SynthLight
收藏arXiv2025-01-17 更新2025-01-18 收录
下载链接:
https://vrroom.github.io/synthlight/
下载链接
链接失效反馈官方服务:
资源简介:
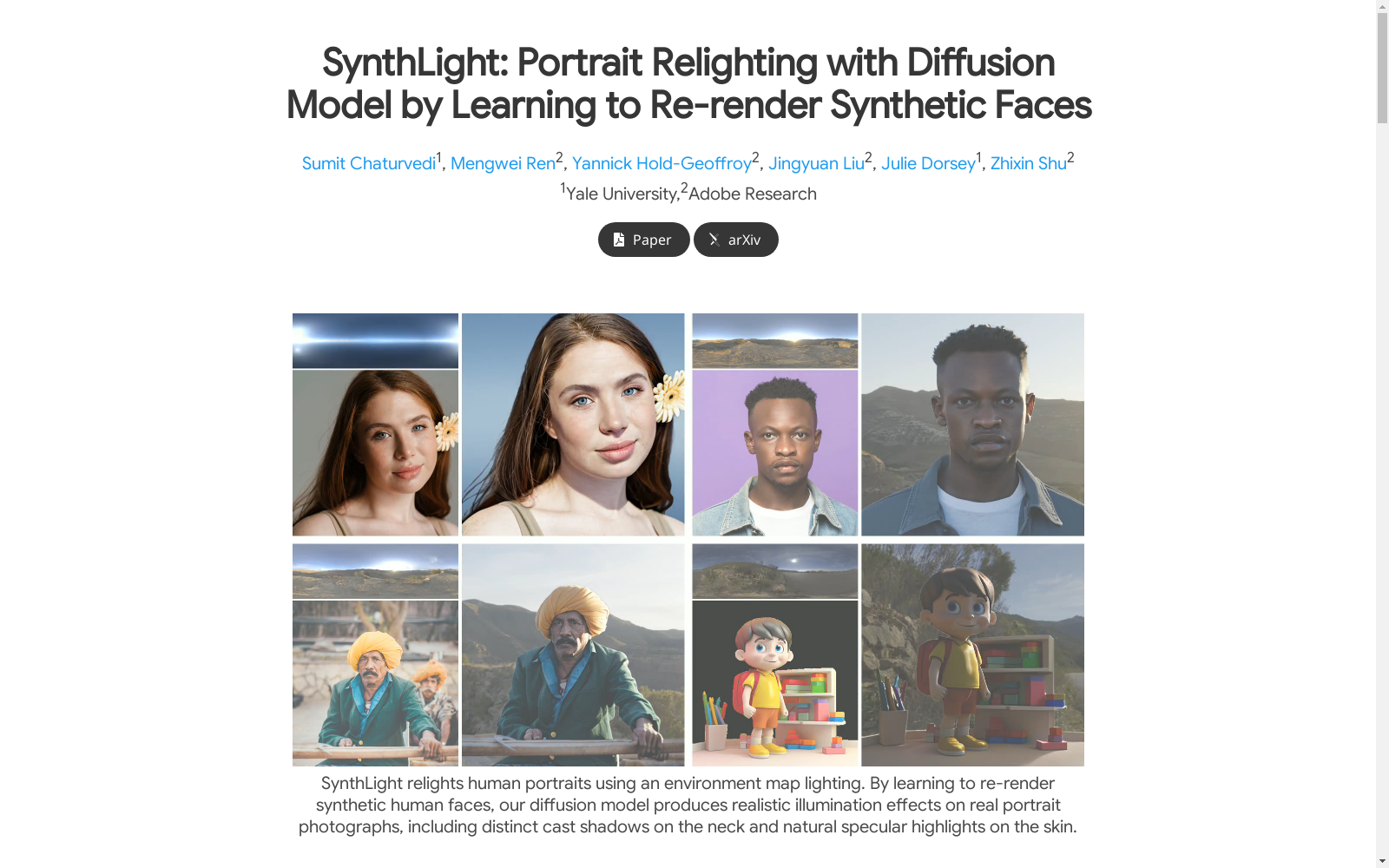
SynthLight数据集由耶鲁大学和Adobe Research共同创建,旨在通过3D渲染技术模拟不同光照条件下的人像图像。该数据集包含约126万张图像,每张图像均由Blender的Cycles渲染器生成,分辨率为512×512。数据集通过350个主题的3D头部模型生成,每个主题包含多种外观变化,如不同发型、肤色、表情和服装。数据集的创建过程涉及使用高质量的PBR纹理贴图和环境光照图进行渲染。该数据集主要用于训练扩散模型,以实现肖像图像在不同光照条件下的重新照明,解决肖像摄影中光照控制的难题。
The SynthLight dataset was co-created by Yale University and Adobe Research, aiming to simulate portrait images under various lighting conditions via 3D rendering technology. It contains approximately 1.26 million images, each generated using Blender's Cycles renderer with a resolution of 512×512. The dataset is developed based on 3D head models of 350 subjects, with each subject featuring diverse appearance variations including different hairstyles, skin tones, facial expressions and clothing. The dataset creation process involves rendering with high-quality PBR texture maps and environment lighting maps. This dataset is primarily used for training diffusion models to achieve relighting of portrait images under different lighting conditions, addressing the challenge of lighting control in portrait photography.
