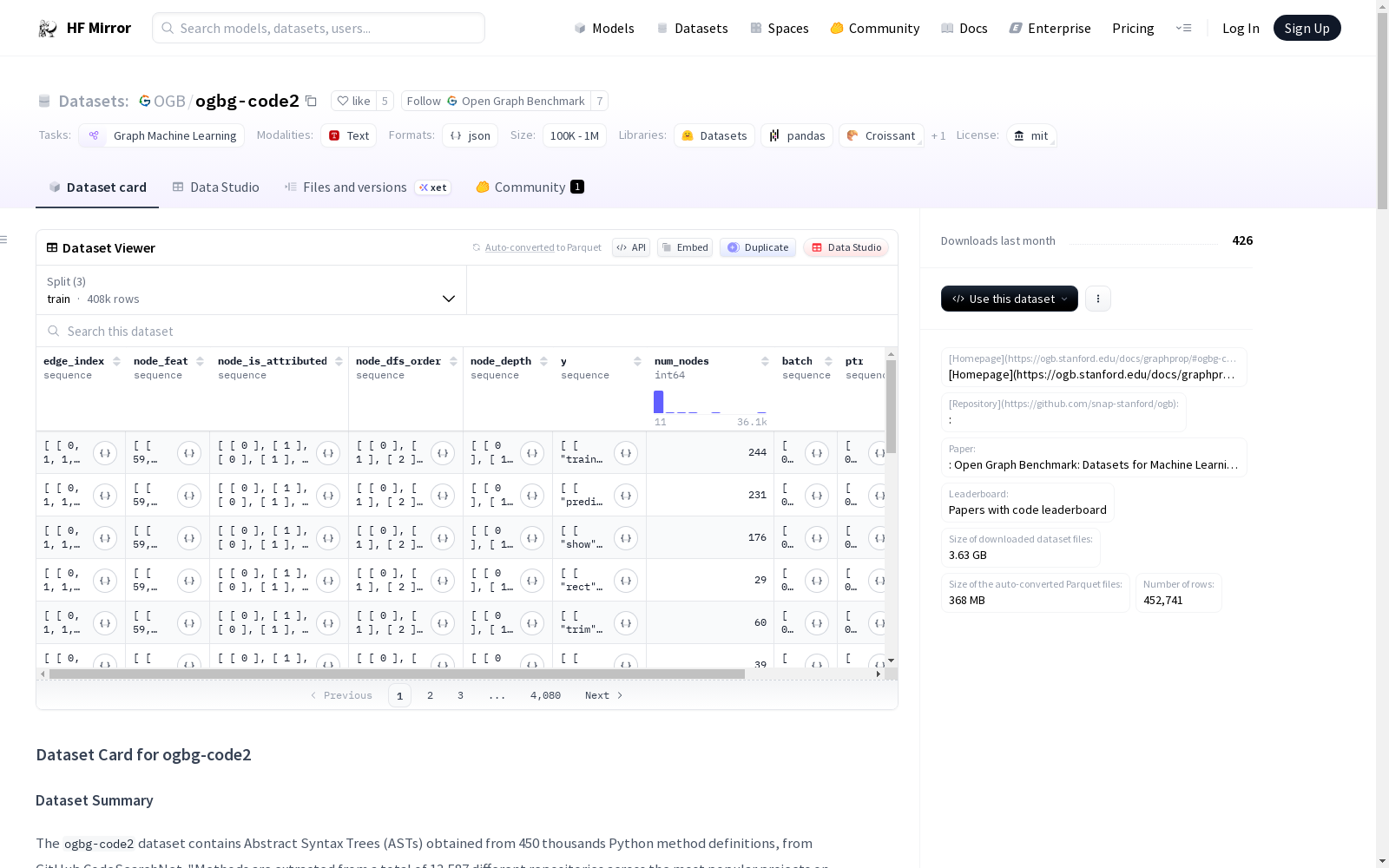
资源简介:
---
license: mit
task_categories:
- graph-ml
---
# Dataset Card for ogbg-code2
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [External Use](#external-use)
- [PyGeometric](#pygeometric)
- [Dataset Structure](#dataset-structure)
- [Data Properties](#data-properties)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **[Homepage](https://ogb.stanford.edu/docs/graphprop/#ogbg-code2)**
- **[Repository](https://github.com/snap-stanford/ogb):**:
- **Paper:**: Open Graph Benchmark: Datasets for Machine Learning on Graphs (see citation)
- **Leaderboard:**: [OGB leaderboard](https://ogb.stanford.edu/docs/leader_graphprop/#ogbg-code2) and [Papers with code leaderboard](https://paperswithcode.com/sota/graph-property-prediction-on-ogbg-code2)
### Dataset Summary
The `ogbg-code2` dataset contains Abstract Syntax Trees (ASTs) obtained from 450 thousands Python method definitions, from GitHub CodeSearchNet. "Methods are extracted from a total of 13,587 different repositories across the most popular projects on GitHub.", by teams at Stanford, to be a part of the Open Graph Benchmark. See their website or paper for dataset postprocessing.
