FineMotion
收藏arXiv2025-07-26 更新2025-08-13 收录
下载链接:
https://github.com/BizhuWu/FineMotion
下载链接
链接失效反馈官方服务:
资源简介:
FineMotion数据集是一个包含超过442,000个人类运动片段及其对应详细描述的人体部分运动的数据集。该数据集旨在解决现有文本-运动数据集中描述过于粗糙,缺乏细节的问题。数据集包含约95k个详细段落描述整个人体运动序列的运动。数据集的构建过程包括自动生成和人工标注两个阶段,并且支持零样本细粒度运动编辑,使用户能够通过文本修改来调整运动内容。
The FineMotion Dataset is a human motion dataset comprising over 442,000 human motion clips paired with their corresponding detailed descriptions of partial human body movements. This dataset aims to address the issue that existing text-motion datasets suffer from overly coarse descriptions and a lack of fine-grained details. It includes approximately 95,000 detailed paragraphs that describe full human motion sequences. The construction of the dataset consists of two stages: automatic generation and manual annotation. Moreover, it supports zero-shot fine-grained motion editing, enabling users to adjust motion content via textual modifications.
提供机构:
深圳大学计算机科学与软件工程学院, 英国诺丁汉大学宁波校区计算机科学学院, 深圳大学人工智能学院计算机视觉研究所, 广东省智能信息处理重点实验室, 新加坡国立大学, 孙中山大学深圳校区, 英国诺丁汉大学计算机科学学院
创建时间:
2025-07-26
搜集汇总
数据集介绍
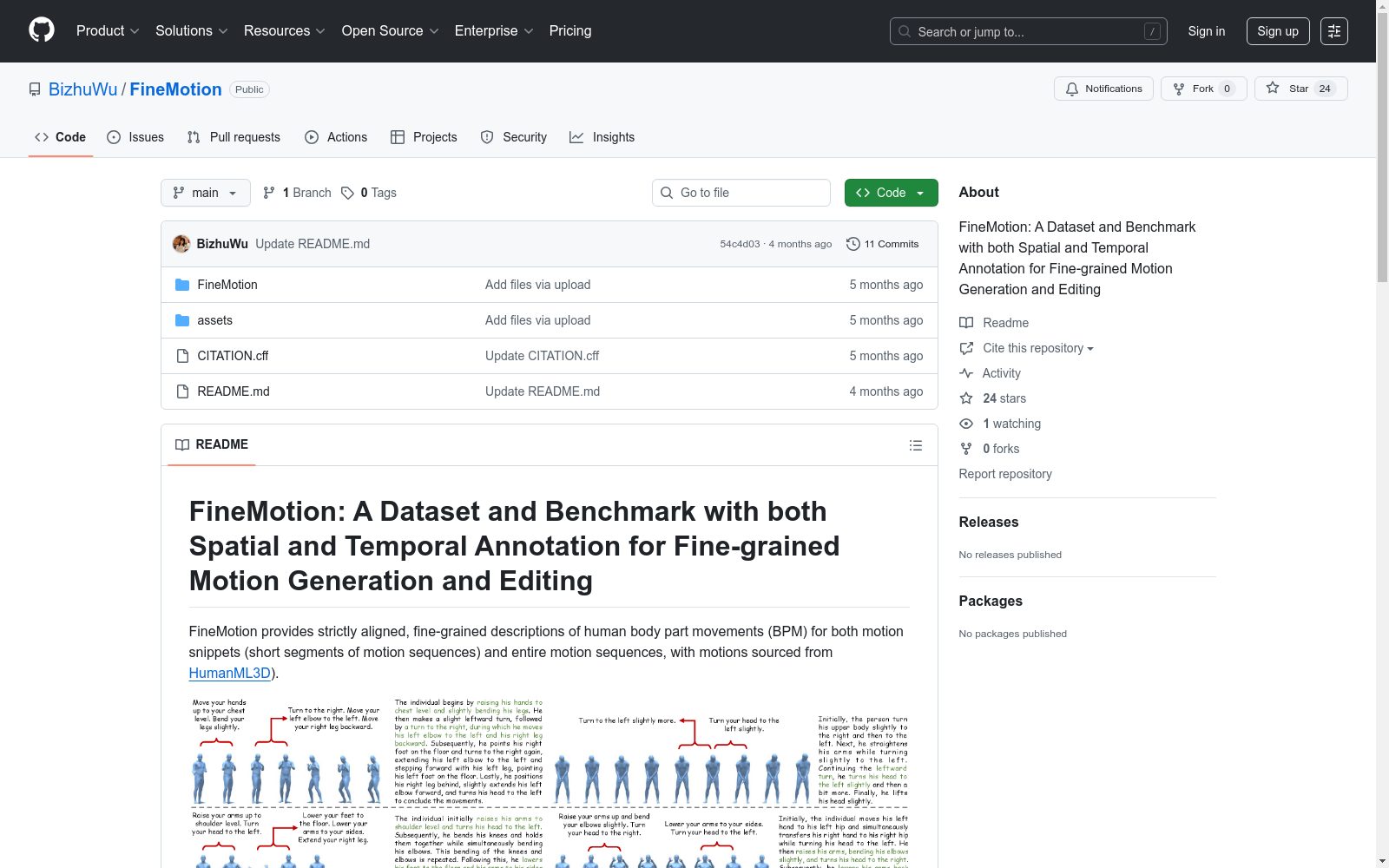
构建方式
FineMotion数据集的构建采用了高效且可扩展的自动化标注流程,结合人工校验以确保数据质量。首先,将运动序列沿时间维度分割为短片段(0.5秒/段),通过PoseFix校正模型生成肢体部位运动描述(BPMSD)。随后利用Gemini大语言模型将片段描述整合为连贯段落(BPMP),并通过8名标注员对5%的数据进行人工修正,最终形成包含442,314个片段描述和94,432个段落描述的大规模数据集。
特点
