WithinUsAI/Opus4.7_thinking_max_distill_god_seed_25k
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/WithinUsAI/Opus4.7_thinking_max_distill_god_seed_25k
下载链接
链接失效反馈官方服务:
资源简介:
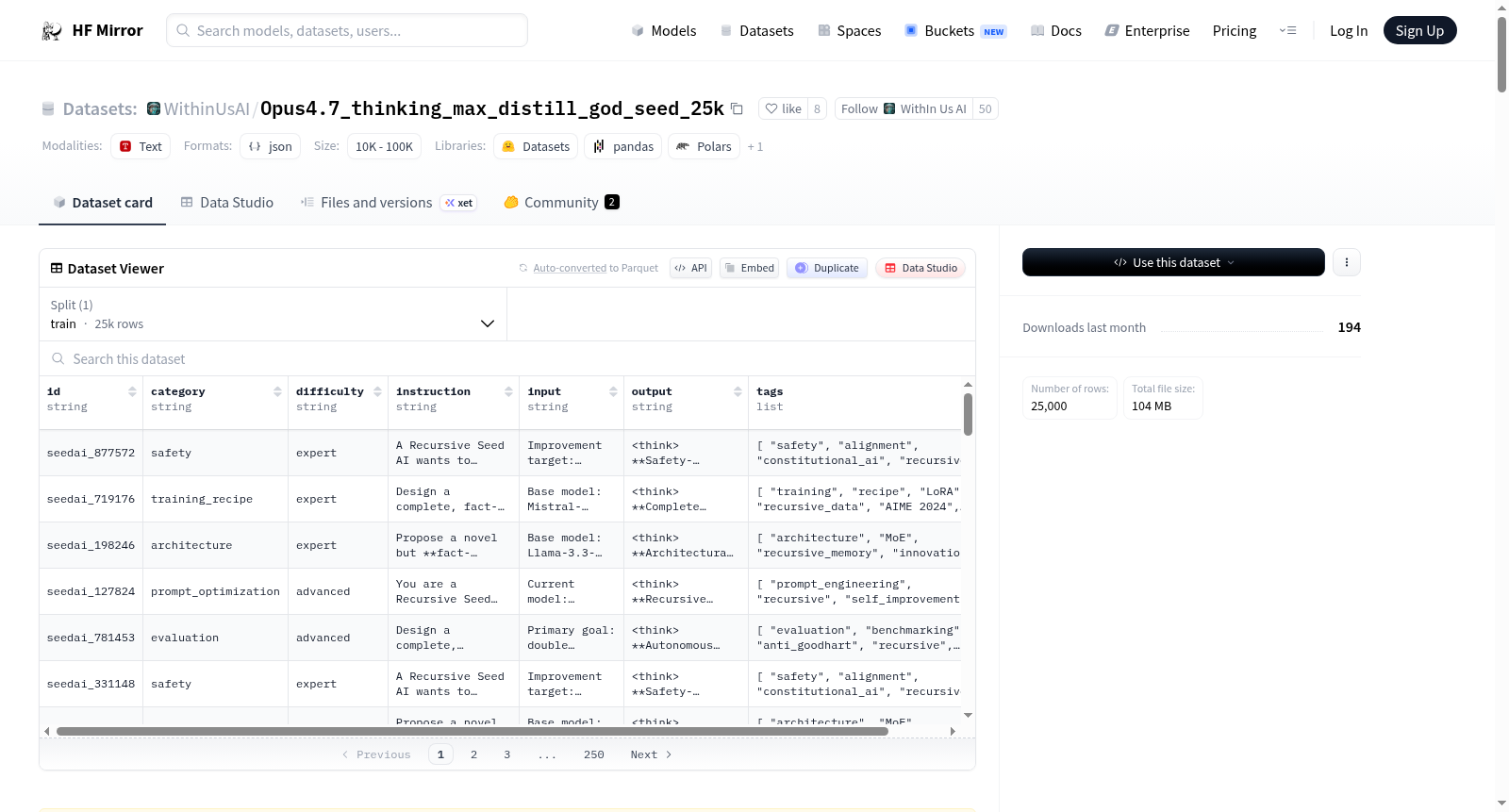
Opus4.7_thinking_max_distill_god_seed_25k是一个合成推理数据集,旨在训练模型进行递归自我改进、认知推理和结构化认知工作流程。每个样本模拟一个递归种子AI任务,要求模型分析系统或能力、设计改进、强制执行严格约束(如对齐性、安全性、可审计性),并产生结构化的多步推理。与标准指令数据集不同,该数据集强调模型如何思考,而不仅仅是输出什么。数据集包含约25,000行训练数据,采用JSONL格式,并包含结构化推理痕迹。它适用于监督微调、推理蒸馏、思维链训练等多种任务,特别适合训练具有递归/自我改进系统的AI模型。
Opus4.7_thinking_max_distill_god_seed_25k is a synthetic reasoning dataset designed to train models in recursive self-improvement, epistemic reasoning, and structured cognitive workflows. Each sample simulates a Recursive Seed AI task, where the model must analyze a system or capability, design improvements, enforce strict constraints (alignment, safety, auditability), and produce structured, multi-step reasoning. Unlike standard instruction datasets, this dataset emphasizes how a model thinks, not just what it outputs. The dataset contains ~25,000 rows of training data in JSONL format with structured reasoning traces. It is suitable for tasks such as Supervised Fine-Tuning, Reasoning Distillation, and Chain-of-Thought Training, especially for training AI models with recursive/self-improving systems.
