shangeth/mls-mimi-codes
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/shangeth/mls-mimi-codes
下载链接
链接失效反馈官方服务:
资源简介:
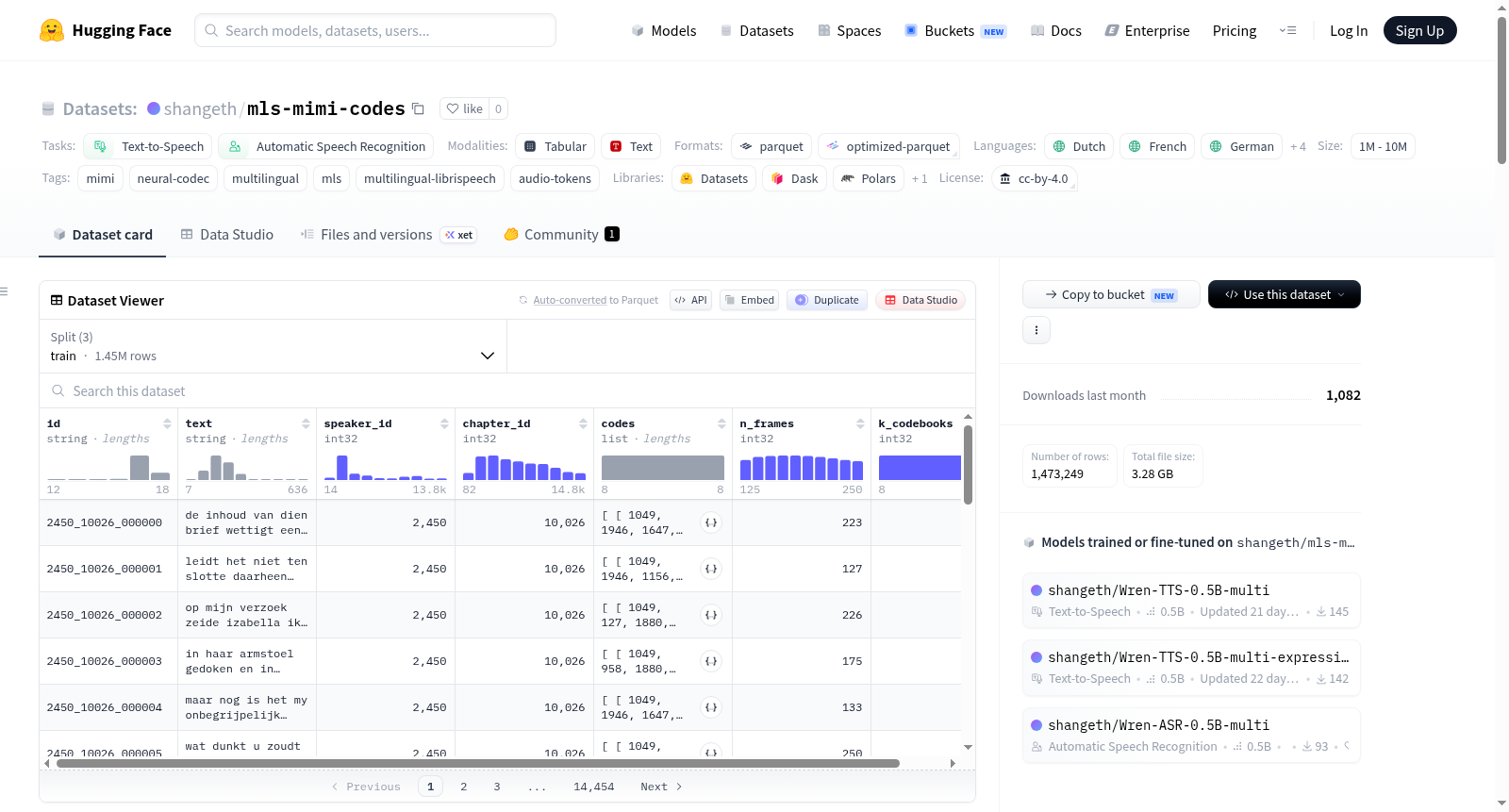
Multilingual LibriSpeech (MLS) — Mimi Codes数据集是一个包含7种非英语语言(荷兰语、法语、德语、意大利语、波兰语、葡萄牙语和西班牙语)的LibriVox有声读物的预提取神经编解码器标记的数据集。这些标记是使用Kyutai Mimi神经编解码器从Multilingual LibriSpeech数据集中提取的。数据集主要用于文本到语音和自动语音识别任务。每个语言配置包含训练集、开发集、测试集以及低资源子集(9小时和1小时)。数据集架构包括 utterance ID、文本转录、说话者ID、章节ID、编解码器标记等字段。数据集的使用方法包括加载数据集和解码回音频文件。
The Multilingual LibriSpeech (MLS) — Mimi Codes dataset consists of pre-extracted neural-codec tokens for LibriVox audiobooks in 7 non-English languages (Dutch, French, German, Italian, Polish, Portuguese, and Spanish). These tokens are extracted using the Kyutai Mimi neural-codec from the Multilingual LibriSpeech dataset. The dataset is primarily used for text-to-speech and automatic speech recognition tasks. Each language configuration includes training, development, test sets, and low-resource subsets (9-hour and 1-hour). The dataset schema includes fields such as utterance ID, text transcript, speaker ID, chapter ID, codec tokens, etc. Usage instructions cover loading the dataset and decoding back to audio files.
提供机构:
shangeth
搜集汇总
数据集介绍
构建方式