提供机构:
耶鲁大学, Adobe Research
创建时间:
2025-01-17
搜集汇总
数据集介绍
构建方式
SynthLight数据集的构建基于物理渲染引擎,通过模拟不同光照条件下的3D头部资产来生成合成数据。具体而言,研究团队使用Blender(Cycles渲染器)生成了成对的肖像图像,每对图像分别在不同的光照环境下渲染。这些图像对用于训练扩散模型,使其能够从一种光照条件下的图像重新渲染出另一种光照条件下的图像。为了弥合合成数据与真实图像之间的领域差距,研究团队采用了多任务训练策略,结合了无光照标签的真实肖像图像,并在推理时通过无分类器引导的扩散采样程序来保留输入图像的细节。
特点
SynthLight数据集的特点在于其高度逼真的光照效果,包括皮肤上的自然高光和颈部的投射阴影。尽管模型仅通过合成的人像图像进行训练,但它能够很好地泛化到多种真实场景中,包括半身肖像和全身人像。数据集中的图像涵盖了多种光照条件、肤色、发型、表情和服装,确保了数据的多样性和广泛适用性。此外,数据集还通过多任务训练和推理时适应策略,有效减少了合成数据与真实图像之间的领域差距,提升了模型在真实图像上的表现。
使用方法
SynthLight数据集的使用方法主要围绕肖像重光照任务展开。用户可以通过输入一张在未知光照条件下拍摄的肖像图像,并指定目标光照环境(通过全景环境图表示),模型将生成一张在目标光照条件下的重光照图像。在训练过程中,模型通过合成数据学习光照条件下的像素变换,并结合真实图像进行多任务训练,以确保模型在真实图像上的泛化能力。推理时,模型通过无分类器引导的扩散采样程序,保留输入图像的细节,并生成具有高保真光照效果的输出图像。
背景与挑战
背景概述
SynthLight数据集由耶鲁大学和Adobe Research的研究团队于2025年提出,旨在通过扩散模型实现肖像重光照任务。该数据集的核心研究问题是如何在缺乏真实光照标签的情况下,利用合成数据生成逼真的光照效果。SynthLight通过物理渲染引擎生成3D头部模型在不同光照条件下的渲染图像,解决了传统方法依赖Light Stage数据的局限性。该数据集在计算机视觉领域的影响力显著,特别是在肖像重光照任务中,展示了合成数据在生成复杂光照效果(如镜面高光和投射阴影)方面的潜力。
当前挑战
SynthLight数据集面临的主要挑战包括两个方面。首先,在领域问题方面,肖像重光照任务本身具有高度复杂性,尤其是在处理真实照片时,如何保持人物身份的同时生成逼真的光照效果是一个难题。其次,在数据集构建过程中,合成数据与真实照片之间的域差距是一个显著挑战。尽管合成数据能够模拟多种光照条件,但其与真实图像的分布差异可能导致模型在真实场景中的泛化能力不足。为此,研究团队提出了多任务训练和推理时自适应策略,以缩小合成与真实图像之间的差距,但仍需进一步优化以应对更复杂的光照场景和多样化的人物特征。
常用场景
经典使用场景
SynthLight数据集在肖像重光照领域具有广泛的应用,尤其是在生成逼真的光照效果方面。通过使用基于物理的渲染引擎生成合成数据,该数据集能够模拟不同光照条件下的3D头部图像,进而训练扩散模型以实现肖像照片的重光照。其经典使用场景包括在影视后期制作、虚拟现实和游戏开发中,用于生成具有复杂光照效果的肖像图像,如自然的高光和阴影。
衍生相关工作
SynthLight数据集衍生了许多相关的研究工作,尤其是在基于扩散模型的光照控制领域。例如,DiLightNet和Neural Gaffer等研究利用扩散模型实现了对物体光照的精细控制。此外,Relightful Harmonization和IC-Light等研究通过结合高质量数据集(如Light Stage数据和合成渲染数据)实现了背景和谐化的肖像重光照。SynthLight的提出进一步推动了这些研究的发展,尤其是在肖像重光照的细节保留和光照效果生成方面,为后续研究提供了重要的参考和基础。
数据集最近研究
最新研究方向
近年来,SynthLight数据集在肖像重光照领域的研究方向主要集中在基于扩散模型的重渲染技术上。通过利用物理渲染引擎生成合成数据,SynthLight能够模拟不同光照条件下的3D头部渲染,从而训练扩散模型以学习光照条件下的像素变换。该数据集的前沿研究包括多任务训练策略,利用无光照标签的真实肖像图像进行训练,以及基于无分类器引导的推理时间扩散采样方法,以更好地保留输入肖像的细节。这些技术显著提升了模型在真实照片上的泛化能力,能够生成包括镜面高光和投射阴影在内的逼真光照效果。SynthLight的研究不仅推动了肖像重光照技术的发展,还为生成复杂光照效果提供了新的思路,特别是在处理半身像和全身像等多样化场景时表现出色。
相关研究论文
- 1SynthLight: Portrait Relighting with Diffusion Model by Learning to Re-render Synthetic Faces耶鲁大学, Adobe Research · 2025年
以上内容由遇见数据集搜集并总结生成


