AIAT/Pangpuriye-public_ThaiSum40k
收藏Hugging Face2024-05-06 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/AIAT/Pangpuriye-public_ThaiSum40k
下载链接
链接失效反馈官方服务:
资源简介:
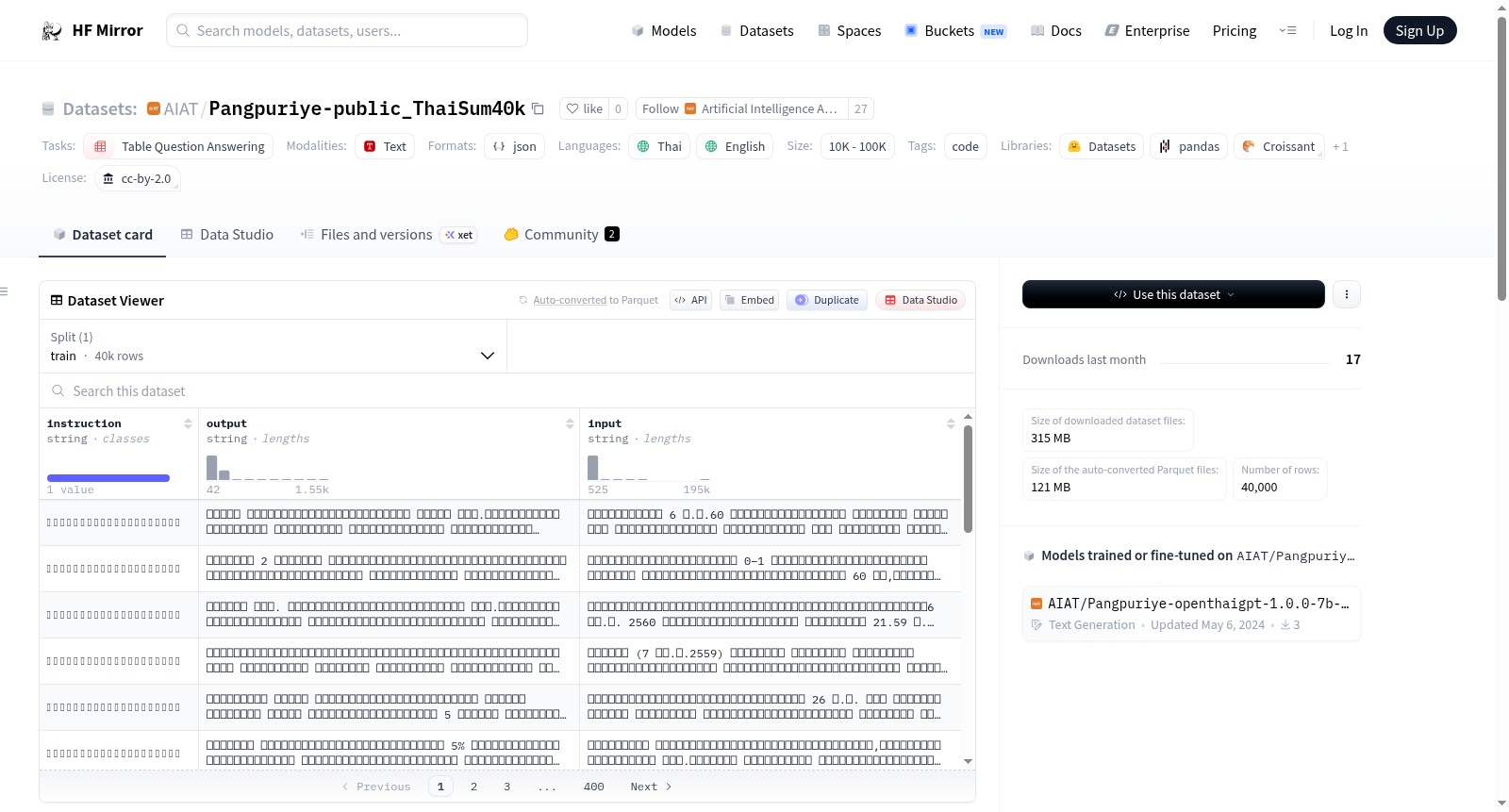
该数据集源自ThaiSum数据集,从中选取了40,000行数据,并使用了特定的指令进行修改。数据集包含泰语和英语,主要用于微调Panguriye的LLM,以缩短回答长度并定义逻辑摘要。数据集的使用有助于在微调阶段减少输出长度,并提高摘要的逻辑性。
该数据集源自ThaiSum数据集,从中选取了40,000行数据,并使用了特定的指令进行修改。数据集包含泰语和英语,主要用于微调Panguriye的LLM,以缩短回答长度并定义逻辑摘要。数据集的使用有助于在微调阶段减少输出长度,并提高摘要的逻辑性。
提供机构:
AIAT
原始信息汇总
数据集概述
基本信息
- 许可证: Creative Commons Attribution 2.0 (cc-by-2.0)
- 任务类别: 表格问题回答 (table-question-answering)
- 语言: 泰语 (th), 英语 (en)
- 标签: code
- 数据集名称: Thai-SQL_Question_generated_by_ThaiSum40k
- 大小类别: 10,000 < n < 100,000
数据集描述
- 原始数据集: 来源于 ThaiSum,包含380,868行数据,包括标题、正文和摘要,均为泰语。
- 修改后的数据集: 从原始数据集中选取40,000行数据,并使用
จงสรุปเรื่องต่อไปนี้作为指令。输入为给定上下文,输出为该上下文的摘要版本。 - 用途: 用于微调指令调优的大型语言模型 (LLM),旨在缩短答案长度并定义逻辑摘要。
调用示例
python from datasets import load_dataset
dataset = load_dataset("AIAT/Pangpuriye-public_ThaiSum40k")
引用信息
- 参考文献: 请参考原始数据集的论文 https://huggingface.co/datasets/thaisum
@mastersthesis{chumpolsathien_2020, title={Using Knowledge Distillation from Keyword Extraction to Improve the Informativeness of Neural Cross-lingual Summarization}, author={Chumpolsathien, Nakhun}, year={2020}, school={Beijing Institute of Technology}
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量的数据集是模型训练的关键。本数据集基于原始ThaiSum数据集构建,该数据集包含超过38万条泰语新闻文本,涵盖标题、正文和摘要。构建过程中,研究团队从中精选了4万条样本,并采用指令微调策略,为每条数据添加了“จงสรุปเรื่องต่อไปนี้”作为指令提示。输入部分为原始文本内容,输出则对应其人工撰写的摘要,旨在通过结构化设计提升模型生成简洁且逻辑连贯摘要的能力。
特点
