BenCzechMark (BCM)
收藏arXiv2024-12-24 更新2024-12-26 收录
下载链接:
https://huggingface.co/spaces/CZLC/BenCzechMark
下载链接
链接失效反馈官方服务:
资源简介:
BenCzechMark (BCM) 是由布尔诺理工大学等机构联合开发的首个综合性捷克语基准测试,旨在评估大型语言模型在捷克语上的表现。该数据集包含50个任务,涵盖8个类别,涉及历史新闻、学生作文、口语等多个领域。数据集中的任务包括多选、开放答案、分类和语言建模等多种形式。BCM不仅用于模型性能评估,还用于训练首个捷克语为中心的7B参数语言模型。该数据集的应用领域包括自然语言理解、阅读理解、命名实体识别等,旨在解决捷克语在大型语言模型中的评估和优化问题。
BenCzechMark (BCM) is the first comprehensive Czech-language benchmark jointly developed by Brno University of Technology and other institutions, designed to evaluate the performance of large language models on Czech. This dataset contains 50 tasks spanning 8 categories, covering multiple domains such as historical news, student essays, and spoken language. The tasks in the dataset adopt various formats including multiple-choice, open-ended answering, classification, and language modeling. BCM is not only utilized for model performance evaluation, but also for training the first Czech-centric 7B-parameter language model. Its application fields include natural language understanding, reading comprehension, named entity recognition and other areas, aiming to address the issues of evaluating and optimizing Czech in large language models.
提供机构:
布尔诺理工大学, 马萨里克大学, 捷克技术大学布拉格CIIRC, 俄斯特拉发大学, Hugging Face
创建时间:
2024-12-24
搜集汇总
数据集介绍
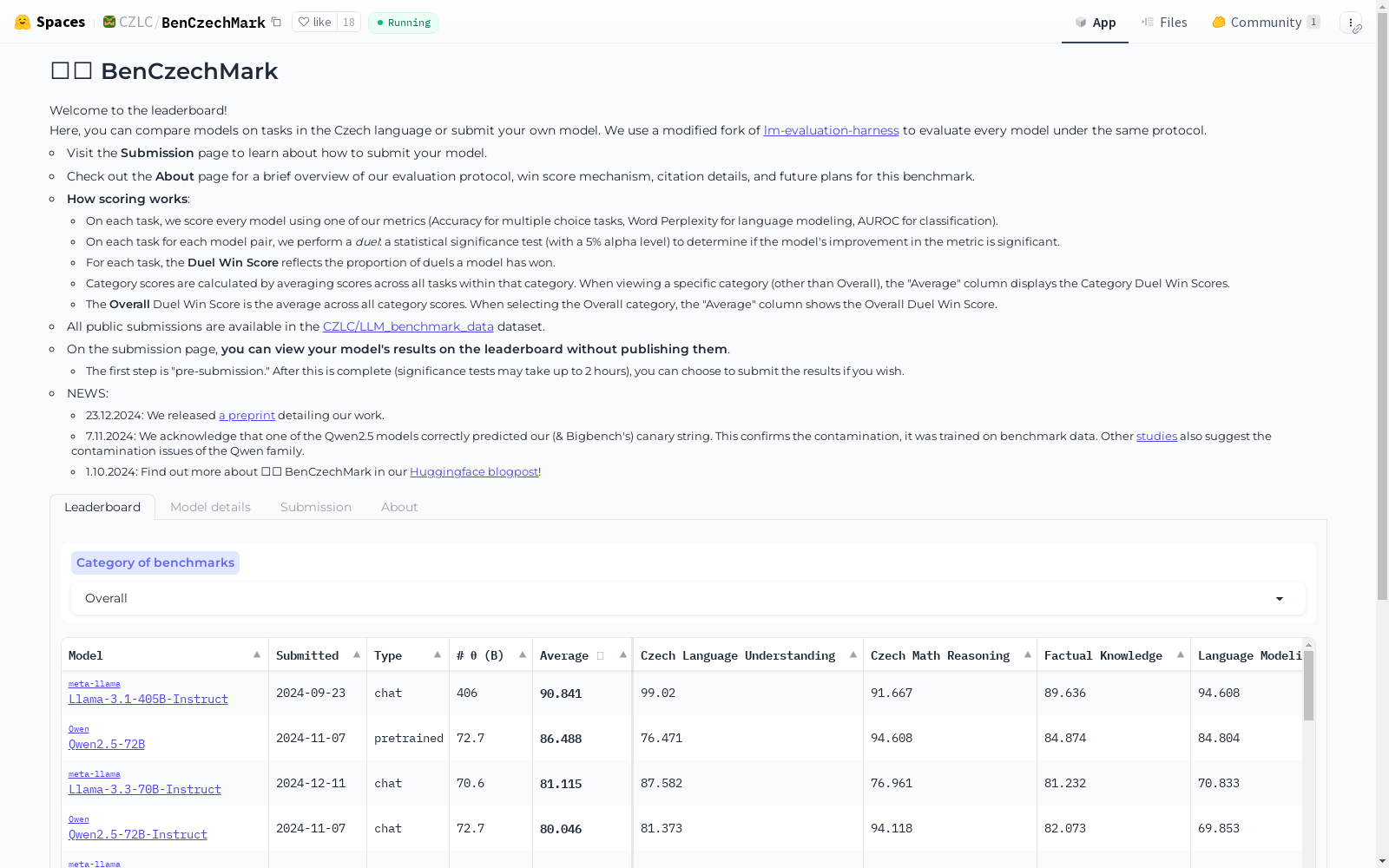
构建方式
BenCzechMark (BCM) 是一个针对捷克语的大规模语言模型基准测试,涵盖了50个具有挑战性的任务,分为8个类别。数据集的构建主要依赖于捷克本土的任务,包括历史新闻、学生作文、口语等多种领域。其中,11个任务是新收集的,其余任务则来自现有的公开数据集。为了确保数据的纯净性,研究团队还构建了BUTLarge Czech Collection,这是目前最大的公开捷克语语料库,用于污染分析和模型的持续预训练。此外,BCM还引入了基于统计显著性理论的评分系统,并通过任务间的聚合机制来评估模型的整体性能。
特点
BCM数据集的特点在于其多样性和全面性。它不仅涵盖了传统的自然语言处理任务,如自然语言推理和阅读理解,还包括了捷克语特有的语言和文化任务。数据集中的任务格式多样,包括多项选择、开放式回答、分类和语言建模等。此外,BCM采用了阈值无关的评估指标(如AUROC)来避免模型校准问题,并通过统计显著性测试来确保评估结果的可靠性。数据集还包含一个排行榜,允许研究人员提交新模型并进行比较。
