Pulaar
收藏Hugging Face2025-12-16 更新2025-12-17 收录
下载链接:
https://huggingface.co/datasets/guizme/Pulaar
下载链接
链接失效反馈官方服务:
资源简介:
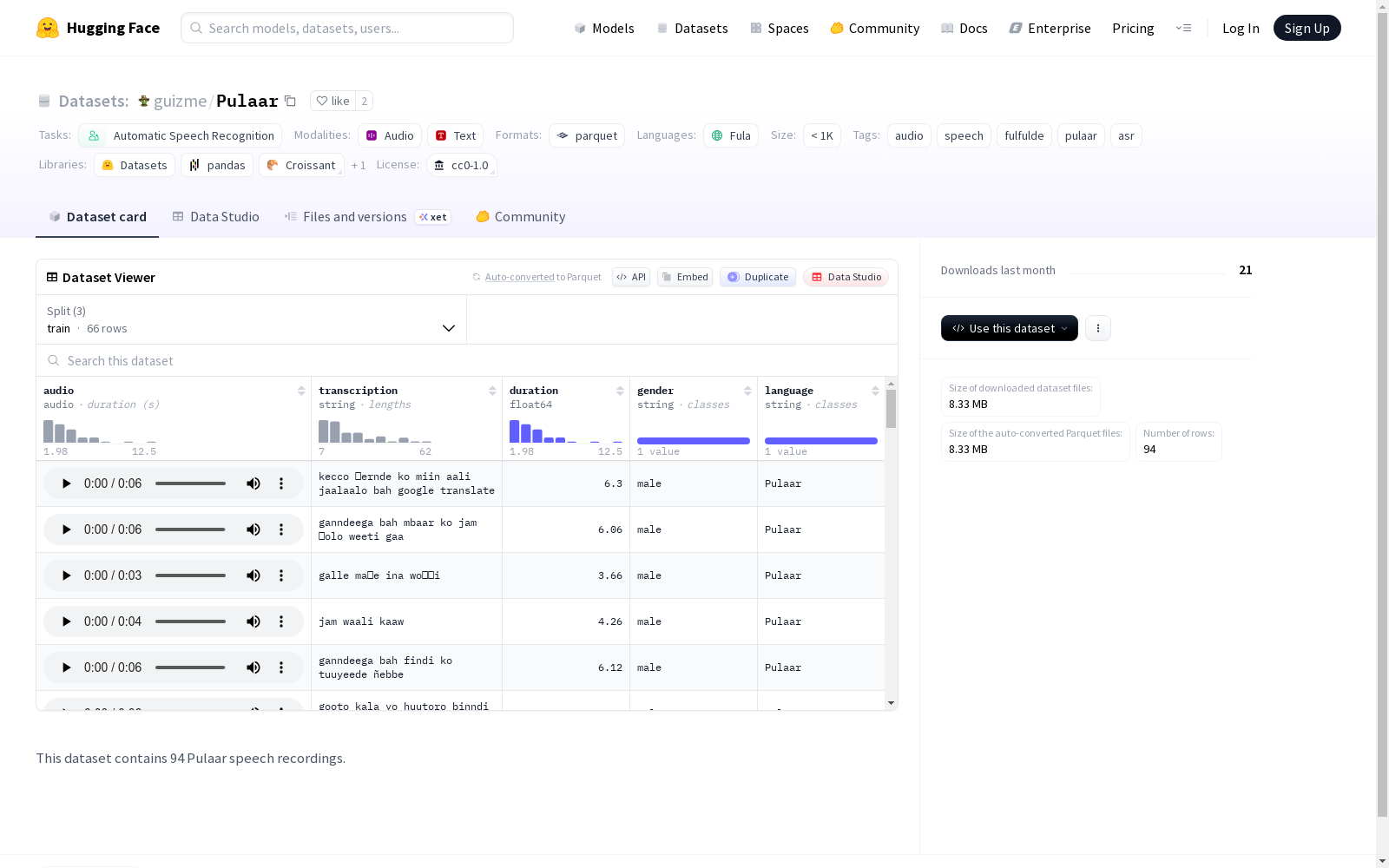
该数据集包含94个Pulaar语音录音,用于自动语音识别任务。数据集是单语的(Fulfulde语言),规模较小(少于1K个样本)。特征包括音频、转录文本、持续时间、性别和语言。数据集分为训练集、验证集和测试集。
创建时间:
2025-12-14
原始信息汇总
数据集概述:Pulaar - Fulfulde
基本信息
- 数据集名称:Pulaar - Fulfulde
- 语言:富拉语(Pulaar/Fulfulde),语言代码:ff
- 多语言性:单语种
- 许可协议:CC0 1.0
- 数据规模类别:n<1K(小于1000个样本)
数据内容与结构
- 总样本量:94个富拉语语音录音
- 数据格式:
audio:音频,采样率为16000 Hztranscription:文本转录,字符串类型duration:音频时长,浮点数类型gender:说话者性别,字符串类型language:语言,字符串类型
- 数据划分:
- 训练集:66个样本,大小约8.66 MB
- 验证集:12个样本,大小约1.47 MB
- 测试集:16个样本,大小约2.27 MB
- 总数据集大小:约12.40 MB
- 下载大小:约8.33 MB
创建信息
- 标注创建者:专家生成
- 语言创建者:众包
任务与标签
- 主要任务类别:自动语音识别
- 标签:audio, speech, fulfulde, pulaar, asr
搜集汇总
数据集介绍
构建方式
在非洲语言资源稀缺的背景下,Pulaar数据集的构建采用了专家生成与群体协作相结合的方式。语言创建者通过众包模式收集了富拉语(Fulfulde)的语音样本,并由专家进行标注,确保了语言数据的准确性与权威性。数据集包含94条语音记录,采样率为16000赫兹,每条记录均配有转录文本、时长、说话者性别及语言标签,并通过训练集、验证集和测试集的划分支持模型开发与评估。
特点
Pulaar数据集作为富拉语语音识别领域的重要资源,其特点体现在语言单一性上,专注于富拉语这一非洲广泛使用的语言变体。数据集规模较小,包含不足千条样本,但提供了高质量的音频特征与详尽的元数据,如说话者性别和录音时长,为研究语音多样性提供了基础。数据以CC0-1.0许可证发布,促进了开放科学合作,适用于自动语音识别任务,并支持多维度分析。
