STRIDE-Bench
收藏Hugging Face2026-05-05 更新2026-05-06 收录
下载链接:
https://huggingface.co/datasets/anonymous1ads34/STRIDE-Bench
下载链接
链接失效反馈官方服务:
资源简介:
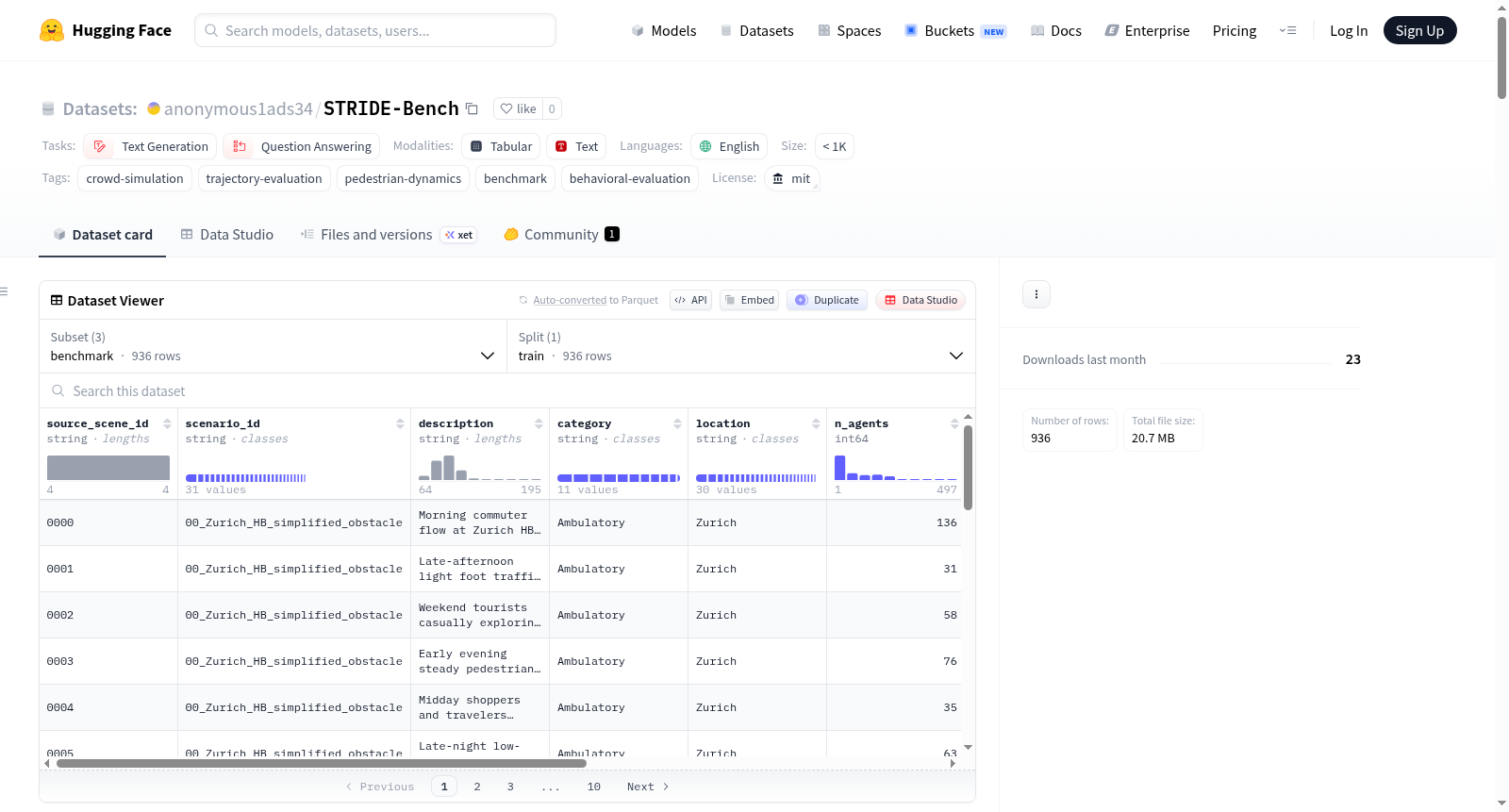
STRIDE Benchmark 是一个用于评估人群轨迹生成和模拟模型行为真实性的基准数据集。不同于逐点比较轨迹,该数据集通过分解的行为问题评估生成的轨迹是否与给定场景描述一致,从而测量轨迹与上下文的一致性。数据集包含三个文件:benchmark.jsonl(行为评估规范)、scenes.parquet(场景元数据和初始状态)、maps.parquet(每场景的障碍物数据)。数据集涵盖936个场景,6,633个问题,11,696个测量,22个评估函数,11种行为类别,31个独特场景和30个真实世界位置。适用于模型比较、类别级分析和轨迹问答(STRIDE)等任务。
STRIDE Benchmark is a benchmark dataset for evaluating the behavioral realism of crowd trajectory generation and simulation models. Unlike point-by-point trajectory comparisons, this dataset evaluates whether generated trajectories are consistent with given scene descriptions by decomposing behavioral questions, thereby measuring the consistency of trajectories with context. The dataset contains three files: benchmark.jsonl (behavioral evaluation specifications), scenes.parquet (scene metadata and initial states), and maps.parquet (obstacle data for each scene). The dataset covers 936 scenes, 6,633 questions, 11,696 measurements, 22 evaluation functions, 11 behavior categories, 31 unique scenes, and 30 real-world locations. It is suitable for tasks such as model comparison, category-level analysis, and trajectory question answering (STRIDE).
