the-law
收藏Hugging Face2026-01-23 更新2026-01-24 收录
下载链接:
https://huggingface.co/datasets/PunkRockGirl/the-law
下载链接
链接失效反馈官方服务:
资源简介:
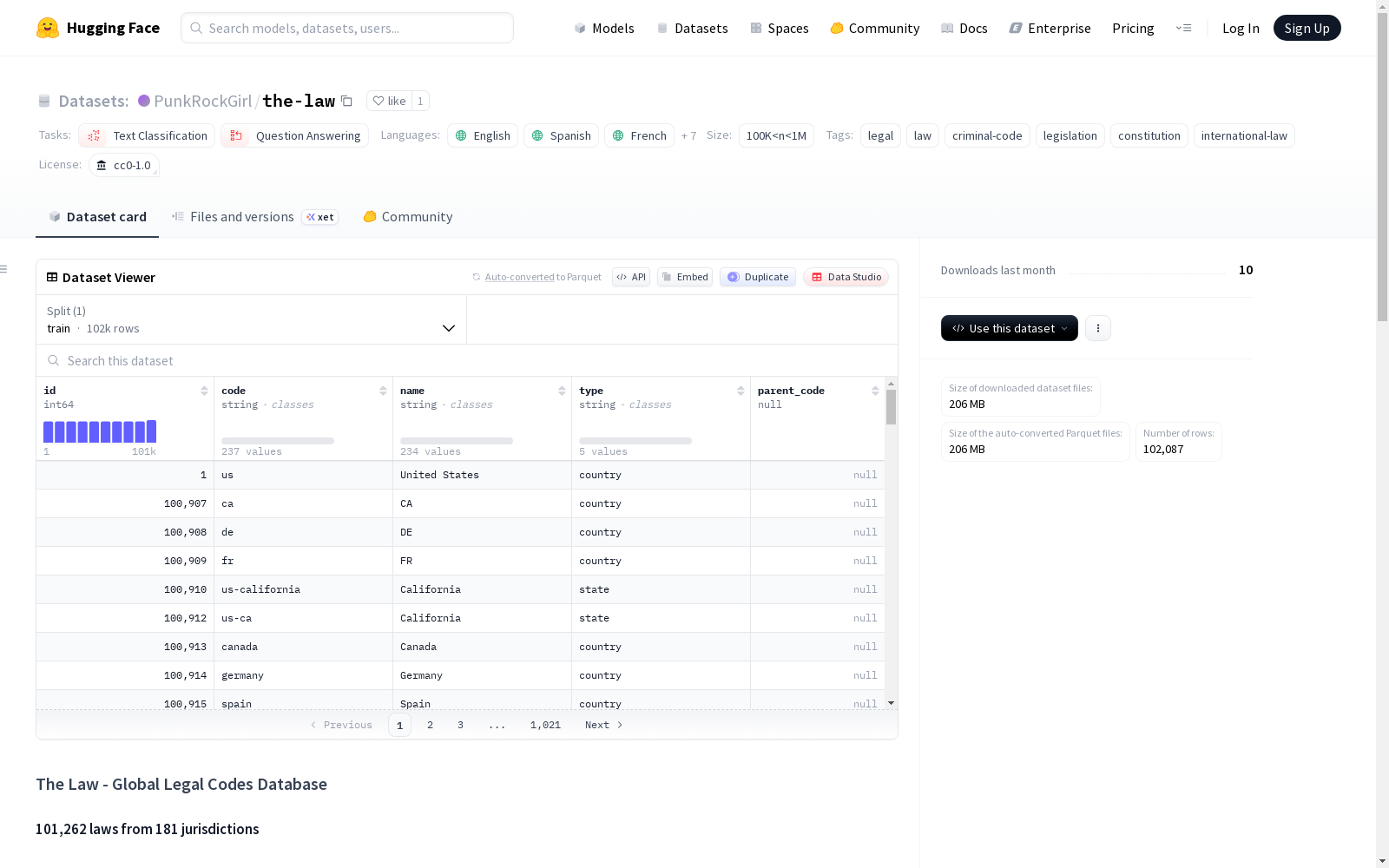
该数据集是一个全球法律代码数据库,包含来自181个管辖区的101,262条法律。数据集涵盖了多种法律类别,包括美国联邦法典、国家刑法典、宪法、国际条约和历史法典等。数据集支持20多种语言,包括英语、西班牙语、法语、德语、阿拉伯语、中文、俄语、葡萄牙语、日语、韩语等。数据集以SQLite数据库形式提供,包含三个主要表格:legal_sections(主要法律文本内容)、jurisdictions(国家/地区元数据)和categories(法律分类)。数据集的使用示例展示了如何通过Python查询特定法律内容。数据集遵循CC0-1.0许可,数据来源于官方政府来源、法律数据库和公共记录。
创建时间:
2026-01-21
原始信息汇总
数据集概述
基本信息
- 数据集名称: The Law - Global Legal Codes Database
- 发布者: PunkRockGirl
- 许可协议: CC0-1.0(公共领域)
- 任务类别: 文本分类、问答
- 语言: 英语、西班牙语、法语、德语、阿拉伯语、中文、俄语、葡萄牙语、日语、韩语等20多种语言
- 标签: 法律、法规、刑法典、立法、宪法、国际法
- 数据规模: 100K < n < 1M
内容构成
数据集包含来自181个司法管辖区的101,262部法律,具体分类如下:
| 类别 | 数量 |
|---|---|
| 美国联邦法典 | 100,906 部法律 |
| 国家刑法典 | 155 个国家 |
| 宪法 | 68 部 |
| 国际条约 | 25 部 |
| 历史法典 | 5 部(例如《汉谟拉比法典》、《大宪章》等) |
数据结构
数据集采用SQLite数据库格式,包含以下主要数据表:
legal_sections- 存储法律文本内容jurisdictions- 存储国家/地区的元数据categories- 存储法律分类信息
使用方法
用户可通过Hugging Face Hub下载数据库文件,并使用SQLite进行连接和查询。示例代码展示了如何查找包含特定关键词(如“Murder”)的法律条款。
数据来源
数据编译自官方政府来源、法律数据库和公共记录。
搜集汇总
数据集介绍
构建方式
在法律信息数字化浪潮中,该数据集通过系统化汇编全球公开法律文献构建而成。其核心数据来源于各国政府官方发布的法律文本、权威法律数据库以及历史公共记录,涵盖了从现行联邦法典到古代法典的广泛内容。构建过程注重原始文本的完整性,采用结构化方式将不同司法管辖区的法律条文、宪法条款及国际条约统一整理至SQLite数据库中,确保了数据来源的可靠性与格式的一致性。
特点
