OGB/ogbg-molpcba
收藏Hugging Face2023-02-07 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/OGB/ogbg-molpcba
下载链接
链接失效反馈官方服务:
资源简介:
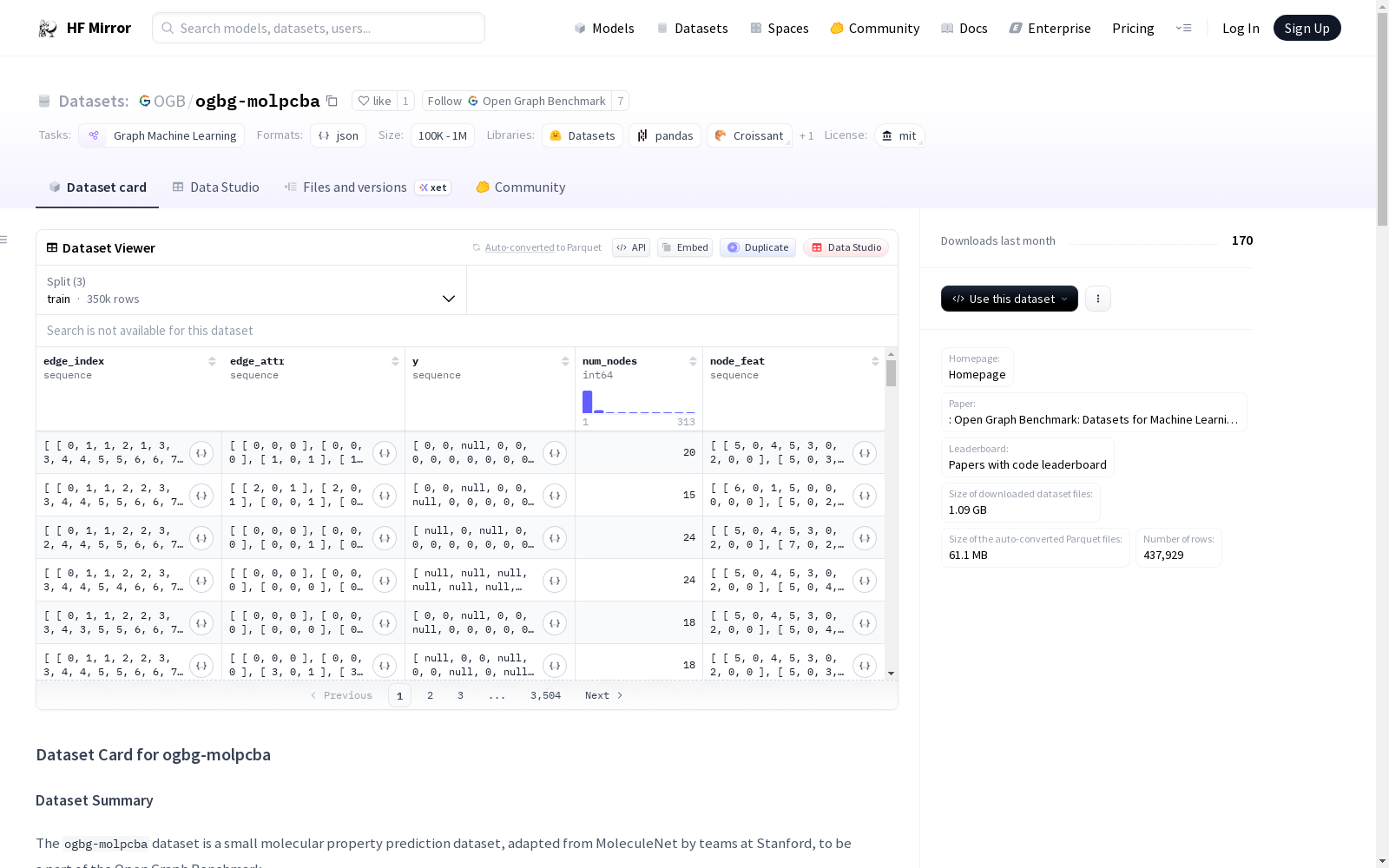
`ogbg-molpcba`数据集是一个用于分子属性预测的小型数据集,源自MoleculeNet,并由斯坦福团队改编为Open Graph Benchmark的一部分。数据集包含437,929个图,每个图平均有26个节点和28.1条边。数据集支持的任务是分子属性预测,具体为二分类任务,涉及128个属性。数据集的评分标准是任务的平均精度(AP)。数据集的结构包括节点特征、边索引、边属性、标签和节点数量等字段。数据集的使用可以通过PyGeometric库进行加载。
The `ogbg-molpcba` dataset is a small-scale dataset for molecular property prediction, originally derived from MoleculeNet and adapted by the Stanford team as part of the Open Graph Benchmark. It contains 437,929 graphs, with each graph averaging 26 nodes and 28.1 edges. The supported task of this dataset is molecular property prediction, specifically binary classification tasks involving 128 attributes. The evaluation metric for the dataset is the average precision (AP) across tasks. The dataset structure includes fields such as node features, edge indices, edge attributes, labels, and the number of nodes. The dataset can be loaded via the PyGeometric library.
