QCRI/MultiNativQA
收藏Hugging Face2026-03-31 更新2025-04-12 收录
下载链接:
https://hf-mirror.com/datasets/QCRI/MultiNativQA
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
task_categories:
- question-answering
language:
- ar
- asm
- bn
- en
- hi
- ne
- tr
tags:
- question-answering
- cultural-aligned
pretty_name: 'MultiNativQA -- Multilingual Native and Culturally Aligned QA'
size_categories:
- 10K<n<100K
dataset_info:
- config_name: Arabic
splits:
- name: train
num_examples: 3649
- name: dev
num_examples: 492
- name: test
num_examples: 988
- config_name: Assamese
splits:
- name: train
num_examples: 1131
- name: dev
num_examples: 157
- name: test
num_examples: 545
- config_name: Bangla-BD
splits:
- name: train
num_examples: 7018
- name: dev
num_examples: 953
- name: test
num_examples: 1521
- config_name: Bangla-IN
splits:
- name: train
num_examples: 6891
- name: dev
num_examples: 930
- name: test
num_examples: 2146
- config_name: English-BD
splits:
- name: train
num_examples: 4761
- name: dev
num_examples: 656
- name: test
num_examples: 1113
- config_name: English-QA
splits:
- name: train
num_examples: 8212
- name: dev
num_examples: 1164
- name: test
num_examples: 2322
- config_name: Hindi
splits:
- name: train
num_examples: 9288
- name: dev
num_examples: 1286
- name: test
num_examples: 2745
- config_name: Nepali
splits:
- name: test
num_examples: 561
- config_name: Turkish
splits:
- name: train
num_examples: 3527
- name: dev
num_examples: 483
- name: test
num_examples: 1218
configs:
- config_name: arabic_qa
data_files:
- split: train
path: arabic_qa/NativQA_ar_msa_qa_train.json
- split: dev
path: arabic_qa/NativQA_ar_msa_qa_dev.json
- split: test
path: arabic_qa/NativQA_ar_msa_qa_test.json
- config_name: assamese_in
data_files:
- split: train
path: assamese_in/NativQA_asm_NA_in_train.json
- split: dev
path: assamese_in/NativQA_asm_NA_in_dev.json
- split: test
path: assamese_in/NativQA_asm_NA_in_test.json
- config_name: bangla_bd
data_files:
- split: train
path: bangla_bd/NativQA_bn_scb_bd_train.json
- split: dev
path: bangla_bd/NativQA_bn_scb_bd_dev.json
- split: test
path: bangla_bd/NativQA_bn_scb_bd_test.json
- config_name: bangla_in
data_files:
- split: train
path: bangla_in/NativQA_bn_scb_in_train.json
- split: dev
path: bangla_in/NativQA_bn_scb_in_dev.json
- split: test
path: bangla_in/NativQA_bn_scb_in_test.json
- config_name: english_bd
data_files:
- split: train
path: english_bd/NativQA_en_NA_bd_train.json
- split: dev
path: english_bd/NativQA_en_NA_bd_dev.json
- split: test
path: english_bd/NativQA_en_NA_bd_test.json
- config_name: english_qa
data_files:
- split: train
path: english_qa/NativQA_en_NA_qa_train.json
- split: dev
path: english_qa/NativQA_en_NA_qa_dev.json
- split: test
path: english_qa/NativQA_en_NA_qa_test.json
- config_name: hindi_in
data_files:
- split: train
path: hindi_in/NativQA_hi_NA_in_train.json
- split: dev
path: hindi_in/NativQA_hi_NA_in_dev.json
- split: test
path: hindi_in/NativQA_hi_NA_in_test.json
- config_name: nepali_np
data_files:
- split: test
path: nepali_np/NativQA_ne_NA_np_test.json
- config_name: turkish_tr
data_files:
- split: train
path: turkish_tr/NativQA_tr_NA_tr_train.json
- split: dev
path: turkish_tr/NativQA_tr_NA_tr_dev.json
- split: test
path: turkish_tr/NativQA_tr_NA_tr_test.json
---
# MultiNativQA: Multilingual Culturally-Aligned Natural Queries For LLMs
### Overview
The **MultiNativQA** dataset is a multilingual, native, and culturally aligned question-answering resource. It spans 7 languages, ranging from high- to extremely low-resource, and covers 9 different locations/cities. To capture linguistic diversity, the dataset includes several dialects for dialect-rich languages like Arabic. In addition to Modern Standard Arabic (MSA), **MultiNativQA** features six Arabic dialects — *Egyptian, Jordanian, Khaliji, Sudanese, Tunisian*, and *Yemeni*.
