keural-datasets
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://huggingface.co/datasets/mkd-chanwoo/keural-datasets
下载链接
链接失效反馈官方服务:
资源简介:
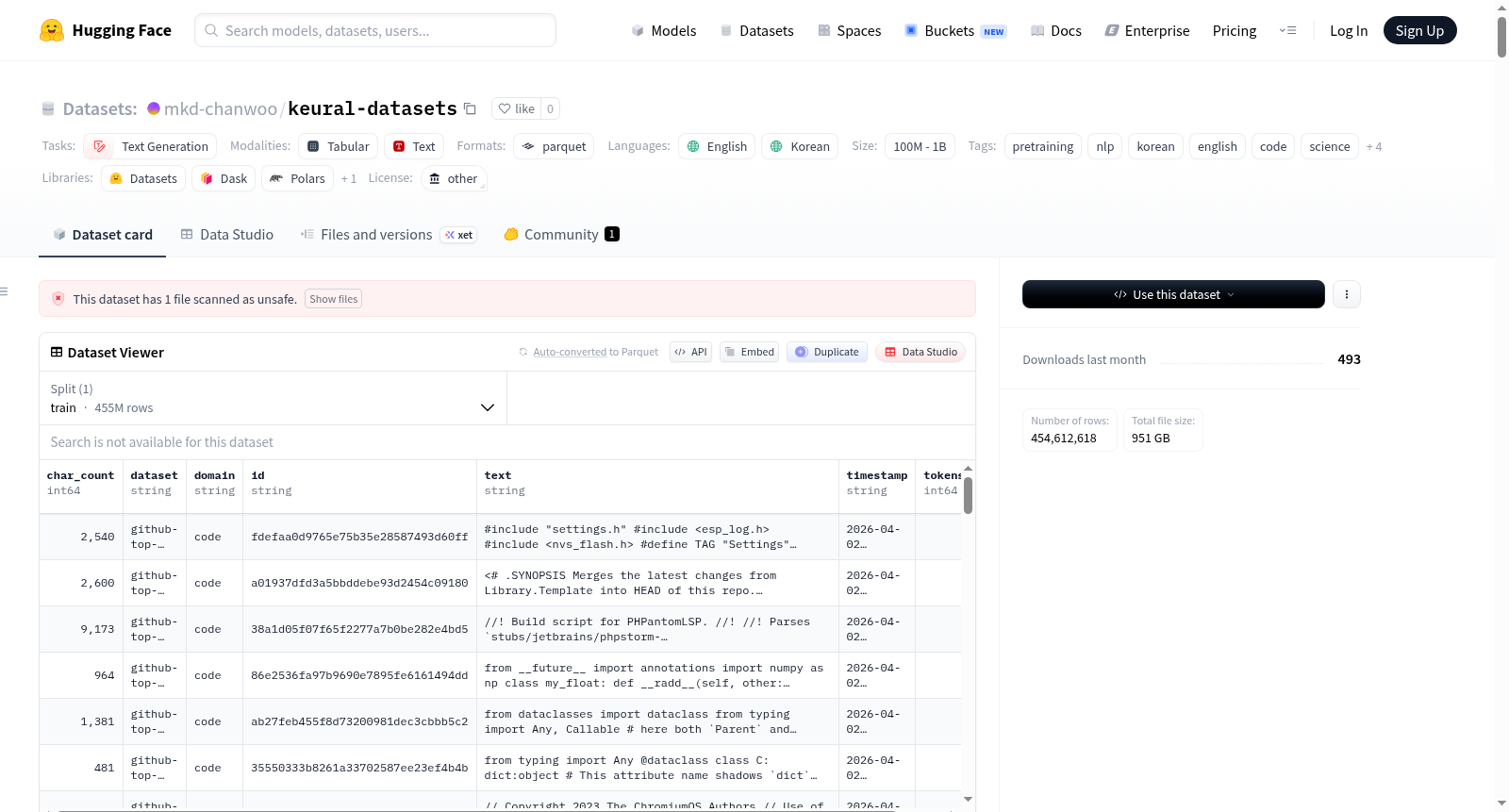
Keural预训练数据集(第二阶段——最终版)是一个高质量、多语言的语料库,专为训练Keural韩语大语言模型设计。该数据集经过严格的质量过滤、语言筛选、毒性内容去除及去重处理(包括精确和近似去重),最终包含约329M文档和220B标记,涵盖英语、韩语、代码和科学四大领域。数据以Parquet分片形式存储,按领域和上传批次组织。数据集采用Keural SentencePiece分词器(`mkd-ai/keural-tokenizer`)进行标记化,并通过多阶段处理流程确保数据质量,包括标准化、过滤、去重和最终审计验证。适用任务包括多语言文本生成、代码生成及科学文本理解等。数据集继承自19个来源的混合许可证,需注意部分来源(如Namuwiki)限制商业用途。
创建时间:
2026-04-02
搜集汇总
数据集介绍
构建方式
在构建大规模语言模型预训练语料库的背景下,Keural数据集通过一套严谨的多阶段流程精心构建。其构建始于从25个原始数据源收集约5.07亿份文档的原始互联网文本。随后,数据被统一标准化为一致的JSONL格式,并依次进行质量过滤、语言识别及有害内容筛查。核心的去重环节采用了双重策略:首先通过SHA-256哈希进行精确去重,随后利用MinHash LSH算法,基于词三元组和0.85的Jaccard相似度阈值,移除近似的重复文档。最终,经过审计验证和分领域令牌配额控制,数据被组织成Parquet格式的分片,形成了包含约4.38亿文档、3410亿令牌的高质量语料。
使用方法
对于旨在训练或评估多语言及领域特定语言模型的研究者与开发者而言,该数据集提供了清晰的使用路径。数据可通过Hugging Face数据集库直接加载,其按领域(英语、韩语、代码、科学)和上传批次组织的目录结构便于选择性访问。每个文档包含ID、文本、来源数据集、领域、令牌计数等标准化字段。使用者需注意数据集继承了混合许可证,部分来源(如Namuwiki、AIHub数据集)限制商业用途,BigCode数据集则需遵守OpenRAIL-M许可条款,因此在商业部署前务必仔细核查相关许可协议。数据集适用于预训练、词表分析、领域适应性研究等多种自然语言处理任务。
背景与挑战
背景概述
Keural数据集是专为训练Keural韩语大语言模型而构建的预训练语料库,由研究人员shinchanwoo及其团队于2026年4月创建。该数据集旨在解决多语言、多领域文本生成任务中高质量训练数据稀缺的问题,特别是针对韩语与英语、代码及科学文本的混合建模需求。通过整合来自25个开源数据源的原始文本,经过严格的规范化、质量过滤、语言检测、毒性内容移除及去重处理,最终形成包含约4.38亿文档、3410亿标记的生产级语料。其核心研究问题聚焦于构建一个均衡、纯净且规模庞大的多语言预训练数据集,以推动韩语自然语言处理技术的发展,并为跨语言模型训练提供重要资源。
