Myanmar-G12L-Benchmark
收藏Hugging Face2025-05-15 更新2025-05-16 收录
下载链接:
https://huggingface.co/datasets/Rickaym/Myanmar-G12L-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
缅甸语文学考试题目数据集,包含简答题、是非题、隐喻分析、填空题、选择题、长篇回应和意义解释等多种形式的题目,用于评估和加强正式文学知识。数据集以Apache 2.0许可证发布。
创建时间:
2025-05-09
原始信息汇总
Myanmar G12L Benchmark 数据集概述
基本信息
- 数据集名称: Myanmar G12L Benchmark
- 语言: 缅甸语 (Burmese)
- 许可证: Apache 2.0
- 数据规模: 小于1K样本
- 下载大小: 469,838字节
- 数据集大小: 1,643,102字节
数据集详情
- 用途: 评估和加强缅甸语文学知识的综合工具
- 问题类型: 包括简答题、判断题、隐喻分析、填空题、多选题、长回答题和意义解释题
- 来源: 从过去的考试试卷和权威考试指南中提取
数据集结构
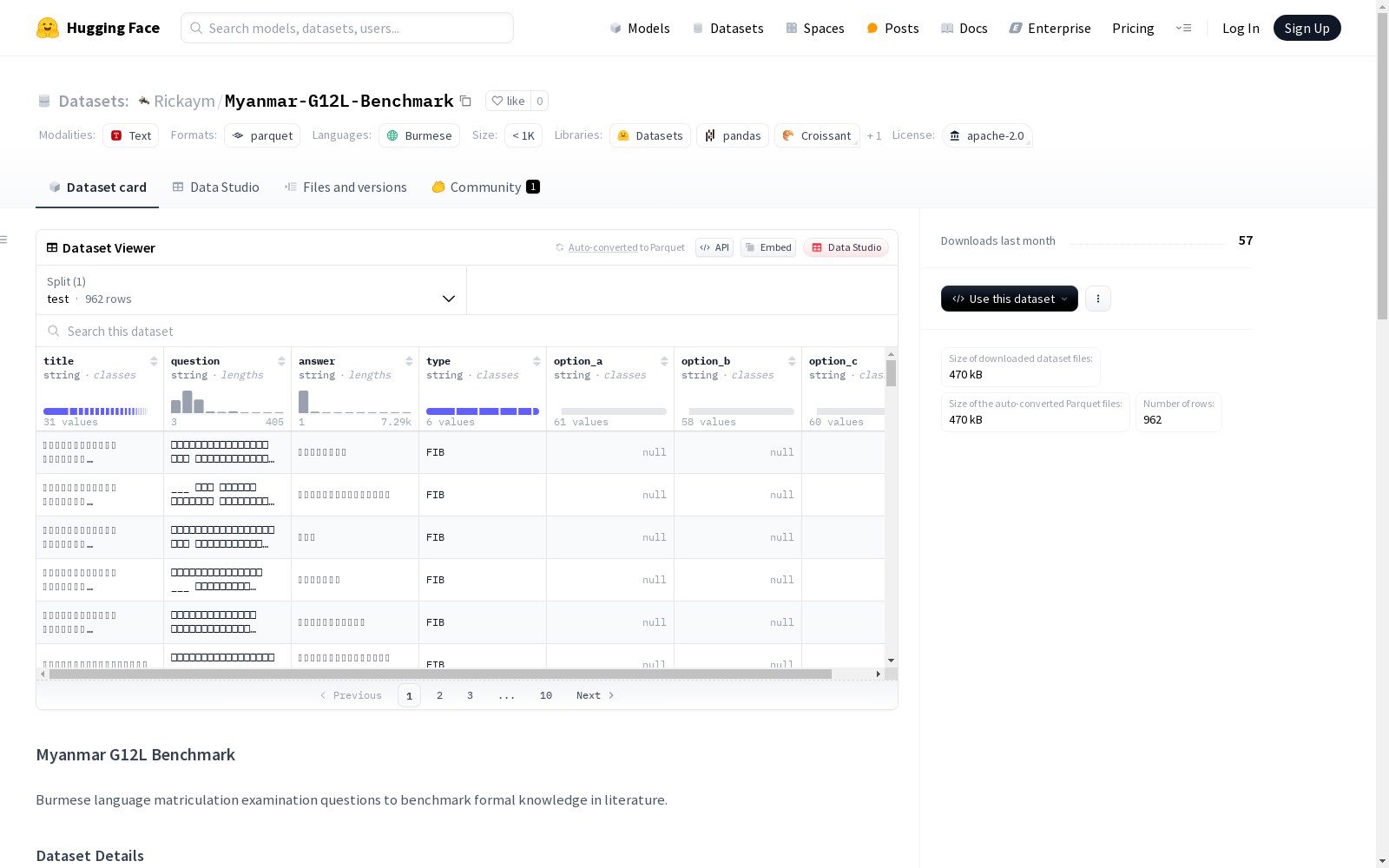
- 特征:
title: 问题的简要非唯一标识符question: 完整的问题或题干answer: 正确答案type: 问题类型 (MCQ,TOF,FIB,SHORT_QNA,LONG_QNA,MEANING_QNA,METAPHOR_QNA)option_a,option_b,option_c: 多选题的干扰项(仅当type = MCQ时填充)
- 分割:
test: 962个样本,1,643,102字节
数据收集与处理
- Google Document OCR
- 手动提取和校正
评估
-
工具: Aya Myanmar Toolkit (
ayamytk) -
安装: py !pip install git+https://github.com/Rickaym/aya-my-tk
-
评估代码示例: py from ayamytk.test.bench import evals from ayamytk.test.bench.sampler.custom_sampler import CustomSampler
def chat(messages):
添加推理代码
return ...
