Formosa-bench
收藏Hugging Face2024-11-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/lianghsun/Formosa-bench
下载链接
链接失效反馈官方服务:
资源简介:
福爾摩沙資料集收錄了大量與台灣社會、歷史、地理、政府及人文相關的問答,旨在測試語言模型對中華民國台灣人文社會知識的理解程度。資料集不同於其他繁體中文資料集,它並未直接以國家考試題目測試模型,而是從常見的中華民國台灣介紹與認識中,精選出反映這片土地特質的問答內容。資料集的設計目標是為了評估語言模型對中華民國台灣相關知識的理解能力,特別是在繁體中文語境下的表現。資料集來源於中華民國台灣政府官方網站,以及高中、國中、小學的學習教材,經由人工整理並輔以 GPT-4o 進行文字潤飾後完成。
创建时间:
2024-11-16
原始信息汇总
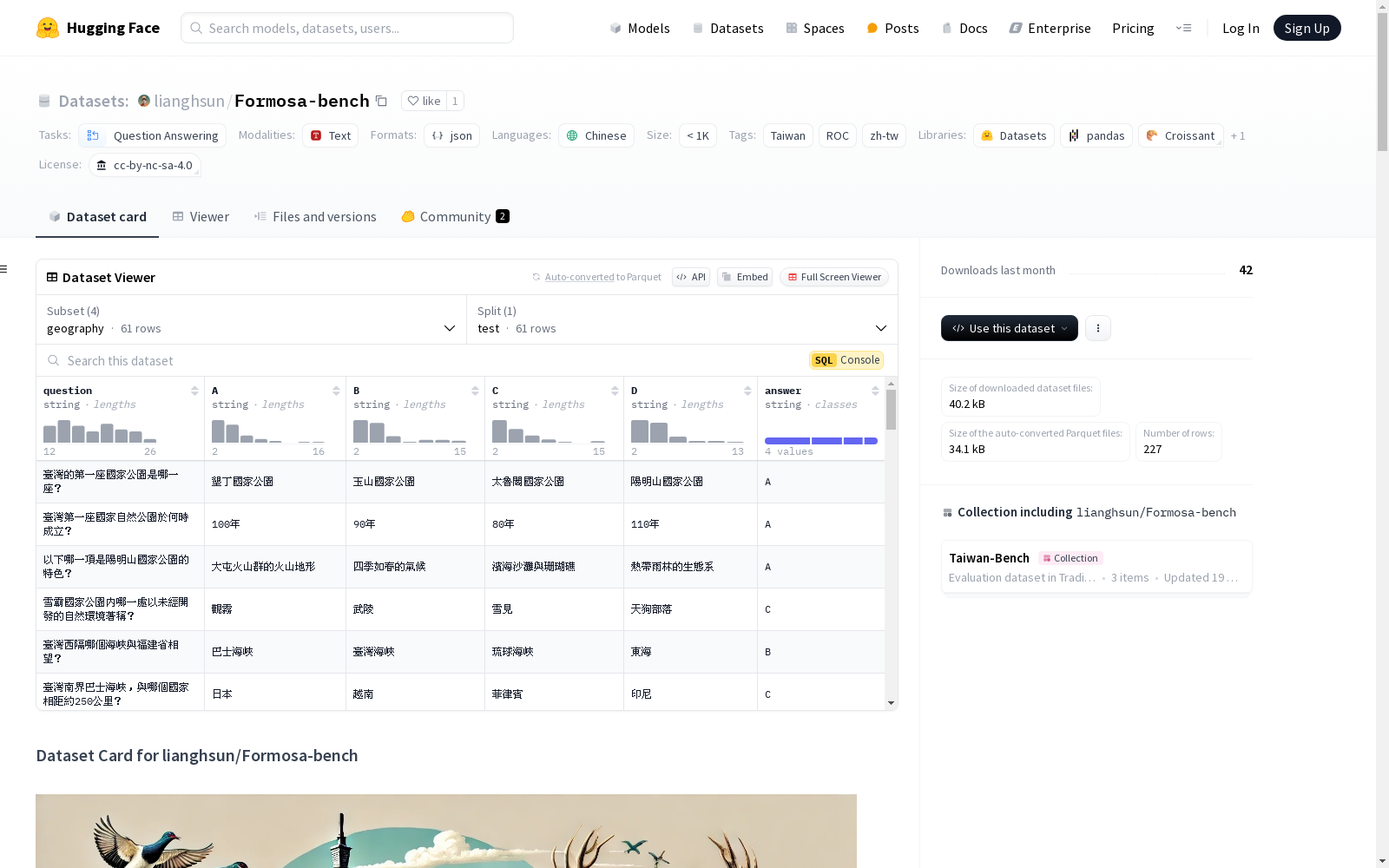
数据集概述
基本信息
- 数据集名称: Formosa-bench
- 任务类别: 问答
- 语言: 繁体中文(zh-tw)
- 标签: Taiwan, ROC, zh-tw
- 数据规模: 1K<n<10K
- 许可证: cc-by-nc-sa-4.0
数据集配置
- 历史:
- 数据文件: holdout/jsonl/history.jsonl
- 地理:
- 数据文件: holdout/jsonl/geography.jsonl
- 社会:
- 数据文件: holdout/jsonl/society.jsonl
- 政府:
- 数据文件: holdout/jsonl/government.jsonl
数据集描述
- 数据集来源: 中華民國台灣政府官方网站及教育教材
- 数据整理: 人工整理并使用GPT-4o进行文字润饰
- 数据格式: JSONL
- 字段:
- question: 问题内容
- A, B, C, D: 选项内容
- answer: 正确答案
- 字段:
数据集用途
- 直接用途:
- 模型评测: 评估语言模型对中華民國台灣人文、社会、历史、地理及政府等知识的理解能力。
- 模型微调: 作为繁体中文知识补充资料,用于强化模型在人文社会相关领域的表现。
- 非适用用途:
- 恶意用途: 生成误导性或虚假信息。
- 非繁体中文语言模型的测试。
- 伦理或敏感议题的测试。
- 技术性能测试。
数据集创建
- 创建动机:
- 提升繁体中文知识评测。
- 增加繁体中文知识的测试基准集。
- 中華民國台灣多领域知识覆盖。
- 真实模拟应用场景。
数据集结构
- 数据字段:
- question: 问题内容
- A, B, C, D: 选项内容
- answer: 正确答案
数据集示例
json { "question": "中華民國於何時正式宣告成立?", "A": "1911年10月10日", "B": "1912年1月1日", "C": "1928年6月", "D": "1931年9月", "answer": "B" }
数据集引用
yaml @misc{lianghsun2024formosabench, author = {Huang Liang-Hsun}, title = {Formosa-bench}, year = {2024}, url = {https://huggingface.co/datasets/lianghsun/Formosa-bench}, note = {Accessed: 2024-11-27} }
