The COW of Rembrandt
收藏数据集概述:The Cow of Rembrandt
研究背景
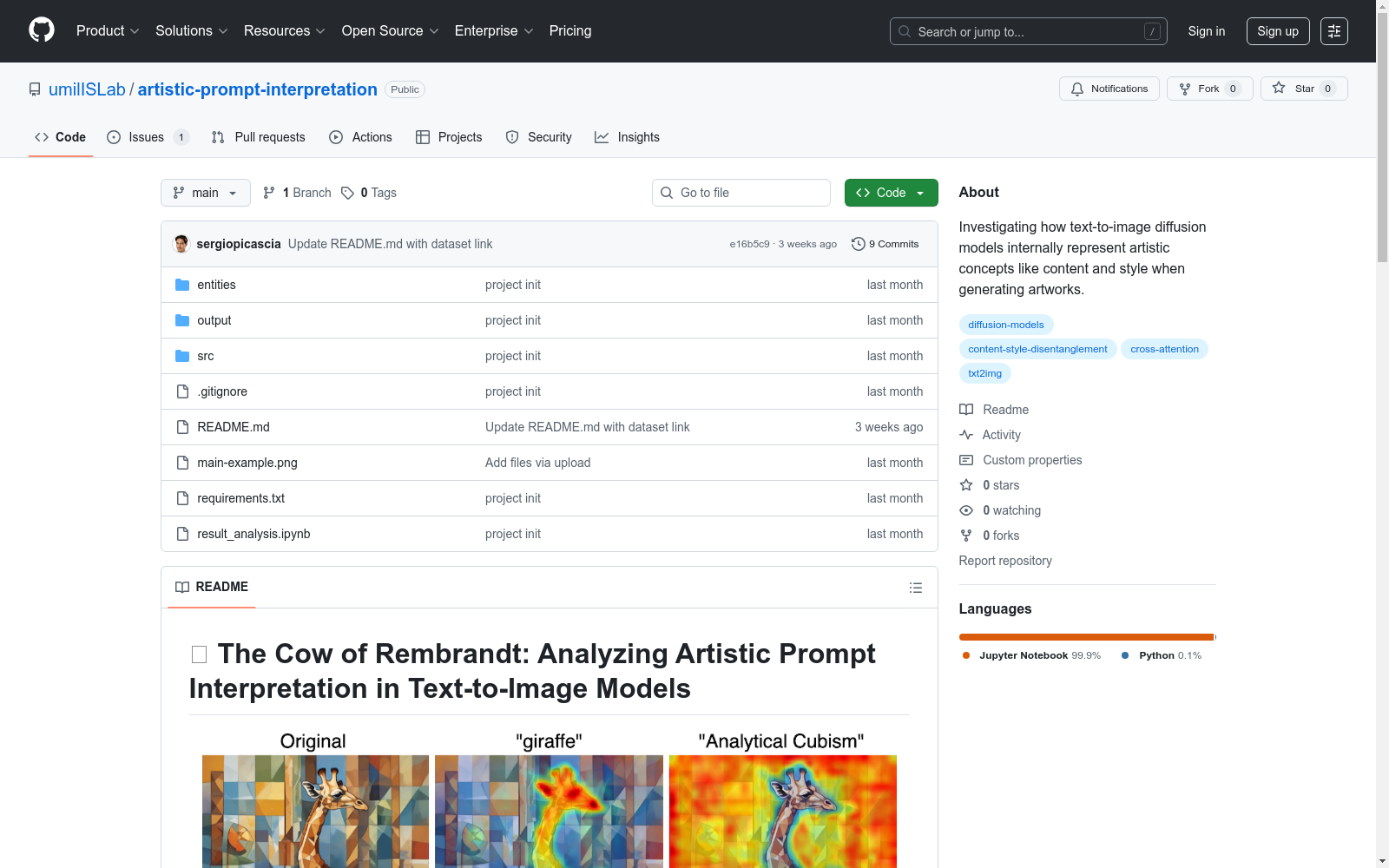
- 研究文本到图像扩散模型在生成艺术作品时如何内部表示艺术概念(如内容和风格)。
- 使用交叉注意力分析探讨模型如何分离提示中的内容描述和风格描述元素。
- 发现扩散模型表现出不同程度的内容-风格分离,内容标记通常影响对象区域,风格标记影响背景和纹理。
数据集内容
文件结构
├── entities/ # 用于填充提示模板的数据 ├── output/ # 实验结果 | ├── prompts.csv # 实验使用的提示 │ ├── content_style_iou_results.csv # 实验的IoU结果 ├── src/ # 源代码 │ ├── analysis_utils.py # 指标计算 │ ├── config.py # 实验设置 │ ├── data_utils.py # 提示处理 │ ├── main_exp.py # 主实验 │ ├── main_viz.py # 主可视化 │ └── model_utils.py # 模型设置 ├── result_analysis.ipynb # 用于复制绘图和分析的Jupyter笔记本 ├── requirements.txt # Python依赖项 └── README.md # 本文件
数据来源
- 对象:COCO标签
- 艺术家:ArtGAN WikiArt数据集
- 艺术运动:ArtGAN WikiArt数据集
数据可用性
- 完整提示和生成图像集可从Dataverse下载。
使用说明
环境要求
- Python 3.10.5
安装步骤
-
克隆仓库: bash git clone https://github.com/umilISLab/artistic-prompt-interpretation.git cd artistic-prompt-interpretation
-
创建虚拟环境: bash python -m venv venv source venv/bin/activate # Windows: venvScriptsactivate
-
安装依赖项: bash pip install -r requirements.txt
重现结果
运行以下命令: bash python src/main_exp.py python src/main_viz.py
可视化示例
- 生成图像示例可查看完整图像集。