T2I-CompBench
收藏arXiv2023-10-30 更新2024-06-21 收录
下载链接:
https://karine-h.github.io/T2ICompBench/
下载链接
链接失效反馈官方服务:
资源简介:
T2I-CompBench是由香港大学和华为诺亚方舟实验室共同创建的综合性文本到图像生成基准数据集,包含6000个文本提示,分为属性绑定、物体关系和复杂组合三个大类,涵盖颜色、形状、纹理、空间关系和非空间关系等多个子类。该数据集旨在评估和提升文本到图像生成模型的组合能力,解决现有模型在组合多个具有不同属性和关系的物体时的问题。数据集通过预定义规则和ChatGPT生成,易于扩展,适用于开放世界场景下的文本到图像生成研究。
T2I-CompBench is a comprehensive text-to-image generation benchmark dataset co-created by The University of Hong Kong and Huawei Noah's Ark Lab. It contains 6000 text prompts, which are divided into three major categories: attribute binding, object relationship and complex composition, covering multiple subcategories such as color, shape, texture, spatial relationship and non-spatial relationship. This dataset aims to evaluate and enhance the compositional capabilities of text-to-image generation models, addressing the problems encountered by existing models when combining multiple objects with different attributes and relationships. Generated via predefined rules and ChatGPT, the dataset is easily scalable and suitable for text-to-image generation research in open-world scenarios.
提供机构:
香港大学
创建时间:
2023-07-13
搜集汇总
数据集介绍
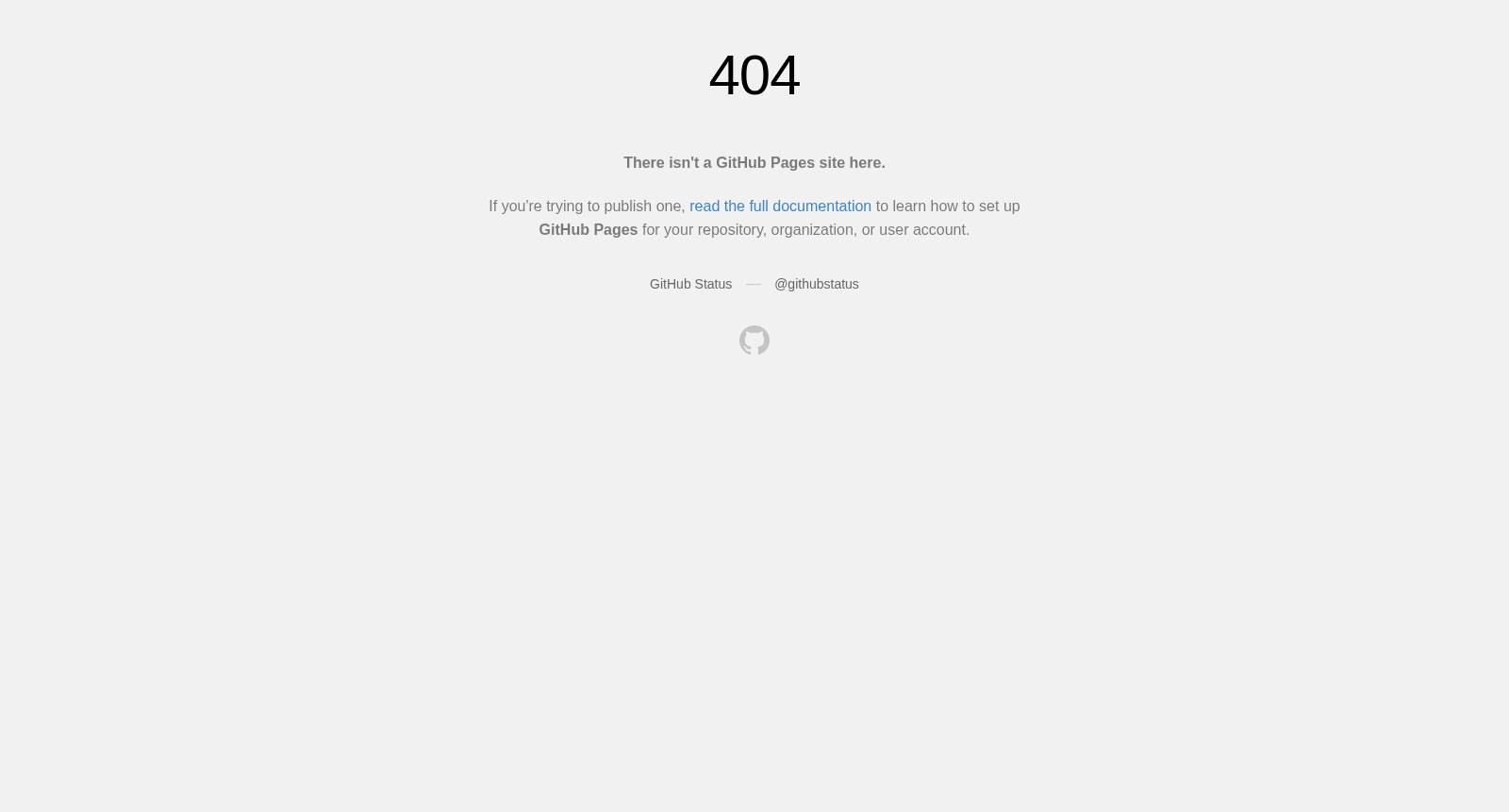
构建方式
在文本到图像生成领域,现有模型在处理多对象属性绑定与空间关系时仍面临挑战。T2I-CompBench的构建采用了系统化方法,通过结合预定义规则与ChatGPT生成,创建了涵盖属性绑定、对象关系及复杂组合三大类别的6000条文本提示。具体而言,属性绑定类别细分为颜色、形状与纹理三个子类,每类包含1000条提示,其中800条采用固定句式模板,200条为自然语言描述,并在测试集中平衡了已见与未见组合。对象关系类别则包含空间与非空间关系各1000条提示,通过随机选择名词与关系词构建。复杂组合类别进一步设计了多对象、多属性混合的1000条提示,以模拟开放世界的真实场景。
特点