创建时间:
2026-05-02
原始信息汇总
STRIDE-Bench 数据集概述
基本信息
- 数据集名称:STRIDE-Bench
- 许可协议:MIT
- 语言:英语
- 任务类别:文本生成、问答
- 数据集规模:1,000 至 10,000 条数据
- 标签:人群仿真、轨迹评估、行人动力学、基准测试、行为评估
数据集描述
STRIDE-Bench 是一个用于评估人群轨迹生成和仿真模型行为真实性的基准数据集。它不进行逐点轨迹比较,而是通过分解的行为问题评估生成轨迹是否与给定场景描述一致,衡量轨迹-上下文一致性。
数据集组成
数据集包含三个部分,所有部分按场景对齐:
| 文件 | 格式 | 行数 | 用途 |
|---|---|---|---|
benchmark.jsonl |
JSON Lines | 936 | 行为评估规范(每个场景的问题和测量) |
scenes.parquet |
Parquet | 936 | 场景元数据、初始智能体状态、群体结构、目标 |
maps.parquet |
Parquet | 936 | 每个场景的障碍物矩形和渲染的障碍物 PNG |
关键统计数据
| 属性 | 数值 |
|---|---|
| 场景数 | 936 |
| 总问题数 | 6,633 |
| 总测量数 | 11,696 |
| 评估函数数量 | 22 |
| 行为类别数量 | 11 |
| 独特场景数量 | 31 |
| 真实世界地点数量 | 30 |
数据结构
benchmark.jsonl — 行为评估规范
每行代表一个场景,包含以下字段:
source_scene_id(字符串):场景唯一标识符scenario_id(字符串):物理场景/环境引用description(字符串):人群行为场景的自然语言描述category(字符串):行为类别标签(共11种)location(字符串):真实世界地点名称decomposition_reasoning(字符串):LLM推理,说明描述如何映射到可测量的行为属性questions(列表):行为评估问题,每个问题包含:id(字符串):问题标识符question(字符串):自然语言行为问题measurements(列表):回答问题的定量测量:function(字符串):评估函数名称params(对象):函数参数expected_result(对象):期望值范围(含min和/或max边界)expected_result_reasoning(字符串):期望范围的推理delta_value(数字):软评估的容忍度/余量
_model(字符串):用于生成基准的LLM_n_scenes(整数):数据集中的总场景数
scenes.parquet — 场景状态和元数据
每行一个场景,包含列(部分):
scene_id(字符串):场景标识符scene_index(整数):场景数值索引scenario(字符串):场景自由形式描述category(字符串):行为类别标签crowd_size/crowd_size_label:智能体数量和分桶标签ungrouped_agents(整数):未分组的智能体数量event_center_px/event_center_m:事件中心的像素和米坐标initial_state:每个智能体的起始状态groups:智能体分组信息towards_event/towards_goal:智能体是否朝向事件/目标移动desired_speed_range等字段:模拟中使用的期望行为范围goal_location_raw等字段:目标规格
maps.parquet — 每个场景的障碍物数据
每行一个场景,包含列:
scene_id(字符串):场景标识符obstacles_key(字符串):原始npz键(始终为"obstacles")obstacles:障碍物矩形,形状为(N, 4)obstacles_shape:原始数组形状obstacle_map_png:渲染障碍物地图的原始PNG字节
行为类别
| 类别 | 数量 | 描述 |
|---|---|---|
| 逃离 | 123 | 紧急/疏散行为 |
| 暴力 | 122 | 冲突场景 |
| 示威者 | 106 | 有组织的团体/抗议运动 |
| 密集 | 103 | 高密度人群运动 |
| 攻击性 | 89 | 攻击性人群行为 |
| 冲撞 | 85 | 快速移动 |
| 表达性 | 76 | 情绪化/表达性运动 |
| 参与性 | 75 | 基于事件的/交互式 |
