VISION2UI
收藏Hugging Face2024-04-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/xcodemind/vision2ui
下载链接
链接失效反馈官方服务:
资源简介:
VISION2UI数据集,由华中科技大学、北京大学、重庆大学等机构联合创建,旨在提升多模态大型语言模型(MLLMs)在用户界面(UI)设计图像生成代码方面的的能力。该数据集包含20000个样本,其中16,000个用于训练模型,2000个用于验证,2000个用于测试,每个样本包含设计图像、UI代码及其布局信息。数据来源于Common Crawl开源数据集,经过收集、清洗、筛选等一系列操作,确保了数据的高质量和真实性,并通过训练神经网络评分器对数据进行进一步筛选,保留了更高质量的实例。该数据集的构建,不仅为自动化UI代码生成的研究提供了宝贵的资源,也为初学者和设计师直接从设计图生成网页提供了可能,具有重要的应用价值和市场潜力。
The VISION2UI dataset, jointly created by institutions including Huazhong University of Science and Technology, Peking University, Chongqing University and other organizations, aims to enhance the capabilities of multimodal large language models (MLLMs) in generating code for user interface (UI) design images. This dataset contains 20,000 samples in total, with 16,000 allocated for model training, 2,000 for validation, and 2,000 for testing. Each sample includes design images, UI codes and their corresponding layout information. The data is sourced from the Common Crawl open-source dataset, and has undergone a series of processes such as collection, cleaning and screening to ensure high data quality and authenticity. Furthermore, a neural network-based scorer is employed to further filter the dataset, retaining higher-quality instances. The construction of this dataset not only provides a valuable resource for research on automated UI code generation, but also enables beginners and designers to directly generate web pages from design images, holding significant application value and market potential.
提供机构:
华中科技大学、北京大学、重庆大学等
创建时间:
2024-04-01
搜集汇总
数据集介绍
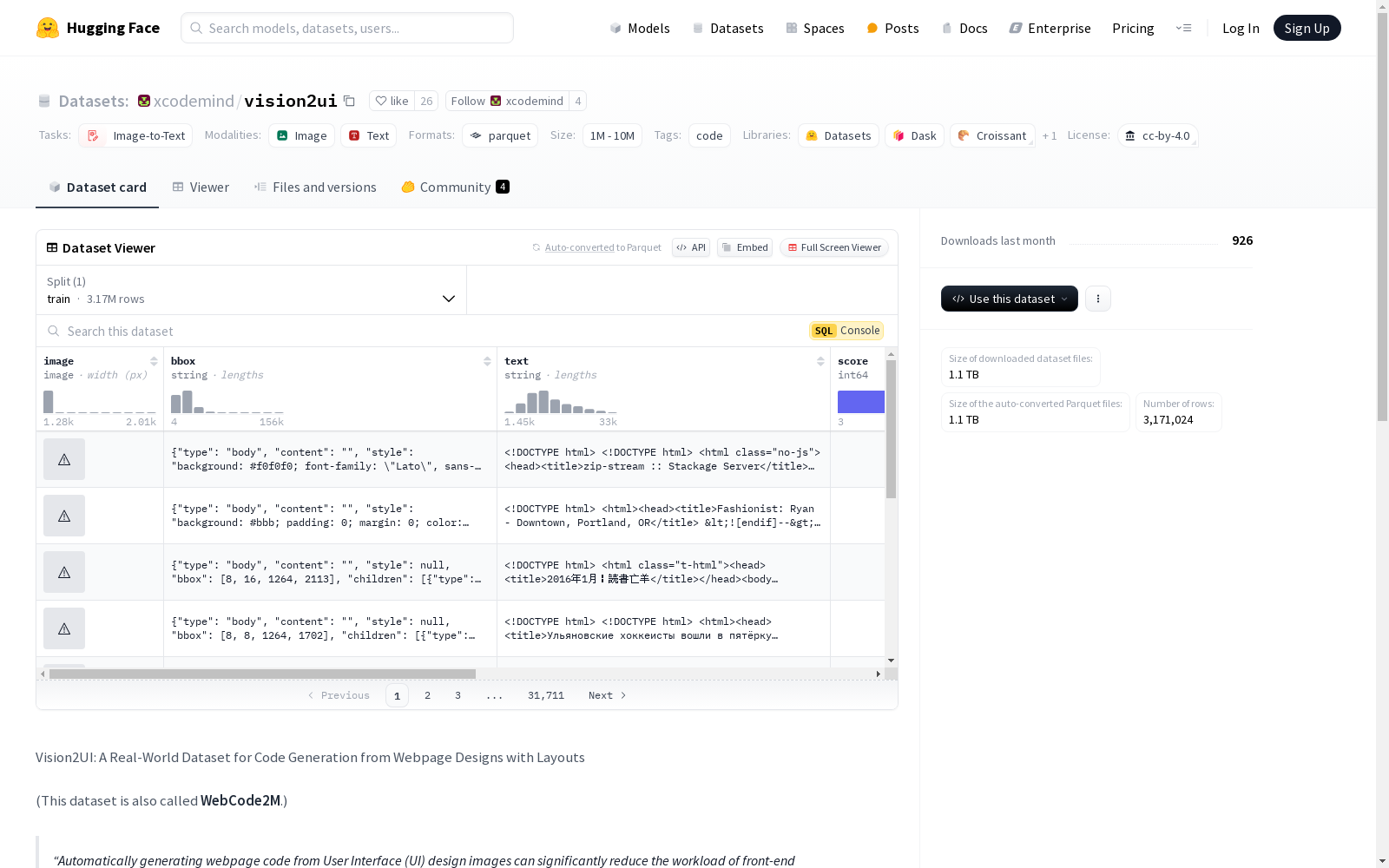
构建方式
Vision2UI数据集的构建过程基于真实世界的网页设计场景,通过精心收集、清洗和优化开源Common Crawl数据集来实现。为确保数据质量,研究团队采用了一种基于人工标注样本训练的神经评分器,对数据进行筛选,仅保留最高质量的样本。最终,该数据集包含了超过三百万个并行样本,涵盖了UI设计图像、网页代码以及布局信息,为多模态大语言模型(MLLMs)的微调提供了坚实的基础。
