UD_Spanish-AnCora
收藏UD_Spanish-AnCora 数据集概述
数据集描述
数据集摘要
该数据集由 AnCora 语料库 的标注组成,这些标注被映射到 通用依存树库。该语料库的词性标注被用作西班牙语基准测试 EvalEs 的一部分。
支持的任务与排行榜
- 词性标注
语言
数据集语言为西班牙语 (es-ES)。
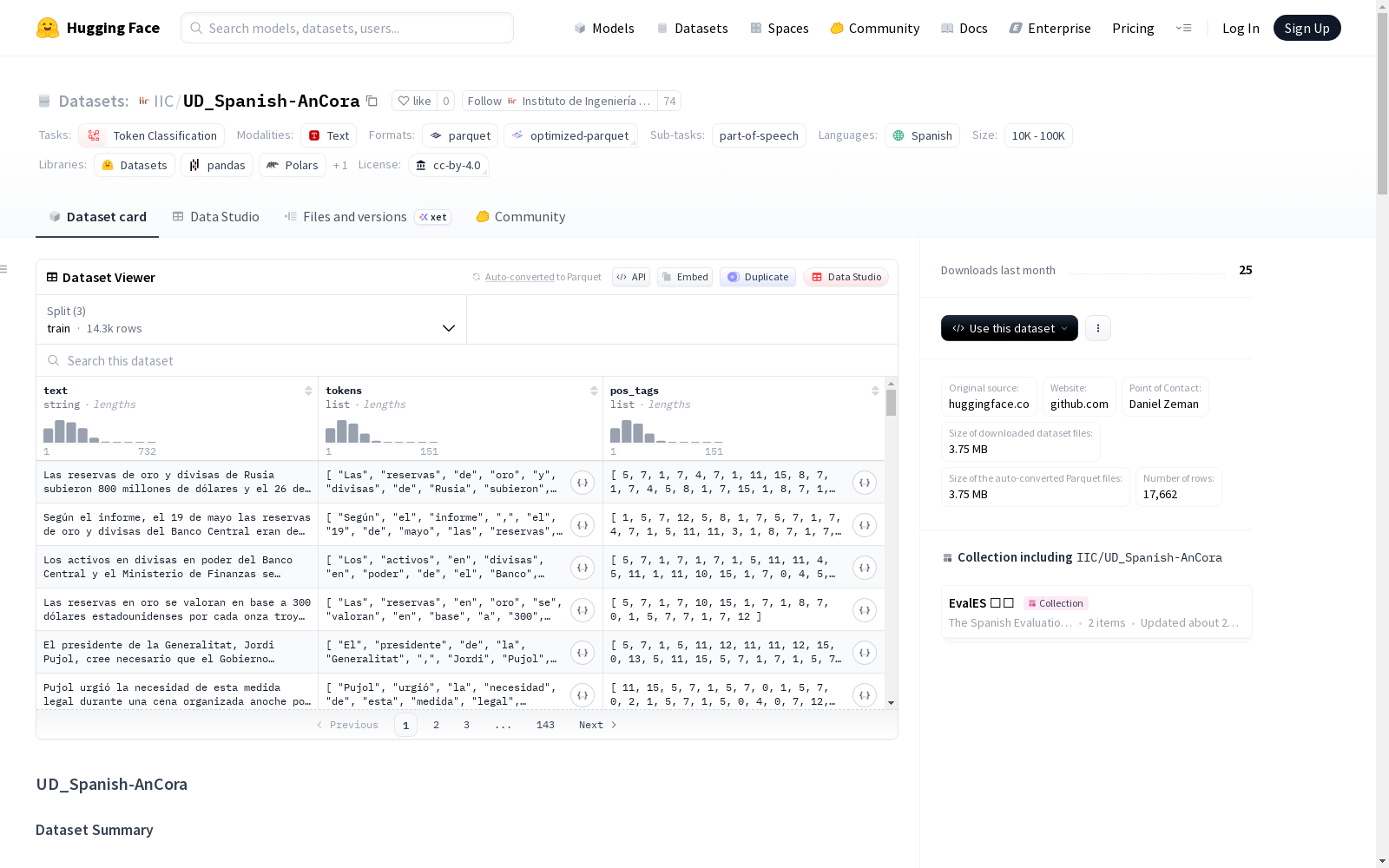
数据集结构
数据实例
数据以三个 CoNLL-U 格式文件提供。
数据字段
数据文件包含三种类型的行:
- 词行:包含一个词/标记的标注,由10个字段组成,字段间用制表符分隔。
- 空行:标记句子边界。
- 注释行:以井号 (#) 开头。
词行包含以下字段:
- ID:词索引,每个新句子从整数1开始;对于多词标记可能是一个范围;对于空节点可能是一个十进制数。
- FORM:词形或标点符号。
- LEMMA:词形的词元或词干。
- UPOS:通用词性标签。
- XPOS:语言特定的词性标签;不可用时为下划线。
- FEATS:来自通用特征集或已定义的语言特定扩展的形态特征列表;不可用时为下划线。
- HEAD:当前词的头部,是ID的值或零 (0)。
- DEPREL:与HEAD的通用依存关系(若HEAD=0则为root)或已定义的语言特定子类型。
- DEPS:增强依存图,形式为头部-依存关系对的列表。
- MISC:任何其他标注。
数据划分
数据集包含以下三个划分:
- 训练集:
es_ancora-ud-train.conllu - 验证集:
es_ancora-ud-dev.conllu - 测试集:
es_ancora-ud-test.conllu
划分统计信息:
- 训练集:14,287 个样本,10,005,508 字节
- 验证集:1,654 个样本,1,179,118 字节
- 测试集:1,721 个样本,1,184,940 字节
- 总数据集大小:12,369,566 字节
- 下载大小:3,754,217 字节
数据集创建
数据来源
- 原始来源:https://huggingface.co/datasets/PlanTL-GOB-ES/UD_Spanish-AnCora
- 项目网站:https://github.com/UniversalDependencies/UD_Spanish-AnCora
初始数据收集与标准化
原始标注是在巴塞罗那大学 AnCora 项目 的组成框架下完成的。随后由 通用依存团队 转换为依存关系格式,并用于 CoNLL 2009 共享任务。CoNLL 2009 版本后来被转换为 HamleDT 和通用依存格式。
标注
- 标注创建者:专家生成
- 标注过程:有关首次 AnCora 标注的更多信息,请访问 AnCora 网站。
个人与敏感信息
不包含个人或敏感信息。
使用注意事项
数据集的社会影响
该数据集有助于西班牙语语言模型的发展。
偏见讨论
未提供相关信息。
其他已知限制
未提供相关信息。
附加信息
许可信息
本作品采用 知识共享署名 4.0 国际许可协议 进行许可。
引用信息
使用本语料库时必须引用以下论文: Taulé, M., M.A. Martí, M. Recasens (2008) Ancora: Multilevel Annotated Corpora for Catalan and Spanish, Proceedings of 6th International Conference on Language Resources and Evaluation. Marrakesh (Morocco).
引用通用依存项目: Rueter, J. (Creator), Erina, O. (Contributor), Klementeva, J. (Contributor), Ryabov, I. (Contributor), Tyers, F. M. (Contributor), Zeman, D. (Contributor), Nivre, J. (Creator) (15 Nov 2020). Universal Dependencies version 2.7 Erzya JR. Universal Dependencies Consortium.
联系方式
- 联系人:Daniel Zeman (zeman@ufal.mff.cuni.cz)