imagenet
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://huggingface.co/datasets/wittenator/imagenet
下载链接
链接失效反馈官方服务:
资源简介:
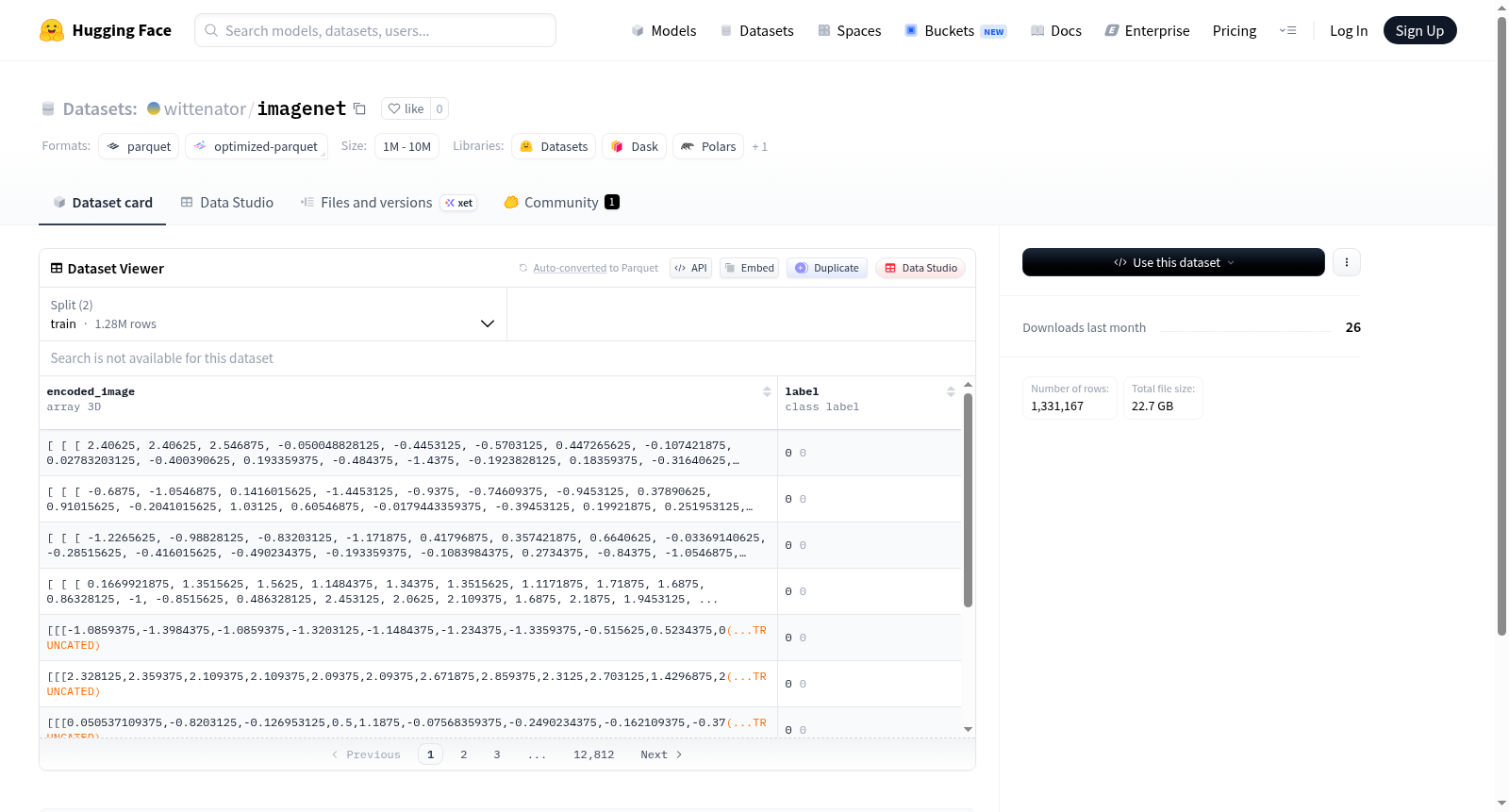
该数据集名为madebyollin~sdxl-vae-fp16-fix,包含两个主要特征:encoded_image和label。encoded_image是一个形状为[4, 32, 32]的浮点型三维数组,表示经过编码的图像数据。label是一个类别标签,包含从0到867共868个类别,适用于多类别分类任务。数据集的来源、规模及具体应用场景未在README中说明。
创建时间:
2026-04-30
原始信息汇总
根据您提供的README文件内容,数据集详情总结如下:
数据集名称
wittenator/imagenet
配置信息
- 配置名称: madebyollin~sdxl-vae-fp16-fix
特征字段
该数据集包含以下两个特征字段:
-
encoded_image(编码图像)
- 数据类型: 三维数组(array3_d)
- 形状:
[4, 32, 32] - 数据类型:
float32(32位浮点数)
-
label(标签)
- 数据类型: 类别标签(class_label)
- 类别数量: 868个类别(标签编号从
0到867),每个类别名称与编号相同(例如,类别0的名称为0,以此类推)。
搜集汇总
数据集介绍
构建方式
ImageNet数据集作为计算机视觉领域的里程碑式资源,其构建过程凝聚了大规模人工标注与精细类别划分的智慧。该数据集以WordNet层次结构为骨架,收集了超过1400万张涵盖2万多个类别的图像,每张图像均经过严格的人工审核与标签校准。具体而言,构建团队首先从互联网海量图片中筛选出符合类别定义的样本,随后通过众包平台邀请标注者对图像内容进行验证,确保每个类别下图像的质量与多样性。
特点
ImageNet数据集的显著特征在于其极致的规模与结构化的语义体系。它覆盖了从日常生活物品到稀有动植物的广泛视觉概念,每个类别都包含数百至数千张高质量图像,为深度学习模型提供了丰富的训练素材。该数据集内图像的多视角、多背景与多光照条件,使得训练出的模型具备强大的泛化能力,成为物体识别、图像分类等任务的黄金基准。
使用方法
研究者可通过HuggingFace等平台便捷获取该数据集的多种预配置版本,例如针对Stable Diffusion模型优化后的变体。数据集以标准的训练/验证/测试划分形式提供,用户可直接利用torchvision、tensorflow-datasets等库加载图像及对应标签。在使用时,开发者常对图像进行缩放、归一化等预处理操作,随后将其输入ResNet、ViT等经典架构进行模型训练或微调,以推动计算机视觉前沿研究的持续突破。
背景与挑战
背景概述