The dataset also provides two linguistic variations of Bangla, reflecting differences between speakers in *Bangladesh* and *West Bengal, India*. Additionally, **MultiNativQA** includes English queries from *Dhaka* and *Doha*, where English is commonly used as a second language, as well as from *New York, USA*.
The QA pairs in this dataset cover 18 diverse topics, including: *Animals, Business, Clothing, Education, Events, Food & Drinks, General, Geography, Immigration, Language, Literature, Names & Persons, Plants, Religion, Sports & Games, Tradition, Travel*, and *Weather*.
**MultiNativQA** is designed to evaluate and fine-tune large language models (LLMs) for long-form question answering while assessing their cultural adaptability and understanding.
**Note.** The location information in the dataset is determined by the geographic targeting capabilities supported by Google Search. As a result, minor inconsistencies or approximations in location assignment may occasionally occur.
### Directory Structure (JSON files only)
The dataset is organized into directories based on language and region. Each directory contains JSON files for the train, development, and test sets, with the exception of Nepali, which consists of only a test set.
- `arabic_qa/`
- `NativQA_ar_msa_qa_dev.json`
- `NativQA_ar_msa_qa_test.json`
- `NativQA_ar_msa_qa_train.json`
- `assamese_in/`
- `NativQA_asm_NA_in_dev.json`
- `NativQA_asm_NA_in_test.json`
- `NativQA_asm_NA_in_train.json`
- `bangla_bd/`
- `NativQA_bn_scb_bd_dev.json`
- `NativQA_bn_scb_bd_test.json`
- `NativQA_bn_scb_bd_train.json`
- `bangla_in/`
- `NativQA_bn_scb_in_dev.json`
- `NativQA_bn_scb_in_test.json`
- `NativQA_bn_scb_in_train.json`
- `english_bd/`
- `NativQA_en_NA_bd_dev.json`
- `NativQA_en_NA_bd_test.json`
- `NativQA_en_NA_bd_train.json`
- `english_qa/`
- `NativQA_en_NA_qa_dev.json`
- `NativQA_en_NA_qa_test.json`
- `NativQA_en_NA_qa_train.json`
- `hindi_in/`
- `NativQA_hi_NA_in_dev.json`
- `NativQA_hi_NA_in_test.json`
- `NativQA_hi_NA_in_train.json`
- `nepali_np/`
- `NativQA_ne_NA_np_test.json`
- `turkish_tr/`
- `NativQA_tr_NA_tr_dev.json`
- `NativQA_tr_NA_tr_test.json`
- `NativQA_tr_NA_tr_train.json`
#### Example of a data
```
{
"data_id": "cf92ec1e52b4b3071d263a1063b43928",
"category": "immigration",
"input_query": "How long can you stay in Qatar on a visitors visa?",
"question": "Can I extend my tourist visa in Qatar?",
"is_reliable": "very_reliable",
"answer": "If you would like to extend your visa, you will need to proceed to immigration headquarters in Doha prior to the expiry of your visa and apply there for an extension.",
"source_answer_url": "https://hayya.qa/en/web/hayya/faq"
}
```
##### Field Descriptions:
- **`data_id`**: Unique identifier for each data entry.
- **`category`**: General topic or category of the query (e.g., "health", "religion").
- **`input_query`**: The original user-submitted query.
- **`question`**: The formalized question derived from the input query.
- **`is_reliable`**: Indicates the reliability of the provided answer (`"very_reliable"`, `"somewhat_reliable"`, `"unreliable"`).
- **`answer`**: The system-provided answer to the query.
- **`source_answer_url`**: URL of the source from which the answer was derived.