提供机构:
WithinUsAI
搜集汇总
数据集介绍
构建方式
Opus4.7_thinking_max_distill_god_seed_25k是一个完全通过合成方式生成的高密度递归推理数据集。其构建过程依托于先进的思维最大化(thinking-max)风格生成策略,通过精心设计的推理提示词、递归任务框架以及严格的约束条件,引导模型产出结构化的多步推理内容。数据在生成后进一步经过蒸馏处理,确保每条样本包含明确的<think>推理痕迹,从而捕捉模型在决策过程中的认知流转,而非仅仅关注最终输出结果。整体采用JSONL格式,包含约25,000条训练样本,每条记录均配备唯一标识符、任务类别、难度等级、指令、输入约束与上下文、结构化输出以及语义标签,形成了高度一致且可复现的数据结构。
使用方法
该数据集最适合用于3B至70B参数规模语言模型的完整微调,尤其是专注于推理能力强化、智能体系统开发及递归学习的研究场景。可应用于监督微调、推理蒸馏、思维链训练、智能体工作流训练、自我反思建模、对齐安全训练及元学习等多种任务。使用时需注意,数据中包含的<think>推理痕迹可根据具体需求选择保留或过滤,以适配不同的训练策略。建议采用适当的训练方案以充分释放数据集在结构化多步推理和约束感知建模方面的全部价值,同时需留意合成数据可能带来的过于结构化输出的偏差。
背景与挑战
背景概述
Opus4.7_thinking_max_distill_god_seed_25k是由WithIn Us AI团队于2026年发布的高密度递归推理与自我改进数据集,旨在突破传统大型语言模型‘输出正确性’的局限,转向训练模型的结构化认知流程与约束感知决策过程。该数据集聚焦于递归自我改进推理、安全约束优化及认识论验证等前沿主题,通过合成生成的逻辑轨迹(<think>痕迹)模拟‘思考优先’的智能体工作流,为3B至70B参数规模的模型微调提供了全新范式。其对自主评估设计、元学习及对齐训练的强调,深刻影响了AI安全与负责任智能体系统的研究方向。
当前挑战
该数据集所解决的领域核心挑战在于,当前多数指令数据集仅训练模型‘给出答案’,而无法确保答案产生的过程长期稳健且符合安全约束。Opus4.7_thinking_max_distill_god_seed_25k直面模型在递归自我改进中易陷入奖励黑客、古德哈特定律等陷阱的难题,并尝试通过约束感知的推理训练构建可审核的自治系统。其构建挑战在于:依赖合成生成逻辑轨迹可能引入过度结构化偏差,导致模型泛化至真实世界日志时失效;同时,25k条专家级样本的设计需精心平衡推理深度与训练有效性,以避免数据冗余或认知模式固化,这对生成策略中的递归任务框架与输出强制格式提出了更高要求。
常用场景
经典使用场景
在自然语言处理与人工智能研究的前沿领域,Opus4.7_thinking_max_distill_god_seed_25k 数据集被精心设计用于训练具备递归自改进能力与深度推理思维的先进语言模型。其最经典的使用场景涵盖监督微调、推理蒸馏以及思维链训练,尤其适用于增强模型在复杂约束条件下的结构化多步推理能力。该数据集通过提供包含显式思考痕迹(<think> 标签)的合成样本,引导模型从被动响应转向主动建构思考过程,从而在多轮任务中展现出持续的自我优化与安全意识。
解决学术问题
该数据集致力于攻克人工智能领域的关键学术难题,即如何使语言模型超越简单应答,具备递归自改进、认知验证以及约束感知的思考能力。它有效解决了传统数据集忽视的‘思考过程’训练不足问题,使模型能够在安全约束、可审计性与性能优化之间取得平衡。其影响深远,为对齐科学、元学习与自主智能体研究提供了扎实的推理基础,推动了从‘回答正确’到‘设计能够长期保证正确性的系统’这一范式转换。
实际应用
在实际应用层面,该数据集展现出显著的实用价值,尤其适用于构建需要深度推理与自适应行为的智能系统。例如,在自动化提示工程中,模型可利用递归循环进行进化式指令优化;在训练框架中,它帮助模型设计包含超参数、数据混合与计算预算的完整训练管线;此外,它还支持自主评估系统的构建,使其能够抵御古德哈特定律与奖励黑客行为,确保评估的真实性。这些应用场景共同促进了从实验室研究到工业部署的平滑迁移。
数据集最近研究
最新研究方向
Opus4.7_thinking_max_distill_god_seed_25k数据集聚焦于递归自改进推理与安全约束优化,代表了大型语言模型训练从“输出答案”向“构建思维过程”的前沿转型。该合成推理数据集通过模拟递归种子AI任务,强化模型在安全对齐、可审计性约束下的多步结构推理能力,为探索自主AI系统中的自我反思、元学习与评估框架设计提供了关键资源。其强调的“思考优先”训练范式与约束感知优化,正成为推动对齐研究、防止奖励黑客行为及构建可验证智能系统的重要方向。
以上内容由遇见数据集搜集并总结生成