ImageNet数据集由斯坦福大学李飞飞团队于2009年创建,旨在为大规模视觉识别任务提供基准。该数据集包含超过1400万张手工标注的图像,覆盖2万多个类别,其核心研究问题在于推动图像分类与目标检测技术的发展。ImageNet的诞生填补了当时缺乏大规模、高质量标注图像数据集的空白,成为深度学习革命的催化剂,尤其通过ImageNet大规模视觉识别挑战赛(ILSVRC)深刻影响了计算机视觉领域的研究范式与模型演进。
当前挑战
ImageNet所解决的领域核心挑战是图像分类的规模与泛化问题,即如何在数以万计的类别和百万级图像中实现准确且鲁棒的视觉识别。构建过程中面临的主要挑战包括:海量图像的收集与清洗,确保图像质量和类别平衡;精确的人工标注,需要大量标注者在细粒度类别间进行区分;以及数据集的持续维护与更新,以反映视觉概念的演变。这些挑战驱动了众包标注、高效数据管理及自动化质量审核等技术的创新。
常用场景
经典使用场景
在计算机视觉研究的深邃图景中,ImageNet以其宏大的规模和精细的类别体系,成为了图像分类任务最经典的应用温床。该数据集涵盖超过一千个物体类别,囊括了从日常器物到珍稀动物的广泛视觉概念,为深度学习模型提供了近乎无穷尽的训练素材。研究者常以ImageNet作为基准,评估卷积神经网络乃至更前沿的视觉Transformer架构在分类精准度上的表现。无论是经典的AlexNet、VGGNet,还是后来居上的ResNet与EfficientNet,其性能的巅峰较量均在ImageNet的舞台上展开。因此,该数据集不仅是算法进步的试金石,更推动了图像识别技术从理论走向成熟,深刻影响了整个计算机视觉领域的演进轨迹。
衍生相关工作
以ImageNet为基石,学术界衍生出众多影响深远的经典工作,极大地拓宽了计算机视觉研究的疆域。ILSVRC(ImageNet大规模视觉识别挑战赛)曾长期引领图像分类、目标检测与图像分割等方向的创新浪潮,催生了诸如AlexNet、VGGNet、GoogLeNet与ResNet等里程碑式架构。这些网络不仅推动了深度学习的革命性发展,其设计思想亦被后续研究者广泛借鉴。此外,基于ImageNet的预训练-微调范式成为迁移学习的标准流程,孕育出Mask R-CNN、YOLO等高性能检测与分割模型。ImageNet预训练权重如今更是各类视觉Transformer模型(如ViT、Swin Transformer)的初始化关键,持续塑造着现代视觉人工智能的演化轨迹。
数据集最近研究
最新研究方向
基于ImageNet数据集的深度学习研究正朝着多模态与生成式模型深度融合的方向演进。该数据集中包含的编码图像特征(如本配置中32x32的潜空间表示)被广泛应用于文本到图像生成领域,特别是与SDXL等扩散模型的结合,推动了高保真图像合成技术的发展。当前研究热点聚焦于利用ImageNet的类别标签和预训练特征,优化VAE的潜在编码质量,以提升生成图像的语义一致性和细节丰富度。这一趋势不仅强化了ImageNet作为视觉表征学习基准的核心地位,也为AI在艺术创作、虚拟内容生成等跨模态应用场景中提供了可靠的训练基石。
以上内容由遇见数据集搜集并总结生成