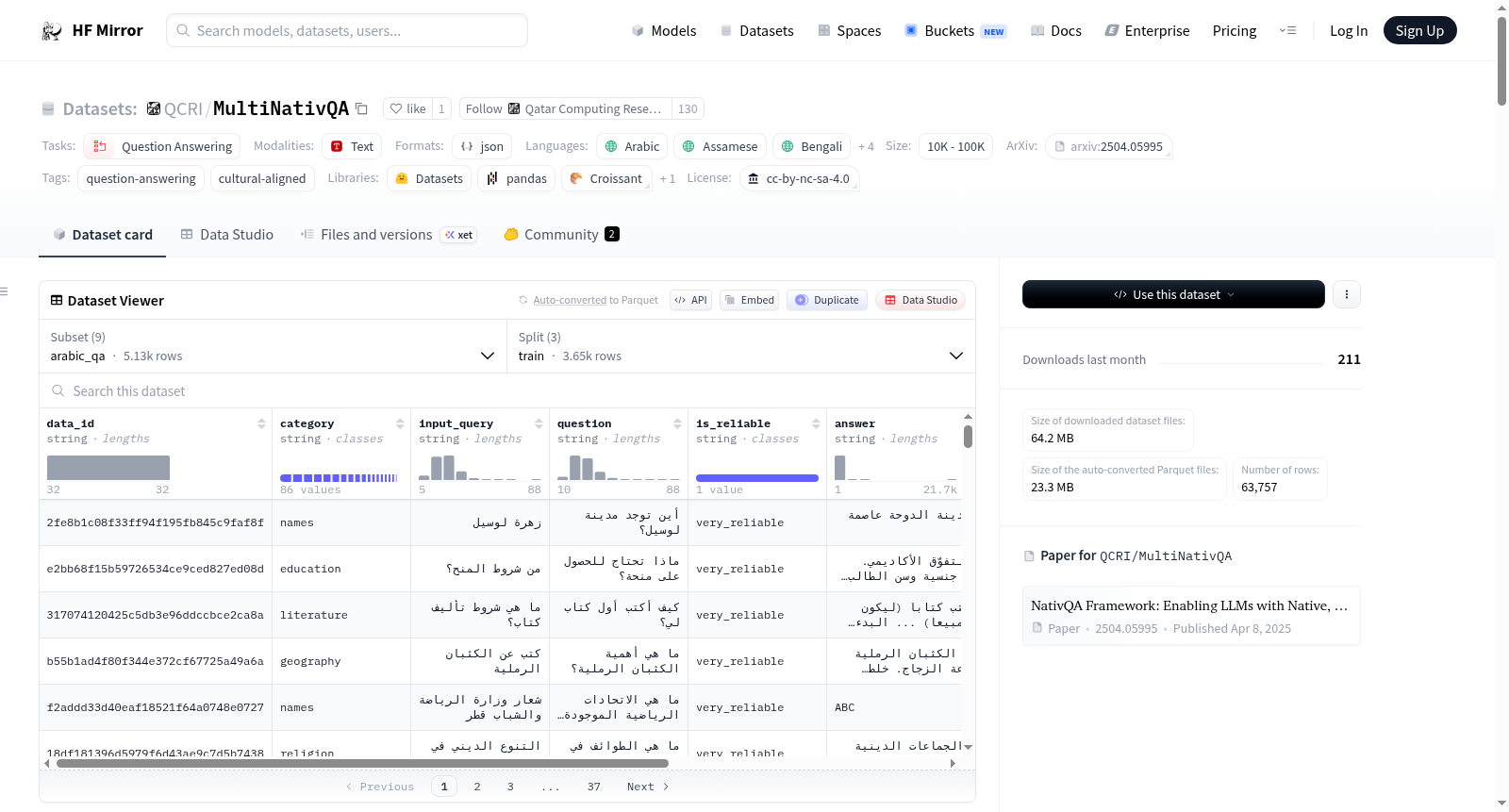
### Statistics
Distribution of the **MultiNativQA** dataset across different languages.
<p align="left"> <img src="./language_donut_chart.png" style="width: 60%;" id="title-icon"> </p>
This dataset consists of two types of data: annotated and un-annotated. We considered the un-annotated data as additional data. Please find the data statistics below:
Statistics of our **MultiNativQA** dataset including languages with the final annotated QA pairs from different location.