该数据集以泰语为核心语言,专注于文本摘要任务,具有鲜明的领域特色。其特点在于规模适中且经过精心筛选,确保了数据质量与代表性。每条数据均包含明确的指令-输入-输出三元组结构,便于指令微调训练。数据来源于真实新闻文本,摘要由人工撰写,保证了内容的准确性与语言的自然流畅。这种设计不仅支持模型学习摘要生成,还能有效控制输出长度,提升生成结果的逻辑性与信息密度。
使用方法
在应用层面,该数据集主要用于训练或微调大型语言模型,特别是针对泰语文本摘要任务。使用者可通过Hugging Face的`datasets`库直接加载,代码简洁明了。数据集适用于监督式学习框架,模型以指令和原文为输入,以生成摘要为目标进行优化。它可集成于完整的训练流水线中,作为微调阶段的关键数据源,帮助模型掌握生成凝练、信息丰富的泰语摘要技能,进而应用于新闻聚合、内容精简等实际场景。
背景与挑战
背景概述
在自然语言处理领域,泰语文本资源的稀缺性长期制约着相关模型的发展。AIAT/Pangpuriye-public_ThaiSum40k数据集应运而生,其核心源自2020年Nakhun Chumpolsathien于北京理工大学完成的硕士研究中所构建的ThaiSum数据集。该数据集由泰国人工智能技术协会(AIAT)在“超级AI工程师发展计划第四季”项目框架下,通过Pangpuriye团队进行二次加工与发布。其核心研究问题聚焦于提升泰语文本的自动摘要生成能力,旨在通过提供高质量的指令微调数据,增强大语言模型对泰语信息的凝练与逻辑概括性能,对推动泰语自然语言处理技术的本土化应用具有显著影响力。
当前挑战
该数据集致力于应对泰语自动文本摘要领域的核心挑战,即如何在保留原文关键信息与语义连贯性的前提下,生成简洁且信息密度高的摘要。这一任务因泰语复杂的语法结构与语境依赖性而尤为困难。在构建过程中,挑战主要体现于数据工程的精炼:需从原始庞大的38万余条数据中,筛选出具有代表性的4万条样本,并设计统一的指令模板(如“จงสรุปเรื่องต่อไปนี้”)以构建标准化的指令微调格式。此过程需平衡数据规模与质量,确保子集能有效涵盖原始数据的语言特征与摘要模式,同时适配下游大语言模型的微调需求,避免信息损失或引入偏差。
常用场景
经典使用场景
在泰语自然语言处理领域,AIAT/Pangpuriye-public_ThaiSum40k数据集为文本摘要任务提供了经典范例。该数据集源自ThaiSum原始语料,通过精选四万条泰语新闻文本构建指令微调格式,以“จงสรุปเรื่องต่อไปนี้”为指令引导模型生成摘要。这一设计使数据集成为训练语言模型进行信息压缩与逻辑归纳的核心资源,尤其在提升模型对长文本的概括能力方面展现出显著价值。
衍生相关工作
围绕该数据集衍生的经典工作包括Pangpuriye系列语言模型的指令微调实践。研究团队基于该数据对OpenThaiGPT模型进行优化,显著提升了模型生成简洁摘要的能力。相关技术方案为后续泰语大语言模型的开发提供了重要参考,同时启发了对东南亚语言进行知识蒸馏、跨语言迁移学习等方向的方法创新,形成了具有区域特色的技术发展路径。
数据集最近研究
最新研究方向
在自然语言处理领域,泰语文本摘要任务因语言资源的稀缺性而备受关注。AIAT/Pangpuriye-public_ThaiSum40k数据集基于ThaiSum构建,专注于指令微调,为泰语大语言模型的优化提供了关键支持。当前研究前沿集中于利用此类指令化摘要数据提升模型在低资源语言中的逻辑归纳与信息压缩能力,尤其在跨语言摘要与知识蒸馏技术的结合上展现出潜力。该数据集的发布促进了泰语NLP社区的发展,为多语言模型在东南亚地区的应用奠定了数据基础,推动了语言智能技术的包容性进步。
以上内容由遇见数据集搜集并总结生成