本数据集基于Facebook发布的多语种LibriSpeech语料库(MLS),该语料库源自LibriVox项目中的七种非英语语言有声书音频。所有原始音频均为48kHz Opus格式,在预处理阶段被统一重采样至24kHz,随后利用Kyutai Mimi神经编解码器提取离散化的音讯令牌。提取过程保留了全部8个码本的索引序列,并以12.5帧/秒的帧率生成紧凑的声学表示。数据集的每个配置对应一种语言,包含完整的训练、开发、测试集以及两个低资源子集,以适配不同规模的研究需求。此外,通过YAML配置提供了一个虚拟的'all'综合配置,允许用户在不增加额外存储的前提下,从全局路径加载所有语言的数据,便于训练统一的多语种模型。
特点
该数据集的最大特点在于其为多语种神经编解码领域提供了一套标准化、即开即用的音讯令牌资源,覆盖荷兰语、法语、德语等七个语种,训练时长涵盖从约100小时到3300小时不等的广泛范围。所有令牌均由统一的Mimi模型提取,保证了跨语言声学表示的一致性。数据集提供了8个码本的完整索引,用户可根据需要截取前k个码本进行模型训练,灵活适应不同计算资源和精度要求。值得注意的是,数据集默认不含语言标签,且说话人ID在各语言配置间可能重复,这既为多语种联合建模提供了挑战,也促使研究者在数据处理时额外关注语言身份与说话人身份的区分。
使用方法
用户可通过HuggingFace Datasets库便捷加载数据,例如使用'load_dataset("shangeth/mls-mimi-codes", "german", split="dev")'获取德语开发集。每条数据包含唯一的语音片段ID、文本转录、说话人及章节标识,以及形状为[8, n_frames]的令牌张量。将令牌张量转换为torch.long类型后,可结合HuggingFace Transformers库中预加载的MimiModel进行解码,还原为24kHz波形音频。对于多语种联合训练场景,直接使用'all'配置加载所有语言数据,但需注意自行处理语言归属与说话人ID去冲突的问题。完整的提取脚本和下游TTS模型示例可在配套的GitHub仓库中找到。
背景与挑战
背景概述
在语音处理领域,多语言神经编解码器的兴起为高效音频表示与生成任务开辟了新路径。Multilingual LibriSpeech Mimi Codes(mls-mimi-codes)数据集构建于2026年,由研究者Shangeth Rajaa主导,旨在利用Kyutai Mimi神经编解码器对Multilingual LibriSpeech(MLS)语料库中的七种非英语语言(荷兰语、法语、德语、意大利语、波兰语、葡萄牙语、西班牙语)进行音频标记化预提取。该数据集的核心贡献在于填补了多语言神经编解码器训练中高质量、非英语音频标记资源的空白,为文本到语音合成(TTS)与自动语音识别(ASR)的跨语言统一建模提供了基础。通过将LibriVox有声书音频(48kHz Opus格式)重采样至24kHz并提取8个码本索引(12.5帧/秒),该数据集显著降低了多语言语音模型的预处理门槛,其“all”配置更支持直接训练单一多语言模型,推动了低资源语言语音处理的研究进展。