| 凝聚性 | 67 | 群体行走行为 |
| 步行 | 58 | 正常行走/通勤 |
| 残疾 | 32 | 行动受限的移动 |
评估函数(共20个)
V-速度类:
mean_speed— 平均步行速度(m/s)speed_variation_coeff— 速度异质性(变异系数)
R-真实性类:
collision_fraction— 近碰撞事件比例lingering_fraction— 缓慢/静止智能体比例
D-方向类:
flow_alignment— 移动方向对齐度(0-1)path_linearity— 路径直度(0-1)directional_entropy_normalized— 方向多样性(0-1)
S-空间类:
spatial_concentration— 非均匀空间分布(基于基尼系数,0-1)mean_local_density— 自适应半径内的平均邻居数peak_local_density— 最大局部密度(热点强度)dispersal_score— 与初始中心的径向分散度convergence_score— 向最终中心的内向收敛度
T-时间类:
clustering_trend— 群体形成动态lingering_trend— 智能体随时间停止/移动的趋势entropy_trend— 随时间变化的运动组织度vs混乱度speed_trend— 时间加速/减速模式density_trend— 人群随时间聚集或分散的趋势collision_trend— 碰撞升级/解决趋势flow_alignment_trend— 运动变得有序或混乱的趋势
使用方式
通过Hugging Face Datasets库加载:
python from datasets import load_dataset
REPO = "anonymous1ads34/STRIDE-Bench"
benchmark = load_dataset(REPO, "benchmark", split="train") scenes = load_dataset(REPO, "scenes", split="train") maps = load_dataset(REPO, "maps", split="train")
三个配置的行是对齐的,可以通过scene_id或source_scene_id进行连接。
预期用途
该基准设计用于评估人群轨迹生成模型,通过测量模型输出在给定文本场景描述下是否表现出一致的行为运动模式。支持:
- 模型比较:根据行为真实性对不同场景下的轨迹生成器进行排名
- 类别级分析:识别模型在每个行为类型下的优势/弱点
- 轨迹问答:将轨迹评估构建为QA任务
评估协议
对每个模型和场景:
- 根据场景描述生成/模拟轨迹
- 在生成的轨迹上执行评估函数
- 将实际函数输出与期望范围(含delta_value容忍度)进行比较
- 计算每个问题的通过/失败,汇总STRIDE准确率
轨迹格式
模型应生成形状为(时间步, 智能体数, 7)的轨迹数组,列顺序为:[x, y, vx, vy, goal_x, goal_y, radius]。
局限性
- 期望值范围由LLM估计,可能与所有真实场景实例不完全匹配
- 基准侧重于聚合行为统计,而非个体轨迹合理性
- 位置几何(障碍物、边界)已从真实环境简化
搜集汇总
数据集介绍
构建方式
STRIDE-Bench的构建基于对真实世界场景的细致解构与语义抽象。研究团队首先从30个实际地理位置中提炼出31种典型人群行为场景,涵盖通勤、聚集、疏散等多元情境。随后,利用大语言模型为每个场景生成自然语言描述,并结合行为推理将其分解为可量化的观测问题与测量指标。每个场景对应约7个行为问题及平均12个定量测量,通过22个评估函数从速度、方向、空间分布、时间动态及碰撞交互等维度刻画人群运动特征。最终形成包含936个场景、6633个问题及11696个测量的结构化基准数据集,所有数据通过场景标识符实现三个子文件间的精确对齐。
特点
该基准数据集的核心特点在于其基于行为的评估范式,区别于传统轨迹逐点对比方法,转而衡量生成轨迹与场景描述之间的行为一致性。数据覆盖11类人群行为范畴,从正常步行到紧急疏散,从群体凝聚力到暴力冲突,构建了多层次的行为评估体系。每个行为问题都配备定量期望值范围与容差参数,形成软性评估机制。此外,数据集提供完整的环境障碍物数据与初始代理状态,支持端到端的仿真评估。其创新性还体现在将轨迹评估转化为问题解答任务,通过测量轨迹是否“回答”行为问题来评判生成模型的逼真度,为人群仿真领域提供了更符合认知科学的评价标准。