当前挑战
Keural数据集面临的挑战主要体现在领域问题与构建过程两方面。在领域层面,该数据集旨在解决多语言文本生成任务中数据质量与语言平衡的难题,尤其是韩语语料相对匮乏,导致其目标标记量仅完成27.9%,成为模型训练的主要瓶颈。构建过程中的挑战则更为复杂:首先,数据去重需应对海量文本中的精确与近似重复,采用SHA-256哈希与MinHash LSH算法以0.85杰卡德相似度阈值进行高效处理;其次,质量过滤需结合字符重复率、香农熵与词汇多样性等多重指标,以剔除低质量内容;此外,数据来源的混合许可协议(如非商业许可的Namuwiki与AIHub数据)为商业应用带来法律风险;最后,跨数据源的格式统一与大规模并行处理对计算资源与流程设计提出了极高要求。
常用场景
经典使用场景
在大型语言模型预训练领域,高质量、多语言、多领域的语料库是模型性能的基石。Keural数据集作为Keural韩语大语言模型的最终生产级预训练语料,其最经典的使用场景是作为基础模型训练的原料。该数据集整合了英语、韩语、代码和科学文献四大领域的文本,经过严格的质量筛选、语言过滤、毒性内容移除以及精确与近似去重处理,确保了语料的纯净性与多样性。研究人员和工程师可以直接利用这些结构化的Parquet分片数据,高效地训练能够理解和生成韩语及英语文本、处理编程代码以及解析科学文献的通用大语言模型,为后续的指令微调和特定任务适配提供了坚实的数据基础。
解决学术问题
该数据集系统地解决了大规模预训练语料构建中的若干核心学术问题。首先,它通过多阶段流水线处理,为语料质量评估与过滤提供了可复现的工程范式,具体包括基于字符重复率、香农熵和词汇多样性的语义质量检查。其次,其采用的SHA-256精确去重和基于MinHash LSH的近似去重方法,为研究语料库内部及跨数据源的冗余性问题提供了详实的统计数据和实践案例。再者,通过设定分领域的token配额目标并监控进度,该数据集为如何平衡多领域语料规模、优化模型在不同知识领域的表现提供了实证参考。这些工作共同推进了构建高效、洁净、均衡的大规模多语言预训练数据集的方法学研究。
实际应用
Keural数据集的实际应用场景紧密围绕韩语人工智能生态的发展需求。它可直接用于训练服务于韩国市场的商用或研究用大语言模型,例如智能客服、内容创作助手和代码生成工具。其内含的大量高质量韩语文本,有助于缓解韩语资源相对稀缺的现状,提升模型对韩语语法、文化语境的理解能力。同时,整合的代码和科学文献域数据,使得基于该数据集训练的模型能够胜任技术文档编写、软件开发和学术论文辅助阅读等专业任务。数据集的Parquet分片格式和Snappy压缩也优化了工业级分布式训练中的数据加载效率,降低了大规模模型训练的基础设施门槛。
数据集最近研究
最新研究方向
在多语言大语言模型预训练领域,Keural数据集凭借其精心构建的韩语与英语双语语料库,正成为推动跨语言模型性能提升的关键资源。该数据集通过严格的去重与质量过滤流程,整合了代码与科学文本等多元领域内容,为研究多语言对齐与领域适应性提供了高质量基准。当前,前沿探索聚焦于利用其平衡的语料分布优化低资源语言表示,并借助代码与科学文本增强模型的逻辑推理能力,以应对全球化应用中语言与技术融合的复杂挑战。
以上内容由遇见数据集搜集并总结生成


