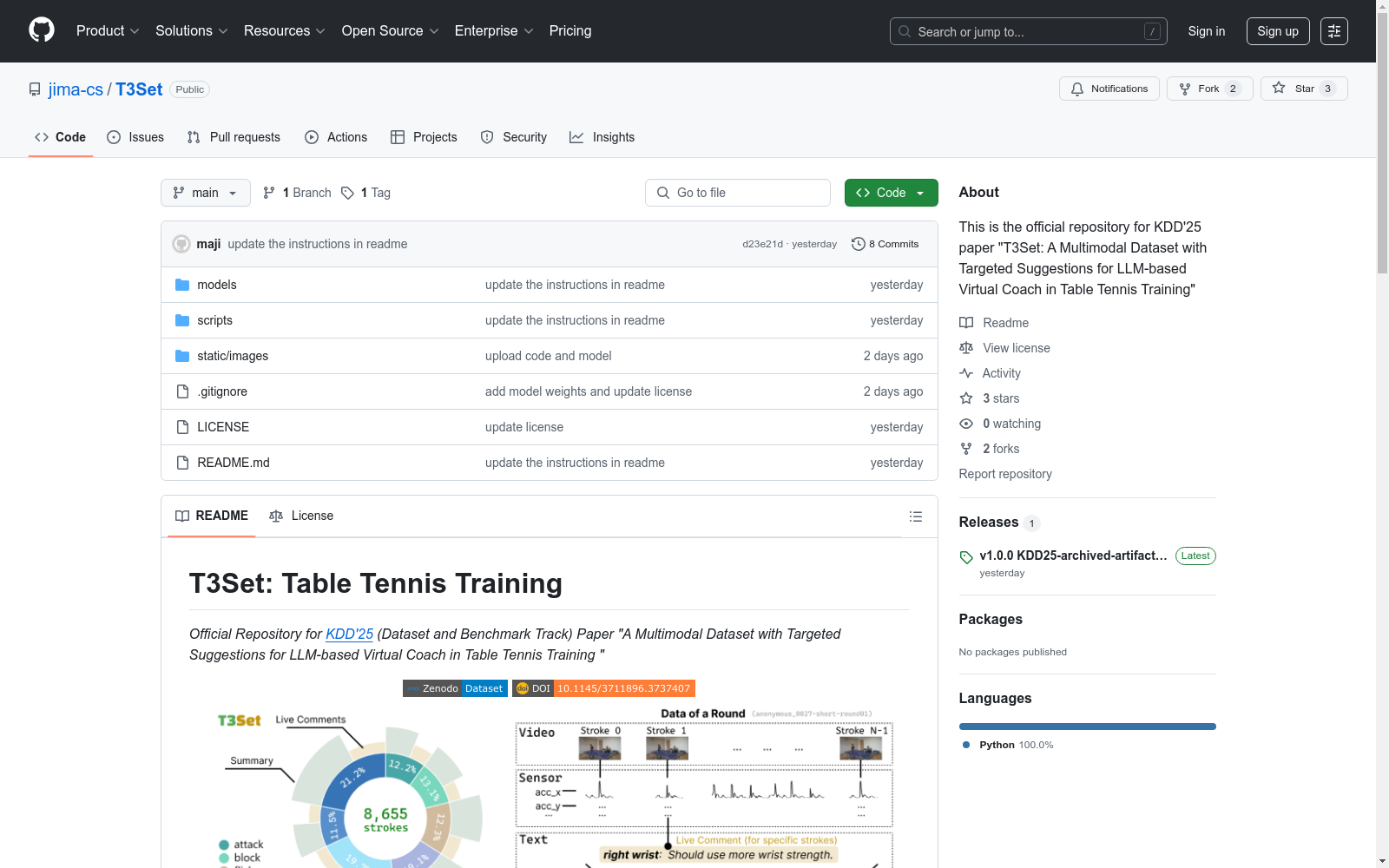
T3Set
收藏T3Set数据集概述
🌟 数据集简介
T3Set(Table Tennis Training)是一个多模态数据集,包含乒乓球训练中对齐的视频-传感器-文本数据,专为基于LLM的虚拟教练研究设计。
🔑 关键特性
- 传感器数据(IMU)、多角度视频和专业教练文本之间的时间对齐
- 遵循预定义建议分类法的高质量针对性建议
📊 数据统计
| 维度 | 详情 |
|---|---|
| 参与者 | 32名业余选手 |
| 训练轮次 | 380轮多球训练 |
| 击球动作 | 8,655个标记击球 |
| 技术类型 | 7种常见技术(上旋球、挡球等) |
| 针对性建议 | 8,395条教练建议 |
| 模态数据 | - 视频:1080p@60fps,双摄像头<br>- 传感器:9轴IMU(100Hz采样)<br>- 音频:教练音频和文本 |
📦 数据获取
数据集公开于Zenodo平台:
- 访问链接:https://zenodo.org/records/15516144
- 永久DOI链接:https://doi.org/10.5281/zenodo.15516143
⚠️ 伦理声明
- 所有参与者均签署了开源使用知情同意书
- 实验流程通过实验室伦理审查委员会批准
💻 模型与脚本
目录结构
T3Set/ ├─ models/ # 验证数据集使用的简单模型 │ ├─ src/ # 源代码 │ ├─ weights/ # 预训练权重 │ ├─ requirements.txt # 所需包 │ └─ README.md # 使用说明 ├─ scripts/ # 数据处理和评估脚本 │ ├─ data_scripts/ # 数据集构建脚本(击球检测、数据对齐、文本预处理) │ └─ eval_scripts/ # 基准测试脚本 ├─ README.md # 项目概述 └─ LICENSE # 许可信息
📖 引用
如需使用本数据集,请引用: bibtex @inproceedings{ ma2025t3set, title={T3Set: A Multimodal Dataset with Targeted Suggestions for LLM-based Virtual Coach in Table Tennis Training}, author={Ji Ma and Jiale Wu and Haoyu Wang and Yanze Zhang and Xiao Xie and Zheng Zhou and Jiachen Wang and Yingcai Wu}, year={2025}, booktitle={Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2}, doi={10.1145/3711896.3737407} pages={} }
📢 联系方式
如有问题或合作意向,请联系:
- Ji Ma: zjumaji@zju.edu.cn