evals.run(models={"your-model": CustomSampler(call=chat)}, evals="exam")
局限性与风险
- 局限性: 仅涵盖缅甸语文学科目的考试内容
搜集汇总
数据集介绍
构建方式
缅甸G12L基准数据集通过系统化流程构建,其核心内容源自缅甸高中毕业考试(Matriculation Examination)的文学科目真题。研究团队采用谷歌文档OCR技术对历史试卷进行数字化处理,随后通过人工校验确保题目与答案的准确性。数据采集过程严格遵循教育测量学标准,涵盖选择题、判断题、隐喻分析等七种题型,每种题型均保留原始考试的结构特征。为保障数据权威性,所有题目均选自官方考试指南和历年真题,并由缅甸语言教育专家团队进行多轮校对。
特点
该数据集作为缅甸语文学能力评估的专业工具,具有鲜明的领域特性。962条数据样本完整覆盖高中文学课程的认知维度,从基础记忆到高阶分析能力均有体现。题型设计上包含客观题(MCQ、TOF)和主观题(LONG_QNA、METAPHOR_QNA)的平衡分布,选项字段采用动态存储策略以优化数据结构。特别值得注意的是隐喻分析题型,这类文化特定项目能够有效检测模型对缅甸文学修辞手法的理解深度。数据标注采用严格的考试评分标准,正确答案经过教育专家共识验证。
使用方法
使用该数据集需配合专用评估工具包aya-my-tk,其标准化接口支持各类模型的文学能力测评。实施评估时,开发者需构建符合messages格式的对话函数处理题目输入,工具包会自动计算模型在七类题型上的准确率。对于非选择题型,评估模块内置了基于关键词匹配的评分规则。建议在fine-tuning过程中注意题型分布特征,特别是隐喻分析和长问答等复杂题型的数据增强。数据集采用Apache 2.0协议,允许研究者自由修改评估流程以适应不同的NLP模型架构。
背景与挑战
背景概述
Myanmar-G12L-Benchmark数据集由Pyae Sone Myo、Min Thein Kyaw、May Myat Noe Aung和Arkar Zaw等研究人员共同构建,旨在为缅甸语文学领域提供一个标准化的评估工具。该数据集收录了缅甸高中毕业考试(matriculation examination)中的文学类题目,涵盖多种题型,包括简答题、判断题、隐喻分析、填空题、选择题、长回答题和意义解释题。这些题目均来源于历年考试真题和权威考试指南,具有较高的学术价值和代表性。该数据集的建立不仅为缅甸语自然语言处理研究提供了宝贵的资源,也为教育领域的自动评估系统开发奠定了基础。
当前挑战
Myanmar-G12L-Benchmark数据集面临的挑战主要包括两个方面。首先,在领域问题方面,缅甸语作为一种低资源语言,其文学类题目的自动理解和生成任务具有较高的复杂性,尤其是隐喻分析和意义解释等题型,需要模型具备深厚的语言理解和文化背景知识。其次,在数据构建过程中,由于原始题目多为纸质文档,需要通过OCR技术进行数字化,随后还需人工校对和修正,这一过程耗时耗力且容易引入误差。此外,数据集目前仅涵盖文学类题目,未能全面反映缅甸高中毕业考试的其他学科内容,限制了其应用范围。
常用场景
经典使用场景
在缅甸语文学教育领域,Myanmar-G12L-Benchmark数据集作为标准化评估工具,主要用于测试学生对缅甸文学知识的掌握程度。该数据集通过多种题型设计,如选择题、填空题和简答题等,全面覆盖了文学分析的各个层面,为教育工作者提供了一个可靠的测评框架。
实际应用
在实际应用中,Myanmar-G12L-Benchmark数据集被广泛应用于缅甸语文学课程的测评和教学改进。教育机构利用该数据集进行学生能力评估,识别教学中的薄弱环节,从而有针对性地调整教学内容。同时,该数据集也为自动化测评系统的开发提供了重要支持。
衍生相关工作
基于Myanmar-G12L-Benchmark数据集,研究者们开发了多种缅甸语文学测评工具和方法。例如,Aya Myanmar Toolkit (ayamytk) 的推出,为自动化测评提供了技术基础。这些衍生工作不仅扩展了数据集的应用范围,也为缅甸语文学教育的技术创新奠定了基础。
以上内容由遇见数据集搜集并总结生成


