Public Domain 12M
收藏arXiv2024-10-30 更新2024-11-04 收录
下载链接:
https://huggingface.co/datasets/Spawning/PD12M
下载链接
链接失效反馈官方服务:
资源简介:
Public Domain 12M(PD12M)是由Spawning创建的大规模图像-文本数据集,包含1240万张高质量的公共领域及CC0许可图片,搭配合成字幕,旨在训练文本到图像的模型。该数据集是目前最大的公共领域图像-文本数据集,以其庞大的规模和明确的版权声明,为AI模型的训练提供了坚实的基础,同时最小化了版权担忧。PD12M的数据来源包括画廊、图书馆、档案馆、博物馆(GLAM)以及Wikimedia Commons等,通过精心筛选和治理,确保了数据的质量和安全性。数据集的构建过程涵盖了从图像收集、版权验证、图像下载、内容过滤到字幕生成等多个步骤。特别地,PD12M通过Source.Plus平台引入了社区驱动的数据治理机制,以支持数据集的持续改进和维护。该数据集不仅为AI领域提供了丰富的训练资源,也为负责任的AI实践提供了范例,促进了公共AI资源的保护和利用。
Public Domain 12M (PD12M) is a large-scale image-text dataset created by Spawning. It contains 12.4 million high-quality public domain and CC0-licensed images paired with synthetic captions, and is developed for training text-to-image models. As the largest public domain image-text dataset to date, PD12M relies on its massive scale and clear copyright statements to provide a solid foundation for AI model training while minimizing copyright-related concerns. The dataset sources include galleries, libraries, archives, museums (GLAM), Wikimedia Commons and other similar platforms. Through rigorous screening and governance, the quality and safety of the dataset are guaranteed. Its construction process covers multiple steps such as image collection, copyright verification, image downloading, content filtering and caption generation. Notably, PD12M introduces a community-driven data governance mechanism via the Source.Plus platform to support the continuous improvement and maintenance of the dataset. This dataset not only provides abundant training resources for the AI field, but also serves as a paradigm for responsible AI practices, promoting the protection and utilization of public AI resources.
提供机构:
Spawning
创建时间:
2024-10-30
搜集汇总
数据集介绍
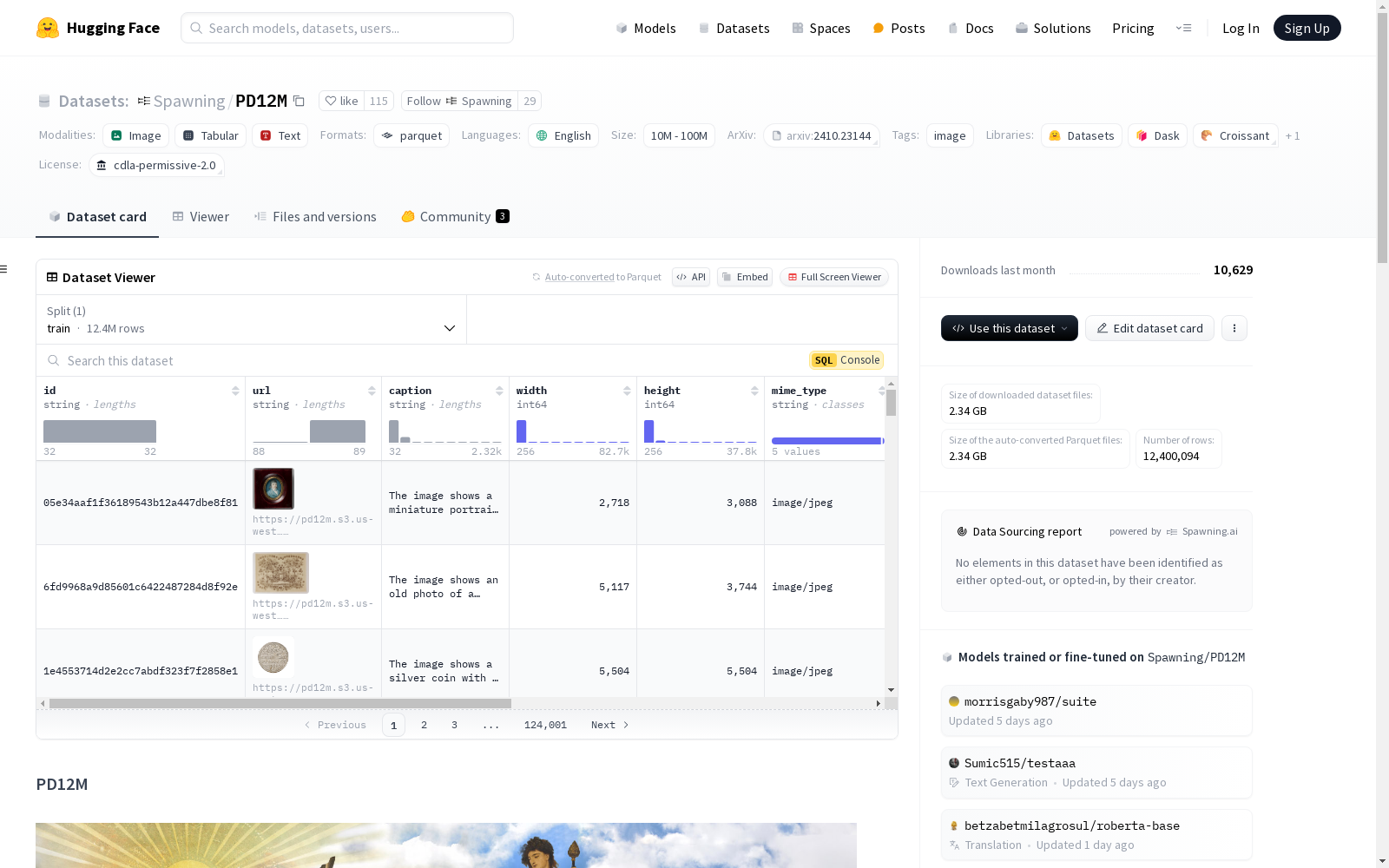
构建方式