| Language | City | Train | Dev | Test | Total |
|-------------|------------|---------|-------|--------|--------|
| Arabic | Doha | 3,649 | 492 | 988 | 5,129 |
| Assamese | Assam | 1,131 | 157 | 545 | 1,833 |
| Bangla | Dhaka | 7,018 | 953 | 1,521 | 9,492 |
| Bangla | Kolkata | 6,891 | 930 | 2,146 | 9,967 |
| English | Dhaka | 4,761 | 656 | 1,113 | 6,530 |
| English | Doha | 8,212 | 1,164 | 2,322 | 11,698 |
| Hindi | Delhi | 9,288 | 1,286 | 2,745 | 13,319 |
| Nepali | Kathmandu | -- | -- | 561 | 561 |
| Turkish | Istanbul | 3,527 | 483 | 1,218 | 5,228 |
| **Total** | | **44,477** | **6,121** | **13,159** | **63,757** |
We provide the un-annotated additional data stats below:
| Language-Location | # of QA |
|-------------------------|---------------|
| Arabic-Egypt | 7,956 |
| Arabic-Palestine | 5,679 |
| Arabic-Sudan | 4,718 |
| Arabic-Syria | 11,288 |
| Arabic-Tunisia | 14,789 |
| Arabic-Yemen | 4,818 |
| English-New York | 6,454 |
| **Total** | **55,702** |
### How to download data
```
import os
import json
from datasets import load_dataset
dataset_names = ['arabic_qa', 'assamese_in', 'bangla_bd', 'bangla_in', 'english_bd',
'english_qa', 'hindi_in', 'nepali_np', 'turkish_tr']
base_dir="./MNQA/"
for dname in dataset_names:
output_dir = os.path.join(base_dir, dname)
# load each language
dataset = load_dataset("QCRI/MultiNativQA", name=dname)
# Save the dataset to the specified directory. This will save all splits to the output directory.
dataset.save_to_disk(output_dir)
# iterate over splits to save the data into json format
for split in ['train','dev','test']:
data = []
if split not in dataset:
continue
for idx, item in enumerate(dataset[split]):
data.append(item)
output_file = os.path.join(output_dir, f"{split}.json")
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
```
### License
The dataset is distributed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0). The full license text can be found in the accompanying licenses_by-nc-sa_4.0_legalcode.txt file.
### Contact & Additional Information
For more details, please visit our [official website](http://nativqa.gitlab.io/).
### Citation
You can access the full paper [here](https://aclanthology.org/2025.findings-acl.770.pdf).
```
@inproceedings{hasan-etal-2025-nativqa,
title = "{N}ativ{QA}: Multilingual Culturally-Aligned Natural Query for {LLM}s",
author = "Hasan, Md. Arid and
Hasanain, Maram and
Ahmad, Fatema and
Laskar, Sahinur Rahman and
Upadhyay, Sunaya and
Sukhadia, Vrunda N and
Kutlu, Mucahid and
Chowdhury, Shammur Absar and
Alam, Firoj",
editor = "Che, Wanxiang and
Nabende, Joyce and
Shutova, Ekaterina and
Pilehvar, Mohammad Taher",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2025",
month = jul,
year = "2025",
address = "Vienna, Austria",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2025.findings-acl.770/",
doi = "10.18653/v1/2025.findings-acl.770",
pages = "14886--14909",
ISBN = "979-8-89176-256-5",
abstract = "Natural Question Answering (QA) datasets play a crucial role in evaluating the capabilities of large language models (LLMs), ensuring their effectiveness in real-world applications. Despite the numerous QA datasets that have been developed and some work done in parallel, there is a notable lack of a framework and large-scale region-specific datasets queried by native users in their own languages. This gap hinders effective benchmarking and the development of fine-tuned models for regional and cultural specificities. In this study, we propose a scalable, language-independent framework, NativQA, to seamlessly construct culturally and regionally aligned QA datasets in native languages for LLM evaluation and tuning. We demonstrate the efficacy of the proposed framework by designing a multilingual natural QA dataset, MultiNativQA, consisting of approximately {\textasciitilde}64K manually annotated QA pairs in seven languages, ranging from high- to extremely low-resource, based on queries from native speakers from 9 regions covering 18 topics. We benchmark both open- and closed-source LLMs using the MultiNativQA dataset. The dataset and related experimental scripts are publicly available for the community at: https://huggingface.co/datasets/QCRI/MultiNativQAand https://gitlab.com/nativqa/multinativqa."