该数据集的核心特征体现在三维度精细标注:空间上提供21个主要关节的位移描述,时间上以0.5秒为最小单元标注动作起止,语义层面则通过双层描述体系(BPMSD+BPMP)实现动作分解与全局语义的统一。其标注词汇量达2,200词项,段落平均长度247词,较传统数据集(如HumanML3D)的标注密度提升15倍,且通过BERTScore 0.89验证了自动生成与人工标注的高度一致性。
使用方法
使用该数据集需遵循三阶段流程:预处理阶段需将SMPL姿态参数归一化为20FPS的263维特征;训练阶段建议采用T5-Base文本编码器处理长文本,并通过均值池化获得768维嵌入;推理阶段支持两种模式——可直接输入精细描述生成动作,或通过零样本编辑管道实现时空维度修改。基准测试表明,结合粗粒度文本输入时,Top-3检索准确率可提升15.3%。
背景与挑战
背景概述
FineMotion数据集由深圳大学、诺丁汉大学宁波校区、新加坡国立大学等机构的研究团队于2024年联合推出,旨在解决细粒度人体运动生成与编辑中的时空对齐问题。该数据集基于HumanML3D和AMASS等现有运动捕捉数据,通过创新的自动标注流程,构建了包含442,000个运动片段和95,000个完整运动序列的精细标注。其核心突破在于同时提供空间维度(具体身体部位动作)和时间维度(精确到0.5秒间隔)的双重标注,显著提升了文本驱动运动生成的精确度,在MDM模型上实现了Top-3准确率15.3%的提升。
当前挑战
该数据集主要应对两大挑战:领域层面,传统文本-运动数据集(如HumanML3D)的粗粒度描述无法满足对肢体动作时序控制的精细需求;构建层面,需突破LLM增强文本与实际运动序列的错位问题。具体挑战包括:1)设计可扩展的自动标注流程以处理海量运动片段;2)确保生成的肢体动作描述与运动序列严格时空对齐;3)开发支持零样本细粒度编辑的基准模型,需平衡运动多样性与控制精度。构建过程中还需解决固定时间片段划分与运动连续性保持的平衡问题,以及人工校验与自动生成的标注质量一致性难题。
常用场景
经典使用场景
在计算机视觉与动作生成领域,FineMotion数据集通过精确标注人体部位运动的时空信息,为细粒度动作生成任务提供了关键支持。其经典使用场景包括基于文本描述生成高保真人体动作序列,例如在虚拟角色动画制作中,模型可根据"右臂以每秒30度角抬起并保持2秒"等详细指令生成连贯动作。数据集包含的44.2万条动作片段描述和9.5万条完整序列段落,使得生成的动作能精确匹配文本描述的时空要求。
解决学术问题
该数据集有效解决了动作生成领域三个核心问题:传统文本描述缺乏时空精度导致的动作模糊性,通过0.5秒间隔的片段级标注实现时序对齐;大语言模型增强文本与真实动作的偏差问题,采用自动生成与人工校验结合的标注流程确保描述准确性;动作编辑任务中局部调整困难的问题,支持通过修改特定身体部位描述实现零样本编辑。实验表明,采用该数据集使MDM模型的Top-3检索准确率提升15.3%,证明了细粒度标注对提升动作生成质量的关键作用。
衍生相关工作
该数据集催生了多项创新研究:MotionGPT将动作序列视为特殊语言进行跨模态生成;FineMoGen提出分层量化方法处理细粒度动作token;T2M-GPT的改进版本通过双文本编码器融合全局语义与局部细节。相关工作中,(T&DT)-MoMask模型利用该数据集实现81.3%的Top-3检索准确率,创下当前细粒度动作生成的最佳性能。这些衍生研究共同推动了文本驱动动作生成向影视级精度发展。
以上内容由遇见数据集搜集并总结生成


