OPENFAKE
收藏OpenFake 数据集概述
数据集详情
数据集描述
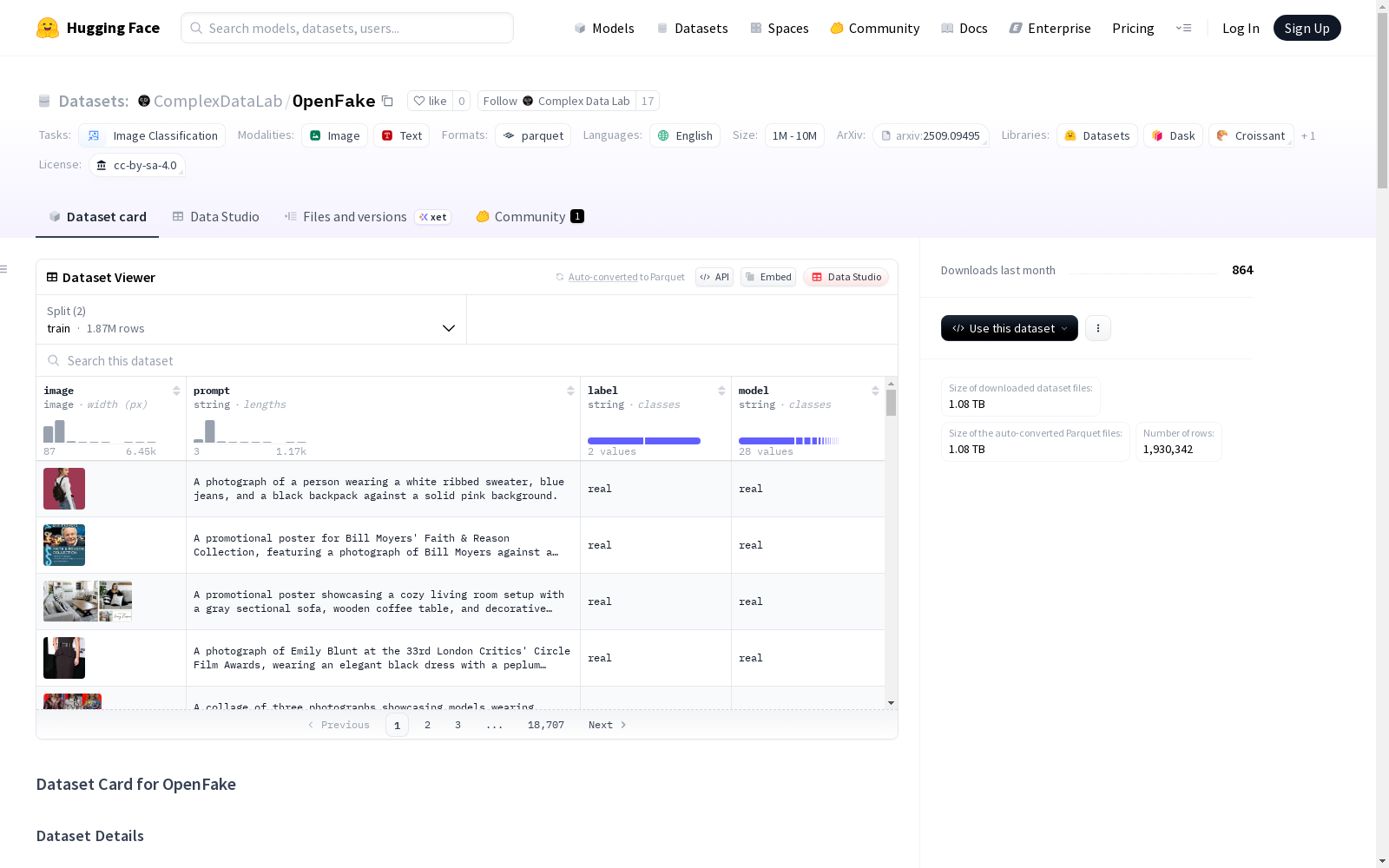
OpenFake 是一个专为评估深度伪造检测和错误信息缓解而设计的数据集,专注于政治相关媒体内容。它包含高分辨率的真实和合成图像,这些图像由具有政治相关性的提示生成,涵盖公众人物面孔、事件(如灾难、抗议)以及带有文本叠加的多模态模因风格图像。每张图像均附带结构化元数据,包括提示、来源模型(针对合成图像)以及人工标注或流程分配的标签。
- 作者:Victor Livernoche;Akshatha Arodi;Andreea Musulan;Zachary Yang;Adam Salvail;Gaétan Marceau Caron;Jean-François Godbout;Reihaneh Rabbany
- 策划者:Victor Livernoche;Akshatha Arodi;Jie Zang
- 资助方:CIFAR AI Chairs Program;Centre for the Study of Democratic Citizenship (CSDC);IVADO;Canada First Research Excellence Fund;Mila(资金支持和计算资源)
- 语言(提示):英语
- 许可证:CC-BY-SA-4.0(注意:由于“非竞争”条款,使用专有生成器产生的子集仅限非商业用途;详见论文)
数据集来源
- 代码库:https://huggingface.co/datasets/ComplexDataLab/OpenFake
- 竞技场(众包对抗平台):https://huggingface.co/spaces/CDL-AMLRT/OpenFakeArena
用途
直接用途
- 基准测试二分类器以检测真实与合成图像
- 评估跨模型和内容类型(面孔、事件、模因)的鲁棒性
- 通过社区提交(OpenFake Arena)训练对抗性鲁棒检测器
超范围用途
- 未经同意直接使用数据集训练生成模型
- 任何违反平台规则或隐私的个人图像使用
数据集结构
- image:图像(真实或合成)
- label:
real或fake - model:生成合成图像的模型
- prompt:用于生成合成图像的提示或真实图像的标题
训练/测试分割按标签平衡,并策划以确保视觉和主题多样性。分割间无图像重叠。
未使用的元数据:unused_metadata.csv 包含未包含在训练/测试分割中的图像的 URL 和提示。
覆盖的模型
合成图像由多种先进生成器生成,包括:
- Stable Diffusion 1.5、2.1、XL、3.5
- Flux 1.0-dev、1.1-Pro、1.0-Schnell
- Midjourney v6、v7
- DALL·E 3、Imagen 3、Imagen 4
- GPT Image 1、Ideogram 3.0、Grok-2、HiDream-I1、Recraft v3、Chroma
- 外加 10 个社区 LoRA/微调变体的 SD 1.5/XL 和 Flux-dev
所有图像均以约 1 MP 分辨率生成,具有反映常见社交媒体格式的多种宽高比。