Public Domain 12M(PD12M)数据集的构建过程严格遵循了高质量和高透明度的标准。首先,数据集从画廊、图书馆、档案馆和博物馆(GLAM)以及内容聚合器中直接收集了2310万张图像,这些机构提供了额外的质量、安全性和许可审查。此外,从Wikimedia Commons和iNaturalist分别收集了1130万和320万张图像,确保了图像的多样性和质量。所有图像在收集前都经过严格的元数据解析和过滤,仅保留明确标记为公共领域或CC0许可的图像。最终,通过自动化和手动筛选,数据集精选出1240万张高质量图像及其合成标题,确保了数据集的美学质量和版权合规性。
特点
Public Domain 12M(PD12M)数据集以其大规模、高质量和明确的版权状态著称。作为迄今为止最大的公共领域图像-文本数据集,PD12M包含1240万张图像及其合成标题,适用于训练文本到图像的模型。数据集的独特之处在于其通过Source.Plus平台引入了社区驱动的数据集治理机制,确保了数据集的持续维护和更新,减少了潜在的危害,并支持了长期的复现性。此外,PD12M的图像来源多样,涵盖了GLAM机构、Wikimedia Commons和iNaturalist,确保了数据集的广泛性和代表性。
使用方法
Public Domain 12M(PD12M)数据集主要用于训练文本到图像的生成模型。研究人员和开发者可以通过Hugging Face平台访问该数据集,并利用其提供的图像和合成标题进行模型训练。数据集的治理机制通过Source.Plus平台实现,用户可以在此平台上探索、审查和改进数据集,同时通过公开的反馈机制报告和解决潜在的问题。为了确保数据集的稳定性和复现性,数据集的维护团队定期更新和审核数据内容,确保其符合最新的版权和质量标准。
背景与挑战
背景概述
Public Domain 12M(PD12M)数据集由Jordan Meyer、Nick Padgett、Cullen Miller和Laura Exline于2024年创建,旨在为文本到图像模型的训练提供一个高质量、无版权争议的图像-文本数据集。该数据集包含了1240万张公共领域和CC0许可的图像,并配有合成标题,是目前最大的公共领域图像-文本数据集。PD12M的创建不仅解决了大规模数据集在版权、隐私和内容不当等方面的常见问题,还通过Source.Plus平台引入了创新的社区驱动数据集治理机制,确保数据集的长期维护和可重复性。
当前挑战
PD12M数据集在构建过程中面临多重挑战。首先,确保所有图像的版权状态清晰无误,避免版权纠纷,这是一个复杂且耗时的过程。其次,数据集的规模和多样性带来了内容过滤和质量控制的难题,特别是在处理可能包含不当内容或个人身份信息(PII)的图像时。此外,数据集的长期维护和更新也是一个重要挑战,需要持续的社区参与和技术支持,以确保数据集的稳定性和可用性。最后,数据集的地理、文化和历史偏见问题也需要不断监控和修正,以提高数据集的公平性和代表性。
常用场景
经典使用场景
Public Domain 12M(PD12M)数据集因其庞大的规模和高质量的图像-文本对,成为训练文本到图像模型的理想选择。该数据集包含1240万对高质量的公共领域和CC0许可的图像及其合成标题,能够有效支持基础模型的训练,同时减少版权问题的担忧。通过Source.Plus平台,PD12M还引入了创新的社区驱动数据集治理机制,确保数据集的长期维护和减少潜在危害。
实际应用
在实际应用中,PD12M数据集被广泛用于开发和训练各种文本到图像生成模型,如图像生成、图像描述和视觉问答系统等。其高质量的图像和合成标题对,使得这些模型在生成逼真图像和准确描述方面表现出色。此外,PD12M的治理机制确保了数据集的持续更新和质量维护,使其在商业和研究项目中具有广泛的应用前景。
衍生相关工作
PD12M数据集的发布催生了多项相关研究和工作,特别是在文本到图像生成模型和数据集治理领域。例如,基于PD12M的模型训练方法被应用于开发更高效的图像生成算法,而其治理机制也为其他数据集的维护和更新提供了参考。此外,PD12M的成功经验还推动了公共AI基础设施的发展,促进了AI资源的共享和保护,进一步推动了AI技术的民主化和透明化。
以上内容由遇见数据集搜集并总结生成