当前挑战
该数据集所应对的领域挑战在于多语言语音系统长期依赖大规模英语音频标记资源,而其他语言(尤其是低资源语言如波兰语、意大利语)缺乏经过神经编解码器标准化的预提取标记库,导致模型在跨语言迁移时性能不均。构建过程中的技术挑战包括:(1)不同语言音频时长分布极不均衡(德语约3.3小时训练集与波兰语约100小时训练集),需处理数据稀疏性对编解码器泛化能力的影响;(2)原始MLS音频采样率(48kHz)与Mimi模型输入要求(24kHz)不一致,重采样过程需避免信息损失与畸变;(3)多语言场景下speaker_id仅按语言内部编码,当使用合并配置时,不同语言间speaker_id碰撞可能导致说话人信息混淆,需用户自行设计分层书签机制。
常用场景
经典使用场景
mls-mimi-codes数据集是专为多语言神经编解码语音建模而设计的核心资源,其经典使用场景涵盖文本到语音合成与自动语音识别两大任务。研究者可借助该数据集加载由Kyutai Mimi模型预提取的8层编解码令牌,这些令牌以12.5帧每秒的速率捕捉了荷兰语、法语、德语、意大利语、波兰语、葡萄牙语和西班牙语等七种非英语语言的声学特征。通过提供的‘all’配置,用户能够便捷地合并所有语言子集以训练统一的多语言模型,而低资源子集(如1小时与9小时训练片段)则支持在数据匮乏条件下进行精细的实验探索。这种设计使得该数据集成为跨语言语音令牌化研究的理想基石。
实际应用
在实际应用中,mls-mimi-codes数据集为构建多语言语音交互系统提供了关键基础设施。基于其预提取的编解码令牌,开发者可以直接训练或微调语音合成与识别模型,而无需处理原始音频的复杂预处理流程。例如,在低资源语言如波兰语或葡萄牙语的语音助手开发中,该数据集的令牌化表示可大幅降低数据获取与模型部署的难度。此外,其与Hugging Face生态的深度集成(如支持一键加载和解码为24 kHz波形)使得该数据集易于融入现有工作流,适用于智能客服、有声书生成、跨语言语音翻译等商业场景,显著提升了多语言语音应用的开发效率。
衍生相关工作
该数据集衍生了一系列具有影响力的相关研究工作,尤其在统一语音文本建模领域。其配套的Wren研究项目利用这些多语言编解码令牌构建了小型开放权重模型,探索了轻量级架构下的联合语音与文本表示学习。同时,基于这些令牌训练的开源文本到语音模型系列展示了预提取神经编解码在低资源合成任务中的潜力。此外,该数据集与LibriSpeech、LibriTTS-R等英文对应物(如shangeth/librispeech-mimi-codes)共同构成了一个完整的跨语言编解码令牌生态,激发了诸如少样本语音克隆、跨语言说话人验证及多模态语音预训练等方向的后续研究,推动了对神经编解码表示迁移能力的深入探讨。
以上内容由遇见数据集搜集并总结生成