该数据集囊括了全球181个司法管辖区的超过十万条法律条文,呈现出显著的多样性与规模性。其内容不仅覆盖了美国联邦法典、155个国家的刑法典,还收录了68部宪法、25项国际条约以及包括《汉谟拉比法典》在内的5部历史法典,涉及二十余种语言。这种跨地域、跨语言、跨历史时期的全面覆盖,为比较法律研究与多语言自然语言处理任务提供了独特的资源基础。
使用方法
研究者可通过Hugging Face Hub便捷下载数据集的核心SQLite数据库文件。利用Python的sqlite3库连接数据库后,即可执行结构化查询语言(SQL)进行灵活的数据检索与分析。例如,可通过关键词匹配查询特定主题的法律条文,或结合元数据表进行跨法域、跨类别的对比研究。这种基于关系型数据库的访问方式,兼顾了数据获取的便利性与深度分析的可行性,适用于法律文本分类、问答系统构建等多种下游任务。
背景与挑战
背景概述
在法律信息学与计算法学领域,全球法律文本的数字化与结构化是推动法律智能应用的基础。'the-law'数据集由PunkRockGirl团队构建,作为一个综合性全球法律代码数据库,它汇集了来自181个司法管辖区的101,262条法律条文,涵盖美国联邦法典、155个国家的刑法典、68部宪法、25项国际条约及5部历史法典。该数据集旨在为法律文本分类、问答系统及跨语言法律分析等任务提供大规模、多语种的资源,其公开领域许可(CC0-1.0)促进了法律研究与实践的开放访问,对自动化法律推理、合规性检查及比较法研究产生了深远影响。
当前挑战
在法律领域,自动化处理面临文本复杂性高、术语专业性强及跨司法管辖区差异大等挑战,该数据集致力于支持法律文本分类与问答任务,需应对法律语言的歧义性、条文间引用关系及动态修订带来的时效性问题。在构建过程中,挑战主要源于多源数据整合,包括从官方政府来源与公共记录中采集20多种语言的法律文本,需确保格式统一、内容准确,并处理不同司法体系的分类与元数据标准化,同时维护大规模数据库的结构完整性与查询效率。
常用场景
经典使用场景
在法律信息检索与自然语言处理领域,The Law数据集为研究人员提供了跨越181个司法管辖区的十万余条法律条文,覆盖了从美国联邦法典到各国刑法典、宪法及国际条约的广泛内容。该数据集最经典的使用场景在于支持法律文本的分类与问答任务,例如通过查询特定罪名如谋杀相关的法律条款,帮助构建自动化法律咨询系统或司法辅助工具,从而提升法律信息的可访问性和检索效率。
解决学术问题
该数据集有效解决了法律人工智能研究中数据稀缺与多语言处理的挑战,为跨司法管辖区的法律比较分析、法律条文语义理解以及自动法规解释提供了标准化资源。其意义在于促进了计算法学的发展,使得研究者能够基于大规模真实法律文本,探索法律语言的模式识别、法规冲突检测以及法律推理模型的构建,推动了法律与人工智能交叉领域的学术进步。
衍生相关工作
基于The Law数据集,已衍生出多项经典研究工作,包括法律条文的多标签分类模型、跨语言法律问答系统以及法规知识图谱的构建。这些工作不仅深化了对法律文本结构的理解,还推动了如Legal-BERT等预训练语言模型在法律领域的适配与应用,为后续研究如法律判决预测、法规摘要生成等任务奠定了数据基础,丰富了计算法学的技术生态。
以上内容由遇见数据集搜集并总结生成