### Supported Tasks and Leaderboards
"The task is to predict the sub-tokens forming the method name, given the Python method body represented by AST and its node features. This task is often referred to as “code summarization”, because the model is trained to find succinct and precise description for a complete logical unit."
The score is the F1 score of sub-token prediction.
## External Use
### PyGeometric
To load in PyGeometric, do the following:
```python
from datasets import load_dataset
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
graphs_dataset = load_dataset("graphs-datasets/ogbg-code2)
# For the train set (replace by valid or test as needed)
graphs_list = [Data(graph) for graph in graphs_dataset["train"]]
graphs_pygeometric = DataLoader(graph_list)
```
## Dataset Structure
### Data Properties
| property | value |
|---|---|
| scale | medium |
| #graphs | 452,741 |
| average #nodes | 125.2 |
| average #edges | 124.2 |
| average node degree | 2.0 |
| average cluster coefficient | 0.0 |
| MaxSCC ratio | 1.000 |
| graph diameter | 13.5 |
### Data Fields
Each row of a given file is a graph, with:
- `edge_index` (list: 2 x #edges): pairs of nodes constituting edges
- `edge_feat` (list: #edges x #edge-features): features of edges
- `node_feat` (list: #nodes x #node-features): the nodes features, embedded
- `node_feat_expanded` (list: #nodes x #node-features): the nodes features, as code
- `node_is_attributed` (list: 1 x #nodes): ?
- `node_dfs_order` (list: #nodes x #1): the nodes order in the abstract tree, if parsed using a depth first search
- `node_depth` (list: #nodes x #1): the nodes depth in the abstract tree
- `y` (list: 1 x #tokens): contains the tokens to predict as method name
- `num_nodes` (int): number of nodes of the graph
- `ptr` (list: 2): index of first and last node of the graph
- `batch` (list: 1 x #nodes): ?
### Data Splits
This data comes from the PyGeometric version of the dataset provided by OGB, and follows the provided data splits.
This information can be found back using
```python
from ogb.graphproppred import PygGraphPropPredDataset
dataset = PygGraphPropPredDataset(name = 'ogbg-code2')
split_idx = dataset.get_idx_split()
train = dataset[split_idx['train']] # valid, test
```
More information (`node_feat_expanded`) has been added through the typeidx2type and attridx2attr csv files of the repo.
## Additional Information
### Licensing Information
The dataset has been released under MIT license license.
### Citation Information
```
@inproceedings{hu-etal-2020-open,
author = {Weihua Hu and
Matthias Fey and
Marinka Zitnik and
Yuxiao Dong and
Hongyu Ren and
Bowen Liu and
Michele Catasta and
Jure Leskovec},
editor = {Hugo Larochelle and
Marc Aurelio Ranzato and
Raia Hadsell and
Maria{-}Florina Balcan and
Hsuan{-}Tien Lin},
title = {Open Graph Benchmark: Datasets for Machine Learning on Graphs},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference
on Neural Information Processing Systems 2020, NeurIPS 2020, December
6-12, 2020, virtual},
year = {2020},
url = {https://proceedings.neurips.cc/paper/2020/hash/fb60d411a5c5b72b2e7d3527cfc84fd0-Abstract.html},
}
```
### Contributions
Thanks to [@clefourrier](https://github.com/clefourrier) for adding this dataset.