数据集创建
策划理由
旨在填补深度伪造检测数据集的空白,涵盖高质量、政治敏感的合成图像,并超越仅面部基准,包括事件和混合图像文本模因。该数据集将约 300 万张政治主题真实图像(使用 Qwen2.5-VL 从 LAION-400M 过滤)与约 96.3 万张合成对应图像配对,并辅以 OpenFake Arena 进行持续硬负样本生成。
源数据
- 真实图像:从 LAION-400M 中筛选,并使用 Qwen2.5-VL 过滤以保留面孔和政治显著或新闻价值事件。生成详细标题以驱动文本到图像生成和竞技场提示。
- 合成图像:使用上述模型列表从共享提示库生成。开源模型遵循文档化的生成设置以确保可重现性。
源数据生产者
- 真实图像:新闻媒体、政治用户和公共社交媒体帖子
- 合成图像:由研究人员和社区贡献者从提示生成;竞技场提交通过 CLIP 进行提示相关性门控,并记录元数据
个人和敏感信息
源数据经过过滤以减少个人或敏感内容;详见论文的道德和许可说明。
偏见、风险和局限性
由于源数据分布,可能存在西方政治事件的过度代表。合成示例继承生成器偏见。并非所有标签都经过详尽的人工验证。对抗性使用是一种风险,通过许可和数据集专注于检测来缓解。
建议
解释图像中的政治叙事时需谨慎。未经额外审查,不得用于内容生成或面部身份研究。
引用
BibTeX: bibtex @misc{livernoche2025openfakeopendatasetplatform, title={OpenFake: An Open Dataset and Platform Toward Large-Scale Deepfake Detection}, author={Victor Livernoche and Akshatha Arodi and Andreea Musulan and Zachary Yang and Adam Salvail and Gaétan Marceau Caron and Jean-François Godbout and Reihaneh Rabbany}, year={2025}, eprint={2509.09495}, archivePrefix={arXiv}, primaryClass={cs.CV}, url={https://arxiv.org/abs/2509.09495}, }
APA: Livernoche, V., Arodi, A., Musulan, A., Yang, Z., Salvail, A., Marceau Caron, G., Godbout, J.-F., & Rabbany, R. (2025). OpenFake: An open dataset and platform toward large-scale deepfake detection. arXiv. https://arxiv.org/abs/2509.09495
更多信息
有关问题、错误或贡献,请访问 GitHub 或 HF 代码库。
数据集卡片作者
Victor Livernoche
数据集卡片联系人
victor.livernoche@mail.mcgill.ca