特点
Vision2UI数据集的核心特点在于其丰富的信息维度。每个样本不仅包含网页截图(image),还提供了详细的布局信息(bbox),如网页元素的边界框、尺寸、位置和层次结构。此外,数据集还包含网页代码文本(text),涵盖HTML和CSS代码,并通过GPT-2分词器生成代码的token长度信息。语言检测模型进一步标注了网页内容的主要语言(lang),支持20种常见语言。神经评分器为每个样本提供了质量评分(score),确保数据的高可靠性。
使用方法
Vision2UI数据集的主要用途是训练和评估多模态大语言模型(MLLMs)在从UI设计图像生成网页代码方面的能力。用户可以通过加载数据集中的parquet文件,获取包含图像、布局信息和代码的并行样本。研究团队还提供了一个基于Vision Transformer(ViT)的基线模型UICoder,以及一种新的评估指标TreeBLEU,用于衡量生成网页与真实代码之间的结构相似性。用户可以通过这些工具验证模型性能,并进一步优化代码生成任务。
背景与挑战
背景概述
Vision2UI数据集,亦称为WebCode2M,是一个专注于从网页设计图像生成代码的真实世界数据集。该数据集由研究人员在2023年推出,旨在解决多模态大语言模型(MLLMs)在自动化UI代码生成领域中的性能瓶颈问题。通过从开源Common Crawl数据集中精心收集、清洗和提炼,Vision2UI提供了超过三百万个包含UI设计图像、网页代码和布局信息的并行样本。该数据集的创建不仅填补了高质量、大规模数据集的空白,还为MLLMs的微调提供了强有力的支持。研究人员还提出了基于Vision Transformer的基线模型UICoder,并引入了新的评估指标TreeBLEU,以衡量生成网页与源代码之间的结构相似性。实验结果表明,Vision2UI显著提升了MLLMs在从UI设计图像生成代码方面的能力。
当前挑战
Vision2UI数据集在解决UI代码生成问题的过程中面临多重挑战。首先,现有MLLMs在缺乏真实、高质量和大规模数据集的情况下表现不佳,导致自动化UI代码生成的精度受限。其次,数据集的构建过程涉及从海量互联网数据中筛选高质量样本,这一过程不仅耗时且复杂,还需依赖神经网络评分器对数据进行精细过滤。此外,尽管数据集经过严格筛选,仍可能包含少量不适当内容,如暴力或色情材料,这对数据集的广泛应用提出了潜在风险。最后,如何有效评估生成网页与源代码之间的结构相似性也是一个技术难点,研究人员为此提出了TreeBLEU指标,但其在实际应用中的效果仍需进一步验证。
常用场景
经典使用场景
VISION2UI数据集在自动化网页代码生成领域展现了其独特的价值。通过结合网页设计图像、布局信息及对应的HTML/CSS代码,该数据集为多模态大语言模型(MLLMs)提供了丰富的训练素材。研究人员可以利用该数据集进行模型微调,以提升模型从UI设计图像生成网页代码的能力。特别是在前端开发领域,该数据集的应用能够显著减少开发者的工作量,提升开发效率。
衍生相关工作
VISION2UI数据集的发布催生了一系列相关研究工作。例如,基于该数据集提出的UICoder模型,结合Vision Transformer(ViT)架构,为自动化UI代码生成提供了新的基线模型。此外,研究人员还利用该数据集探索了多模态学习、代码生成优化等前沿课题,进一步推动了计算机视觉与自然语言处理交叉领域的发展。
数据集最近研究
最新研究方向
在网页设计自动化领域,Vision2UI数据集的推出为多模态大语言模型(MLLMs)在UI代码生成任务中的性能提升提供了重要支持。该数据集通过整合真实场景中的网页设计图像、布局信息及对应的网页代码,构建了一个包含超过三百万并行样本的高质量数据集。近年来,随着前端开发需求的激增,自动化代码生成技术逐渐成为研究热点。Vision2UI不仅填补了现有数据集的空白,还为基于视觉Transformer的模型(如UICoder)提供了基准测试平台。此外,新提出的TreeBLEU指标为评估生成网页与源代码之间的结构相似性提供了量化标准,进一步推动了该领域的技术进步。这一数据集的发布,不仅加速了UI代码生成模型的优化,也为未来智能前端开发工具的研发奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