提供机构:
OGB
原始信息汇总
数据集概述:ogbg-molpcba
数据集描述
数据集总结
- 类型: 分子属性预测数据集
- 来源: 由斯坦福团队从MoleculeNet改编,作为Open Graph Benchmark的一部分
- 规模: 小型
支持的任务和排行榜
- 任务: 分子属性预测,涉及128个属性预测,并非所有图都包含所有属性
- 分类: 二分类任务
- 评分标准: 平均精度(AP)平均值
- 排行榜:
数据集结构
数据属性
- 规模: 中等
- 图数量: 437,929
- 平均节点数: 26.0
- 平均边数: 28.1
- 平均节点度: 2.2
- 平均聚类系数: 0.002
- 最大强连通分量比例: 0.999
- 图直径: 13.6
数据字段
node_feat(列表: #nodes x #node-features)edge_index(列表: 2 x #edges)edge_attr(列表: #edges x #edge-features)y(列表: 1 x #labels)num_nodes(整数)
数据分割
- 遵循OGB提供的PyGeometric数据集分割
附加信息
许可信息
- 许可: MIT
引用信息
@inproceedings{hu-etal-2020-open, author = {Weihua Hu and Matthias Fey and Marinka Zitnik and Yuxiao Dong and Hongyu Ren and Bowen Liu and Michele Catasta and Jure Leskovec}, editor = {Hugo Larochelle and Marc Aurelio Ranzato and Raia Hadsell and Maria{-}Florina Balcan and Hsuan{-}Tien Lin}, title = {Open Graph Benchmark: Datasets for Machine Learning on Graphs}, booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual}, year = {2020}, url = {https://proceedings.neurips.cc/paper/2020/hash/fb60d411a5c5b72b2e7d3527cfc84fd0-Abstract.html}, }
贡献者
- 感谢 @clefourrier 添加此数据集
搜集汇总
数据集介绍
构建方式
在计算化学与药物发现领域,分子性质预测是核心挑战之一。ogbg-molpcba数据集源自MoleculeNet,由斯坦福大学团队精心整合并纳入开放图基准(Open Graph Benchmark)。该数据集构建过程涉及从公开化学数据库中系统性地提取分子结构,并将其规范化为图表示形式,其中原子作为节点,化学键作为边。每个分子图均标注了多达128种二元性质标签,涵盖了广泛的生物活性与物理化学特性,部分性质标签在特定分子中可能存在缺失,以反映真实世界数据的稀疏性。
特点
该数据集以其规模与复杂性著称,共包含437,929个分子图,平均每个图拥有26个节点与28.1条边,呈现出中等尺度的图结构。其独特之处在于多任务预测框架,旨在同时预测128个不同的分子性质,这为模型处理高维、稀疏标签提供了基准场景。数据集的图结构特征,如平均节点度与聚类系数,均经过精确计算,确保了其在图机器学习研究中的代表性与挑战性。此外,数据集严格遵循原始划分,保障了评估过程的一致性与可复现性。
使用方法
为便于研究者高效利用,ogbg-molpcba提供了与主流图学习库的兼容接口。用户可通过Hugging Face的datasets库直接加载数据,并借助PyTorch Geometric框架将其转换为DataLoader,以支持批处理训练。数据集中每个样本均包含节点特征、边索引、边属性及多标签向量,可直接输入图神经网络模型。评估时,推荐采用平均精度(Average Precision)作为核心指标,并在官方提供的验证与测试分割上进行性能度量,以确保结果与公开排行榜的可比性。
背景与挑战
背景概述
在计算化学与药物发现领域,分子性质预测是加速新药研发与材料设计的关键环节。ogbg-molpcba数据集由斯坦福大学研究团队于2020年构建,作为开放图基准(Open Graph Benchmark)的重要组成部分,旨在为图神经网络提供标准化的评估平台。该数据集源自MoleculeNet,涵盖437,929个分子图,每个图对应128种二元分类性质预测任务,其核心研究问题在于探索如何利用图结构数据精准预测分子性质,从而推动化学信息学与机器学习交叉领域的算法创新。
当前挑战
分子性质预测面临多重挑战:其一,数据稀疏性与标签不完整性构成主要障碍,128个性质标签中部分样本存在缺失值,导致模型训练需处理非平衡与噪声数据;其二,分子图的复杂结构表征要求模型兼顾局部原子交互与全局拓扑特征,对图神经网络的表达能力提出更高要求。在构建过程中,挑战集中于数据标准化与质量把控,需从原始化学数据库中提取并清洗分子图,确保节点与边特征的化学意义一致性,同时划分训练、验证与测试集时需维持化学空间的代表性,避免数据泄露影响评估可靠性。
常用场景
经典使用场景
在计算化学与药物发现领域,分子性质预测是评估化合物生物活性的核心任务。ogbg-molpcba数据集以其包含437,929个分子图与128个二元分类任务的规模,成为图神经网络模型性能验证的基准平台。研究者常利用该数据集训练模型,以原子为节点、化学键为边构建图结构,通过节点与边的特征学习,实现对多种分子性质的并行预测,推动图表示学习在化学信息学中的发展。
解决学术问题
该数据集有效应对了分子性质预测中数据标准化与评估一致性的挑战。传统研究常受限于小规模或单一性质的数据,ogbg-molpcba通过统一的数据格式与分割策略,为多任务学习、图神经网络泛化能力以及不平衡分类问题提供了严谨的实验环境。其平均精度(AP)评估指标促进了模型间的公平比较,加速了图机器学习算法在复杂化学空间中的探索与优化。
衍生相关工作
围绕ogbg-molpcba,衍生出多项图神经网络的创新研究。例如,Graph Isomorphism Network(GIN)等模型在其上验证了消息传递机制的效力;后续工作如Graph Attention Networks(GAT)的变体探索了注意力机制在多任务预测中的应用。这些研究不仅推动了图表示学习理论的深化,还为化学与生物领域的跨学科合作奠定了算法基础,持续丰富着开放图基准(OGB)的生态体系。
以上内容由遇见数据集搜集并总结生成