使用方法
BCM数据集的使用方法主要包括任务格式的定义和评估指标的设定。每个任务根据其性质被分为四种格式之一:多项选择、开放式回答、分类或语言建模。评估指标根据任务格式的不同而有所变化,例如,多项选择任务使用准确率,分类任务使用AUROC,开放式回答任务使用精确匹配。模型的性能通过统计显著性测试进行对比,最终通过Duel Win Score(DWS)来衡量模型在特定任务上的表现。研究人员可以通过提交模型到BCM排行榜,与其他模型进行比较,并分析模型在不同任务类别中的表现。
背景与挑战
背景概述
BenCzechMark (BCM) 是由捷克布尔诺理工大学、马萨里克大学等机构的研究团队于2024年推出的首个专注于捷克语的大规模语言模型基准测试。该数据集旨在评估多任务、多指标的语言模型性能,特别是在捷克语环境下的表现。BCM 包含了50个具有挑战性的任务,涵盖了8个类别,包括历史新闻、学生作文、口语等多种领域。此外,BCM 还引入了BUTLarge Czech Collection,这是目前最大的公开捷克语语料库,用于污染分析和捷克语模型的持续预训练。BCM 的评分系统基于统计显著性理论,并采用了受社会偏好理论启发的任务聚合方法。该数据集的发布填补了捷克语基准测试的空白,为评估本地语言模型提供了重要工具。
当前挑战
BCM 面临的挑战主要体现在两个方面:首先,在解决领域问题时,BCM 旨在评估语言模型在捷克语环境下的多任务性能,包括自然语言推理、阅读理解等传统NLP任务。然而,由于捷克语资源相对较少,构建一个全面且多样化的基准测试具有挑战性。其次,在数据集构建过程中,研究人员面临了数据污染、翻译质量不一致等问题。例如,部分任务的数据是通过自动翻译生成的,翻译质量可能影响模型的评估结果。此外,BCM 采用了无阈值的AUROC指标来避免模型校准问题,但如何公平地聚合不同任务的表现仍是一个开放性问题。这些挑战要求研究人员在数据收集、任务设计和评估方法上进行精细的优化。
常用场景
经典使用场景
BenCzechMark (BCM) 是一个专为捷克语设计的多任务、多指标基准测试,涵盖了50个具有挑战性的任务,涉及8个类别,包括历史新闻、学生作文、口语等。该数据集主要用于评估大型语言模型在捷克语环境下的表现,特别是在多任务推理、自然语言推理、阅读理解等传统NLP任务中的能力。
衍生相关工作
BCM的推出激发了更多针对捷克语的语言模型研究。例如,基于BCM的BUT-Large Czech Collection(BUT-LCC)成为了最大的公开捷克语语料库,用于模型预训练和污染分析。此外,BCM还推动了捷克语特定分词和词汇嵌入的研究,衍生出了首个捷克语中心的7B参数语言模型。
数据集最近研究
最新研究方向
BenCzechMark (BCM) 作为首个专注于捷克语的大规模语言模型基准,近年来在自然语言处理领域引起了广泛关注。该数据集通过结合多任务、多度量的评估机制,特别是基于统计显著性理论的评分系统,为捷克语的语言模型性能提供了全面的评估框架。BCM 的 50 个任务涵盖了从历史新闻、学生作文到口语文本的多个领域,并通过引入捷克语特定的分词和预训练模型,显著提升了捷克语语言模型的表现。当前的研究热点包括如何通过多任务学习提升模型在捷克语任务上的泛化能力,以及如何利用 BCM 的评分机制进行更公平的模型比较。此外,随着多语言模型的快速发展,BCM 也为评估这些模型在捷克语上的表现提供了重要参考,推动了捷克语自然语言处理技术的进步。
相关研究论文
- 1BenCzechMark : A Czech-centric Multitask and Multimetric Benchmark for Large Language Models with Duel Scoring Mechanism布尔诺理工大学, 马萨里克大学, 捷克技术大学布拉格CIIRC, 俄斯特拉发大学, Hugging Face · 2024年
以上内容由遇见数据集搜集并总结生成