使用方法
在语音技术研究中,Pulaar数据集的使用方法侧重于自动语音识别模型的训练与验证。用户可通过HuggingFace平台直接访问数据文件,按照训练、验证和测试分割加载音频及其转录文本。数据集适用于构建端到端语音识别系统,利用其16000赫兹采样率的音频特征进行特征提取,并结合转录文本进行模型优化。此外,元数据如性别信息可用于偏差分析,推动语言技术的公平性研究。
背景与挑战
背景概述
在低资源语言自动语音识别研究领域,Pulaar数据集作为富拉语(Fulfulde)的语音资源应运而生。该数据集由专家标注与群体协作共同构建,专注于解决非洲富拉语族语言在语音技术中的代表性不足问题。其核心研究目标在于为自动语音识别模型提供高质量的语音-文本配对数据,以推动语言技术在全球语言多样性背景下的均衡发展。尽管规模有限,但该数据集的创建标志着对边缘化语言数字化的初步探索,为后续语言资源建设与跨语言模型迁移研究提供了宝贵的基础。
当前挑战
Pulaar数据集面临的挑战主要体现在领域问题与构建过程两方面。在领域层面,自动语音识别任务需克服低资源语言中语音变体丰富、标注标准缺失以及声学模型适应性不足等障碍。构建过程中,数据采集受限于母语者分布稀疏与技术基础设施薄弱,导致样本规模较小;同时,专家标注依赖语言学家参与,成本高昂且可持续性面临考验。这些因素共同制约了数据集的扩展性与模型训练的泛化能力,凸显了低资源语言技术化进程中资源匮乏与质量保障的双重困境。
常用场景
经典使用场景
在低资源语言自动语音识别研究中,Pulaar数据集作为富拉尼语(Fulfulde)的语音语料库,常被用于训练和评估端到端语音识别模型。研究者利用其包含的94条语音录音及对应转录文本,探索在数据稀缺条件下如何有效提升语音识别系统的性能,特别是在处理非洲语言时面临的音素多样性和声学特征复杂性挑战。
实际应用
在实际应用中,Pulaar数据集可支持开发面向西非地区的语音交互系统,如语音助手、教育工具或医疗信息服务平台。这些系统能够帮助使用富拉尼语的社区跨越数字鸿沟,通过本土语言实现信息获取和技术接入,增强语言包容性并促进社会经济发展。
衍生相关工作
围绕Pulaar数据集,已衍生出多项针对低资源语音识别的经典研究工作,包括基于多任务学习或自监督预训练的模型适应策略。这些工作通常将其与其他非洲语言数据集结合,以探索跨语言表征共享机制,为构建更鲁棒的多语言语音处理框架提供了实证基础。
以上内容由遇见数据集搜集并总结生成


