SurveillanceVQA-589K
收藏arXiv2025-05-19 更新2025-05-21 收录
下载链接:
https://huggingface.co/datasets/fei213/SurveillanceVQA-589K
下载链接
链接失效反馈官方服务:
资源简介:
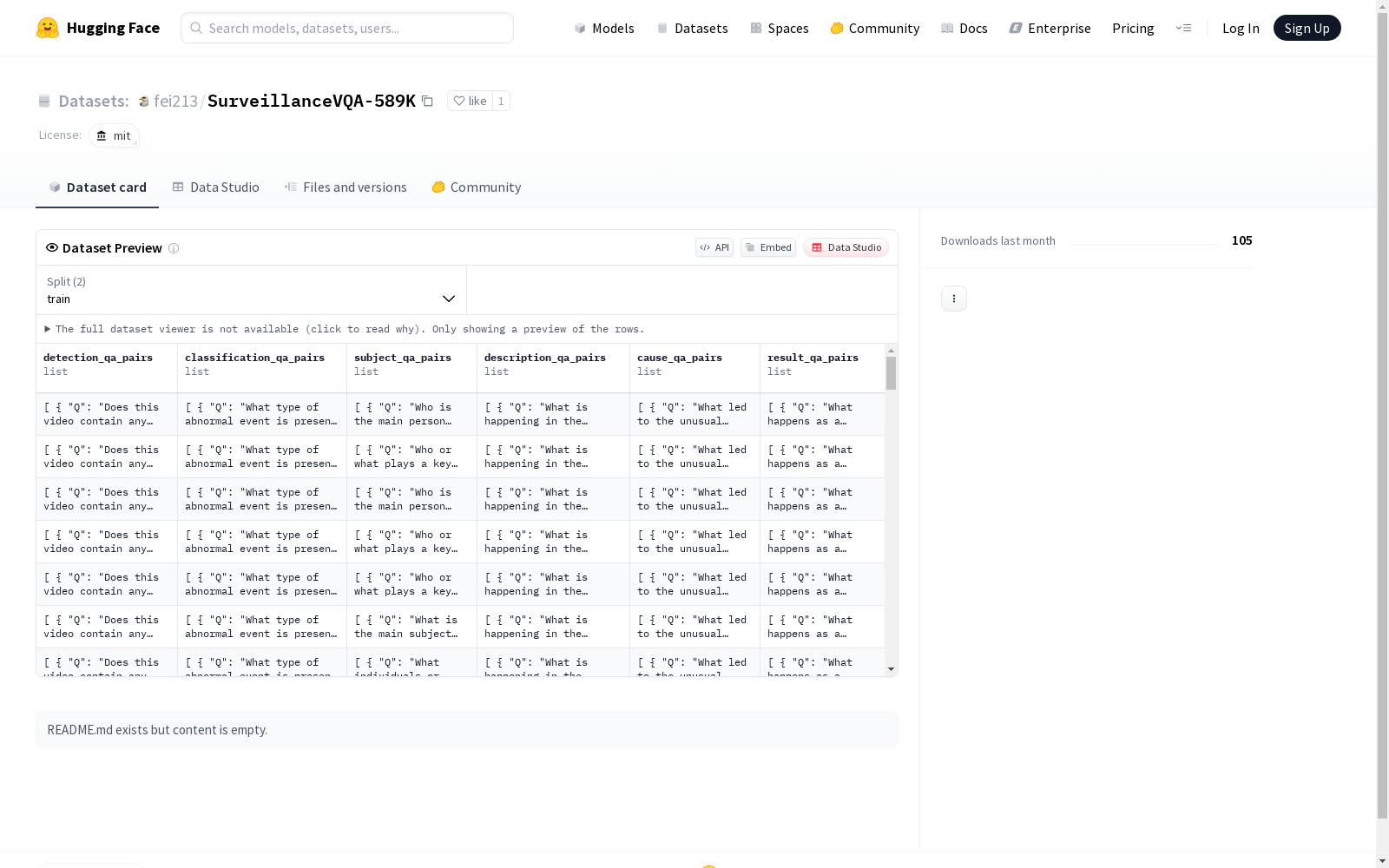
SurveillanceVQA-589K 是迄今为止最大的面向监控领域的开放性视频问答(VQA)基准数据集,包含 589,380 个问答对,跨越 12 种认知多样的问题类型,涵盖正常和异常视频场景。该数据集由北京工业大学计算机科学系、浪潮电子信息产业股份有限公司、清华大学电子工程系和京东探索学院的研究团队构建,旨在推动视频语言理解在智能监控、事件分析和自主决策等安全关键应用领域的进步。数据集和代码在 Hugging Face 平台上公开可用,为研究人员提供了一个实用且全面的资源。
SurveillanceVQA-589K is the largest open-ended video question answering (VQA) benchmark dataset tailored for the surveillance domain to date. It contains 589,380 question-answer pairs, spanning 12 cognitively diverse question types and covering both normal and abnormal video scenarios. This dataset was constructed by research teams from the Department of Computer Science of Beijing University of Technology, Inspur Electronics Information Industry Co., Ltd., Department of Electronic Engineering of Tsinghua University, and JD Explore Academy. It aims to advance the progress of video-language understanding in safety-critical application domains such as intelligent surveillance, event analysis, and autonomous decision-making. The dataset and accompanying code are publicly available on the Hugging Face platform, providing researchers with a practical and comprehensive resource.