搜集汇总
数据集介绍
构建方式
Formosa-bench数据集的构建过程基于对中华民国台湾历史、社会、地理及政府相关知识的深度挖掘与整理。数据来源主要包括台湾政府官方网站及中小学教育教材,经过人工筛选与GPT-4o的润饰,最终形成以单选择题形式呈现的问答数据集。每一道题目均经过严格校对,确保其准确性与语言流畅性,旨在为语言模型提供高质量的繁体中文知识测试基准。
特点
Formosa-bench数据集以其独特的繁体中文语境和台湾本土知识覆盖而著称。数据集涵盖了历史、社会、地理及政府四大领域,问题设计源于实际生活中的常见知识场景,而非传统的国家考试题目。这种设计不仅增强了数据集的实用性,还能更全面地评估语言模型对台湾相关知识的理解深度。此外,数据集的问答格式简洁明了,便于模型进行直接测试与微调。
使用方法
Formosa-bench数据集主要用于评估语言模型在繁体中文语境下对台湾相关知识的理解能力。用户可通过加载JSONL格式的数据文件,直接使用数据集中的问答对进行模型测试。此外,数据集也可作为繁体中文知识的补充资料,用于模型的微调与优化。需要注意的是,数据集的设计初衷是公平评测,因此不建议将其用于模型训练,以免影响评测结果的公正性。
背景与挑战
背景概述
Formosa-bench数据集由黄亮勋(Huang Liang Hsun)于2024年创建,旨在评估语言模型对中华民国台湾人文社会知识的理解能力。该数据集涵盖了历史、地理、社会与政府四大领域,通过精选的问答内容,反映了台湾这片土地的特质。与传统的繁体中文数据集不同,Formosa-bench并未直接采用国家考试题目,而是从常见的台湾介绍与认识中提炼出具有代表性的问题,从而更全面地测试模型对台湾知识的掌握程度。该数据集的创建不仅填补了繁体中文知识评测的空白,还为语言模型在繁体中文语境下的表现提供了新的基准。
当前挑战
Formosa-bench数据集在构建与应用过程中面临多重挑战。首先,数据集的构建需要从大量政府官方资料和教育教材中筛选出与台湾相关的知识内容,并将其转化为标准化的问答格式,这一过程不仅耗时耗力,还需确保问题的准确性与代表性。其次,由于繁体中文在语言模型训练中的占比相对较小,模型在处理台湾特定知识时可能存在偏差,如何通过该数据集有效提升模型对繁体中文的理解能力是一个重要挑战。此外,数据集的问答设计需避免涉及敏感或争议性议题,以确保其在中立性与公平性上的表现。最后,数据集的广泛应用还需考虑其在跨语言任务中的适用性,避免因语言或文化差异导致的误用或误解。
常用场景
经典使用场景
Formosa-bench数据集主要用于评估语言模型在繁体中文语境下对台湾社会、历史、地理及政府等相关知识的理解能力。通过精心设计的问答题目,该数据集能够全面测试模型在多个领域中的表现,特别是在涉及台湾特定知识时的准确性和深度。
解决学术问题
Formosa-bench数据集解决了语言模型在繁体中文知识理解上的偏差问题。由于许多模型的训练数据以全球化或通用性为主,繁体中文知识往往被边缘化。该数据集通过涵盖台湾历史、社会、地理及政府等多个领域的知识,提供了一个公平且全面的测试基准,促进了模型在繁体中文问题上的公平性和准确性。
衍生相关工作
Formosa-bench数据集的推出,激发了学术界对繁体中文知识理解的研究兴趣。基于该数据集,许多研究团队开发了新的评测方法和模型优化技术,以提升语言模型在繁体中文语境下的表现。此外,该数据集还促进了跨领域合作,推动了台湾相关知识的数字化和智能化应用,为未来的学术研究和实际应用奠定了坚实基础。
以上内容由遇见数据集搜集并总结生成