}
@article{alam2025nativqa,
title = {{NativQA Framework:} Enabling llms with native, local, and everyday knowledge},
author = {Alam, Firoj and Hasan, Md Arid and Laskar, Sahinur Rahman and Kutlu, Mucahid and Darwish, Kareem and Chowdhury, Shammur Absar},
journal = {arXiv preprint arXiv:2504.05995},
year = {2025},
}
```
提供机构:
QCRI
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,构建能够反映语言多样性与文化特异性的问答数据集至关重要。MultiNativQA的构建依托于一个可扩展的、语言无关的框架,通过收集来自九个不同地区母语使用者的自然查询,并人工进行标注,最终形成了涵盖七个语种、跨越十八个主题的问答对。该数据集特别注重捕捉方言变体与文化背景,例如包含了阿拉伯语的多种方言以及孟加拉语在孟加拉国和印度西孟加拉邦的地域变体,确保了数据在语言和文化层面的原生性与对齐性。
特点
该数据集的核心特征在于其多语言覆盖与文化对齐性,不仅包含了阿拉伯语、孟加拉语、印地语等高资源语言,也纳入了阿萨姆语、尼泊尔语等低资源语言。数据条目经过精心设计,每个样本均包含原始查询、规范化问题、可靠性标注及带有来源的答案,覆盖了从动物、商业到宗教、旅行等十八个日常生活主题。这种设计使得数据集能够有效评估大型语言模型在跨文化语境下的理解与生成能力,尤其关注模型对地域性知识的掌握。
使用方法
为便于研究使用,数据集已按语言和地区组织成独立的配置,用户可通过Hugging Face的`datasets`库直接加载。典型的使用流程包括导入指定配置名称、加载训练集、开发集和测试集,并可根据需要将数据保存为JSON格式进行后续处理。该数据集主要应用于长格式问答任务的模型评估与微调,尤其适合用于检验模型的文化适应性与多语言理解性能,为相关领域的学术研究提供了标准化的基准资源。
背景与挑战
背景概述
在自然语言处理领域,评估大型语言模型在真实世界应用中的效能,亟需能够反映语言多样性与文化特异性的问答数据集。MultiNativQA数据集应运而生,由卡塔尔计算研究所等机构的研究团队于2025年创建。该数据集旨在解决现有问答资源在区域与文化对齐性上的不足,核心研究问题聚焦于如何构建一个涵盖高资源至极低资源语言、并深度融入本土文化背景的大规模基准。它覆盖阿拉伯语、阿萨姆语、孟加拉语等七种语言,涉及九个不同地域,包含十八个日常话题,为衡量模型的文化适应性与语言理解能力提供了关键工具,对推动多语言及跨文化自然语言处理研究具有显著影响力。
当前挑战
MultiNativQA所针对的领域挑战在于,现有问答数据集往往缺乏由母语使用者以本土语言提出的、紧密贴合特定区域文化背景的自然查询,这限制了大型语言模型在真实跨文化场景中的有效评估与优化。在数据集构建过程中,研究者面临多重具体挑战:首先,需要设计一个可扩展的、语言无关的框架,以系统性地收集和标注来自不同地域的母语查询;其次,处理极低资源语言(如阿萨姆语、尼泊尔语)时,面临数据稀缺与标注资源有限的困难;此外,准确捕捉并区分同一语言内的方言变体(如阿拉伯语的六种方言)及区域变体(如孟加拉语在孟加拉国与印度的差异),并确保查询在文化上的精确对齐,均构成了显著的构建复杂性。
常用场景
经典使用场景
在跨语言自然语言处理领域,MultiNativQA数据集为评估和微调大语言模型的长文本问答能力提供了经典场景。该数据集覆盖阿拉伯语、孟加拉语、印地语等七种语言,并包含多种方言变体,其问题与答案均源自母语使用者的真实查询,涉及移民、宗教、传统等十八个文化相关主题。研究人员通常利用该数据集测试模型在多元文化语境下的理解深度,尤其关注模型对低资源语言的适应性与回答的可靠性,从而推动多语言问答系统向更精准、更包容的方向发展。
衍生相关工作
围绕MultiNativQA数据集,学术界已衍生出一系列关注文化对齐与低资源语言处理的经典研究工作。例如,相关研究基于该数据集框架进一步扩展了方言覆盖范围,深入探讨了阿拉伯语各变体间的语义差异对模型性能的影响。另有工作利用其标注可靠性指标,开发了针对答案可信度的自动评估方法。同时,该数据集也促进了跨语言迁移学习技术的创新,研究者通过其多语言平行数据探索了从高资源语言向低资源语言的知识转移机制,为构建更稳健的全球化语言模型提供了重要实验基础。
数据集最近研究
最新研究方向
在自然语言处理领域,多语言与文化对齐的问答研究正成为评估大语言模型适应性的关键前沿。MultiNativQA数据集以其涵盖七种语言、九大区域的特性,为探索模型在低资源语言与文化特定语境下的表现提供了宝贵资源。当前研究焦点集中于利用该数据集推动跨语言迁移学习,增强模型对地域性表达与习俗的理解能力,从而应对全球化应用中模型的文化偏见与知识局限。相关热点事件如多语言大模型的迭代升级,进一步凸显了此类数据在提升模型包容性与实用性方面的重要意义,为构建真正具备全球视野的智能系统奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