使用方法
研究者可通过HuggingFace Datasets库加载三个配置子集:benchmark.jsonl包含行为评估规范,scenes.parquet存储场景元数据与代理初始状态,maps.parquet提供障碍物几何信息。使用load_dataset函数指定仓库名称与配置名即可获取对应数据,各行按场景ID对齐并联通。评估流程为:首先基于场景描述生成或仿真人群轨迹,要求输出形状为(时间步数, 代理数, 7)的张量,包含位置、速度、目标与半径信息。接着对生成轨迹执行22个评估函数,获得实际测量值,再与预先定义的期望范围及容差进行对比,逐问题判定通过与否。最终汇总各场景的通过率,形成STRIDE准确率指标,支持模型间排名、行为类别分析及轨迹问题解答等多元评估任务。
背景与挑战
背景概述
STRIDE-Bench数据集由匿名研究团队于近期构建,旨在评估人群轨迹生成与仿真模型的行为真实度。该数据集摒弃了传统的逐点轨迹对比方法,转而通过分解行为问题来度量生成轨迹与给定场景描述之间的一致性,即轨迹-上下文一致性。研究涵盖31种独特场景与30个真实世界地点,包含936个场景、6633个行为问题及11696项测量指标,横跨逃离、暴力、示威等11种行为类别。这一创新基准为人群动力学与仿真领域的模型比较、行为类别分析及轨迹问答任务提供了标准化评估框架,显著推动了群体行为建模从几何准确性向行为语义真实性的范式转变。
当前挑战
STRIDE-Bench数据集所应对的核心领域挑战在于传统轨迹评估方法仅关注点对点位置误差,无法捕捉群体行为的语义合理性,如人群在疏散或冲突场景中的运动模式是否合乎现实。构建过程中,挑战包括:如何将自然语言描述的场景行为准确映射为可量化的测量函数与预期参数范围;如何平衡11种行为类别间的样本分布,尤其是残障人群等低频场景的数据采集;以及如何简化真实环境的几何障碍信息以保证仿真效率,同时避免过度抽象导致的评估偏差。此外,LLM生成的预期值范围需经专家校准以提升可靠性,进一步增加了数据集构建的复杂性。
常用场景
经典使用场景
STRIDE-Bench的核心价值在于评估群体轨迹生成与仿真模型的行为真实性。不同于传统的逐点轨迹对比方法,该数据集通过解构场景描述为一系列可量化的行为问题,评估生成轨迹与给定情境之间的语义一致性。研究者可借助其包含的936个场景、22个评估函数及11类行为标签,系统性地比较不同模型在疏散、示威、密集流动等多种人群动态中的表现。数据集提供的三项对齐文件——行为评估规范、场景元数据和障碍物地图——使研究人员能够从速度分布、碰撞频率、方向对齐、空间聚集性等多个维度,对模型生成轨迹的上下文合理性进行细粒度诊断。这种以行为问题驱动的评估框架,为群体仿真领域建立了一种全新的、语义丰富的标准化评价范式。
衍生相关工作
STRIDE-Bench的发布催生了一系列开创性的后续研究。基于其基于问题的评估范式,研究者开发了STRIDE(轨迹问答)框架,将轨迹评估重新定义为一项问答任务,开创了群体行为理解的新视角。在模型层面,该数据集激发了对情境感知轨迹生成模型的探索,促使研究人员将场景描述作为条件信息融入扩散模型或Transformer架构中。此外,针对数据集明确指出LLM估计的期望值范围可能存在的局限性,相关工作开始探索如何利用逆强化学习从真实轨迹中自动推导更为精确的行为约束条件。这些衍生工作共同推动着群体仿真领域向更加语义化、可解释和与现实世界高度一致的方向演进。
数据集最近研究
最新研究方向
STRIDE-Bench标志着群体仿真评估范式的根本性变革,它摒弃了传统逐点轨迹对比的局限性,开创性地引入了轨迹-上下文一致性(trajectory-context consistency)度量框架。该数据集将复杂群体行为分解为22项可量化的评估函数,覆盖速度、方向、空间聚集、时间动态等11个行为维度,为评估生成轨迹的行为真实性提供了严谨的数学基础。在当前大语言模型与物理仿真深度融合的前沿交叉领域,STRIDE-Bench通过将自然语言场景描述转化为结构化的行为问题集,开创了轨迹问答(Trajectory QA)这一新兴评估范式。其936个精心设计的场景数据,涵盖从紧急疏散到残障人群移动等极端复杂社会情境,为破解群体智能仿真长期面临的“行为逼真度”瓶颈提供了标准化测评工具,对智慧城市应急管理、虚拟现实人机交互等热点领域具有重要推动价值。
以上内容由遇见数据集搜集并总结生成


