的前提下提升其不确定性估计能力。此外,该数据集也为文档布局分析与重建任务提供了额外的弱监督信号,一些工作尝试将边界框级的统计量作为辅助损失项,联合训练更加稳健的版面解析模型。这些衍生研究共同拓展了数据集的影响力,使其成为推动文档智能领域从结果导向向过程可解释方向转型的重要基础设施。
以上内容由遇见数据集搜集并总结生成