T2I-CompBench的突出特点在于其全面性与结构性。该数据集首次系统整合了文本到图像生成中的组合性问题,覆盖六种子类别,并引入了大规模词汇多样性,包含2316个名词、33种颜色、32种形状及23种纹理属性。其提示设计兼顾了模板化与自然语言表达,同时平衡了训练与测试集中的组合可见性,有效支持模型泛化能力评估。此外,数据集特别强调了空间关系的对比性提示设计,例如通过交换对象位置生成镜像描述,以深化对模型空间推理能力的检验。
使用方法
使用T2I-CompBench时,研究者可基于其结构化提示开展模型训练与评估。针对属性绑定任务,可采用数据集提供的颜色、形状与纹理子类提示进行细粒度测试;对象关系任务则可通过空间与非空间关系提示评估模型对交互与布局的理解。为提升评估科学性,建议结合论文提出的专用指标,如解耦BLIP-VQA用于属性绑定、UniDet检测器用于空间关系分析,以及融合多指标的3-in-1方法处理复杂组合。数据集的训练与测试划分支持模型微调与泛化性能验证,同时其开放访问特性便于后续扩展与跨模型比较研究。
背景与挑战
背景概述
随着文本到图像生成技术的迅猛发展,模型在生成高质量图像方面展现出卓越能力,但在处理复杂场景中多对象属性绑定与关系组合时仍面临显著挑战。T2I-CompBench由香港大学与华为诺亚方舟实验室的研究团队于2023年联合创建,旨在构建一个开放世界组合式文本到图像生成的综合性基准。该数据集聚焦于解决文本到图像模型在属性绑定、对象关系及复杂组合等方面的核心问题,通过涵盖6000条组合文本提示,系统评估模型在颜色、形状、纹理等属性与对象间的精确关联能力,以及对空间与非空间关系的理解与生成效果。其推出为相关领域提供了标准化评估框架,显著推动了组合式文本到图像生成技术的研究进展与模型优化。
当前挑战
T2I-CompBench致力于解决组合式文本到图像生成领域的核心挑战,即模型在复杂提示下难以准确绑定对象属性与关系,导致生成图像语义不一致。具体挑战包括:在属性绑定方面,模型易混淆多对象间的颜色、形状或纹理对应关系,例如将‘红色书本与黄色花瓶’误生成颜色互换的对象;在对象关系方面,空间布局如‘左/右’关系常被错误呈现,而非空间交互如‘持有’或‘观看’也缺乏精确表达。构建过程中,挑战体现在如何设计涵盖多样属性与关系的提示语料,确保数据集的平衡性与可扩展性,同时避免训练与测试集间的组合重叠。此外,开发专用于组合性评估的指标亦面临困难,需克服传统评估方法在细粒度对齐上的不足,以更贴合人类感知。
常用场景
经典使用场景
在文本到图像生成领域,T2I-CompBench作为一项综合性基准测试,其经典使用场景在于系统评估生成模型在复杂组合性任务上的表现。该数据集通过涵盖属性绑定、对象关系及复杂组合三大类别,为研究者提供了标准化的测试平台,用以精确衡量模型在将多对象、多属性及空间关系整合为连贯视觉场景方面的能力。
实际应用
在实际应用层面,T2I-CompBench为广告设计、虚拟场景构建及教育内容生成等跨领域任务提供了关键技术支撑。其评估框架能够优化生成模型在复杂指令下的输出质量,例如在电商场景中精确呈现商品属性与布局,或在游戏开发中高效生成符合叙事逻辑的视觉元素,从而提升自动化内容创作的可靠性与实用性。
衍生相关工作
该数据集衍生了一系列经典研究工作,例如基于奖励驱动样本选择的生成模型微调方法(GORS),以及针对组合性评估的多模态大语言模型探索。这些工作不仅扩展了文本到图像生成的技术边界,还催生了如结构化扩散、注意力激发机制等创新方法,推动了组合性生成评估范式的演进与完善。
以上内容由遇见数据集搜集并总结生成