license: MIT许可证
task_categories:
- 图机器学习(graph-ml)
# ogbg-code2 数据集卡片
## 目录
- [目录](#table-of-contents)
- [数据集描述](#dataset-description)
- [数据集概况](#dataset-summary)
- [支持任务与评测基准](#supported-tasks-and-leaderboards)
- [外部使用](#external-use)
- [PyGeometric](#pygeometric)
- [数据集结构](#dataset-structure)
- [数据属性](#data-properties)
- [数据字段](#data-fields)
- [数据划分](#data-splits)
- [附加信息](#additional-information)
- [许可证信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献者](#contributions)
## 数据集描述
- **[主页](https://ogb.stanford.edu/docs/graphprop/#ogbg-code2)**
- **[代码仓库](https://github.com/snap-stanford/ogb):**
- **论文:** 《Open Graph Benchmark: 面向图机器学习的数据集》(详见引用信息)
- **评测基准:** [OGB评测基准](https://ogb.stanford.edu/docs/leader_graphprop/#ogbg-code2) 与 [Papers with Code评测基准](https://paperswithcode.com/sota/graph-property-prediction-on-ogbg-code2)
### 数据集概况
`ogbg-code2` 数据集包含源自GitHub CodeSearchNet的452,741个Python方法定义所对应的抽象语法树(Abstract Syntax Tree,AST)。该数据集由斯坦福团队构建,作为开放图基准(Open Graph Benchmark,OGB)的组成部分,其样本提取自GitHub上13,587个不同的热门项目仓库。有关数据集的后处理细节,请参阅其官方网站或论文。
### 支持任务与评测基准
本任务的目标为:给定以抽象语法树及其节点特征表示的Python方法体,预测构成方法名的子Token(Token)。该任务常被称为“代码摘要生成”,因为模型需要学习为完整逻辑单元生成简洁精准的描述文本。
评测指标为子Token预测任务的F1值。
## 外部使用
### PyGeometric使用示例
python
from datasets import load_dataset
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
graphs_dataset = load_dataset("graphs-datasets/ogbg-code2")
# 针对训练集(可按需替换为验证集或测试集)
graphs_list = [Data(graph) for graph in graphs_dataset["train"]]
graphs_pygeometric = DataLoader(graph_list)
## 数据集结构
### 数据属性
| 属性 | 取值 |
|---|---|
| 数据规模 | 中等 |
| 图总数 | 452,741 |
| 平均节点数 | 125.2 |
| 平均边数 | 124.2 |
| 平均节点度 | 2.0 |
| 平均聚类系数 | 0.0 |
| 最大强连通分量占比 | 1.000 |
| 图直径 | 13.5 |
### 数据字段
每个文件的每一行对应一张图,包含以下字段:
- `edge_index` (list: 2 x #edges): 构成边的节点对
- `edge_feat` (list: #edges x #edge-features): 边的特征向量
- `node_feat` (list: #nodes x #node-features): 经嵌入处理的节点特征
- `node_feat_expanded` (list: #nodes x #node-features): 以代码形式表示的节点特征
- `node_is_attributed` (list: 1 x #nodes): 该字段具体含义暂未说明
- `node_dfs_order` (list: #nodes x #1): 采用深度优先搜索遍历的节点顺序
- `node_depth` (list: #nodes x #1): 节点在抽象语法树中的深度
- `y` (list: 1 x #tokens): 待预测的方法名对应的Token序列
- `num_nodes` (int): 该图的节点总数
- `ptr` (list: 2): 该图的首个与最后一个节点的索引
- `batch` (list: 1 x #nodes): 该字段具体含义暂未说明
### 数据划分
本数据集采用OGB官方提供的PyGeometric版本,并沿用其预设的数据划分方式。可通过以下代码获取划分索引:
python
from ogb.graphproppred import PygGraphPropPredDataset
dataset = PygGraphPropPredDataset(name='ogbg-code2')
split_idx = dataset.get_idx_split()
train = dataset[split_idx["train"]] # 可替换为valid或test获取对应划分
可通过仓库中的`typeidx2type.csv`与`attridx2attr.csv`文件获取`node_feat_expanded`字段的更多补充信息。
## 附加信息
### 许可证信息
本数据集采用MIT许可证进行开源分发。
### 引用信息
@inproceedings{hu-etal-2020-open,
author = {Weihua Hu and
Matthias Fey and
Marinka Zitnik and
Yuxiao Dong and
Hongyu Ren and
Bowen Liu and
Michele Catasta and
Jure Leskovec},
editor = {Hugo Larochelle and
Marc Aurelio Ranzato and
Raia Hadsell and
Maria{-}Florina Balcan and
Hsuan{-}Tien Lin},
title = {Open Graph Benchmark: Datasets for Machine Learning on Graphs},
booktitle = {Advances in Neural Information Processing Systems 33: Annual Conference
on Neural Information Processing Systems 2020, NeurIPS 2020, December
6-12, 2020, virtual},
year = {2020},
url = {https://proceedings.neurips.cc/paper/2020/hash/fb60d411a5c5b72b2e7d3527cfc84fd0-Abstract.html},
}
### 贡献者
感谢[@clefourrier](https://github.com/clefourrier) 贡献本数据集。