提供机构:
北京工业大学 计算机科学系, 浪潮电子信息产业股份有限公司, 清华大学 电子工程系, 京东探索学院
创建时间:
2025-05-19
搜集汇总
数据集介绍
构建方式
SurveillanceVQA-589K数据集的构建采用了混合标注流程,结合了人工标注和大型视觉语言模型(LVLM)辅助的问答生成技术。首先,通过人工标注生成时间对齐的详细事件描述,随后利用LVLM对视频片段进行深度分析,生成补充性的描述内容。最后,通过高级语言模型Qwen-Turbo对人工和模型生成的描述进行语义整合与优化,形成31,548条精细化文本标注。在此基础上,针对正常与异常视频片段设计了12类问答任务,利用Qwen-Max模型自动生成共计589,380对问答数据,确保了数据集的多样性与语义深度。
特点
该数据集作为目前规模最大的监控视频问答基准,具有三个显著特征:认知多样性覆盖12类问答任务,包括时空推理、因果推断等高级语义理解;场景完备性包含27,966条正常视频和3,585条异常视频片段,涵盖18类异常事件;技术融合性创新采用人机协同标注范式,结合人工精确性与模型扩展性。特别设计的多维度评估协议(上下文整合、细节导向等)为模型性能提供立体化测评框架,其异常事件问答中仅1.8%的因果推理正确率揭示了当前模型的认知瓶颈。
使用方法
使用该数据集时需遵循三阶段流程:预处理阶段需按8:2比例划分视频片段级训练测试集;模型训练阶段建议采用多任务学习框架,同步优化正常场景描述与异常事件推理能力;评估阶段推荐使用GLM-4-Flash模型进行四维度(CI/DO/CU/TU)的LLM-based自动化测评。对于异常分析任务,可重点考察模型在Detection与Classification QA的F1值,而时空推理任务则应关注Temporal QA中时序逻辑的连贯性。数据集的层级化标注结构支持从事件描述到复杂推理的渐进式研究。
背景与挑战
背景概述
SurveillanceVQA-589K是由北京工业大学等机构的研究团队于2025年推出的首个面向监控视频领域的大规模开放式视频问答基准数据集。该数据集包含31,548个视频片段和589,380个问答对,涵盖12种认知多样的问题类型,包括时空推理、因果推断和异常解析等。作为目前规模最大的监控视频语言理解数据集,它通过融合人工标注与大型视觉语言模型生成技术,构建了覆盖正常与异常场景的综合性评估体系。该数据集的建立填补了传统监控视频分析在语义推理和交互式问答评估方面的空白,为智能监控、事件分析和自主决策等安全关键应用提供了重要的研究基础。
当前挑战
SurveillanceVQA-589K主要解决监控视频领域的两大核心挑战:在领域问题层面,传统方法难以处理真实场景中的复杂事件动态和低频率异常检测,该数据集通过12类认知任务系统评估模型在时空推理和因果分析等高级语义理解能力;在构建过程中,研究团队面临视频数据高度异构性(包括昼夜变化、天气差异和多变环境)以及异常事件突发性和多样性的标注难题,为此创新性地设计了融合人工精标与LVLM辅助生成的混合标注流程。当前基准测试显示,即使是7B参数的大模型在异常相关任务(如因果推理)上的平均得分仍低于中位水平,凸显了现实监控场景下模型推理能力的局限性。
常用场景
经典使用场景
SurveillanceVQA-589K数据集在监控视频理解领域具有广泛的应用价值,尤其在智能监控和异常事件检测方面表现突出。该数据集通过提供589,380个问答对,覆盖了12种不同类型的认知任务,包括时间推理、因果推断、空间理解和异常解释等,为研究人员提供了一个全面的基准测试平台。其经典使用场景包括监控视频的语义理解、异常行为检测以及多模态推理任务。
解决学术问题
SurveillanceVQA-589K数据集解决了监控视频领域中的多个关键学术问题。首先,它填补了现有数据集中缺乏大规模、多样化问答对的空白,为视频问答任务提供了丰富的标注数据。其次,该数据集通过引入异常事件检测和因果推理任务,推动了监控视频中复杂语义理解的研究。此外,其多维度评估协议为模型在上下文、时间和因果理解方面的性能提供了系统化的评测标准。
衍生相关工作
SurveillanceVQA-589K数据集衍生了一系列相关研究工作,特别是在多模态大模型(LVLM)的评测与优化方面。基于该数据集,研究人员提出了多种视频语言理解框架,如LLaVA-Video和VideoLLaMA系列模型,进一步推动了监控视频语义理解的发展。此外,该数据集还促进了异常检测算法的创新,例如结合因果推理的异常事件分析方法,为后续研究提供了重要参考。
以上内容由遇见数据集搜集并总结生成


