GRID Dataset
收藏arXiv2025-09-30 收录
下载链接:
https://personal.ie.cuhk.edu.hk/~ccloy/downloads_qmul_underground_reid.html
下载链接
链接失效反馈官方服务:
资源简介:
500
该数据集是一个广受欢迎的句子级别的唇语阅读数据集,包含了34位发言人的句子,每个视频时长为3秒钟。在未知的发言人分割中,使用发言人1、2、20和22进行测试,其余的则用于训练。该数据集的规模为34位发言人,每分钟约有20个视频,其任务是对唇语进行识别。
500. This is a widely acclaimed sentence-level lip reading dataset. It contains utterances from 34 speakers, with each video lasting 3 seconds. For the unseen speaker split, speakers 1, 2, 20 and 22 are used for testing, while the remaining speakers are allocated for training. The dataset consists of 34 speakers, with approximately 20 videos per minute, and its task is lip reading recognition.
提供机构:
GRID corpus
搜集汇总
数据集介绍
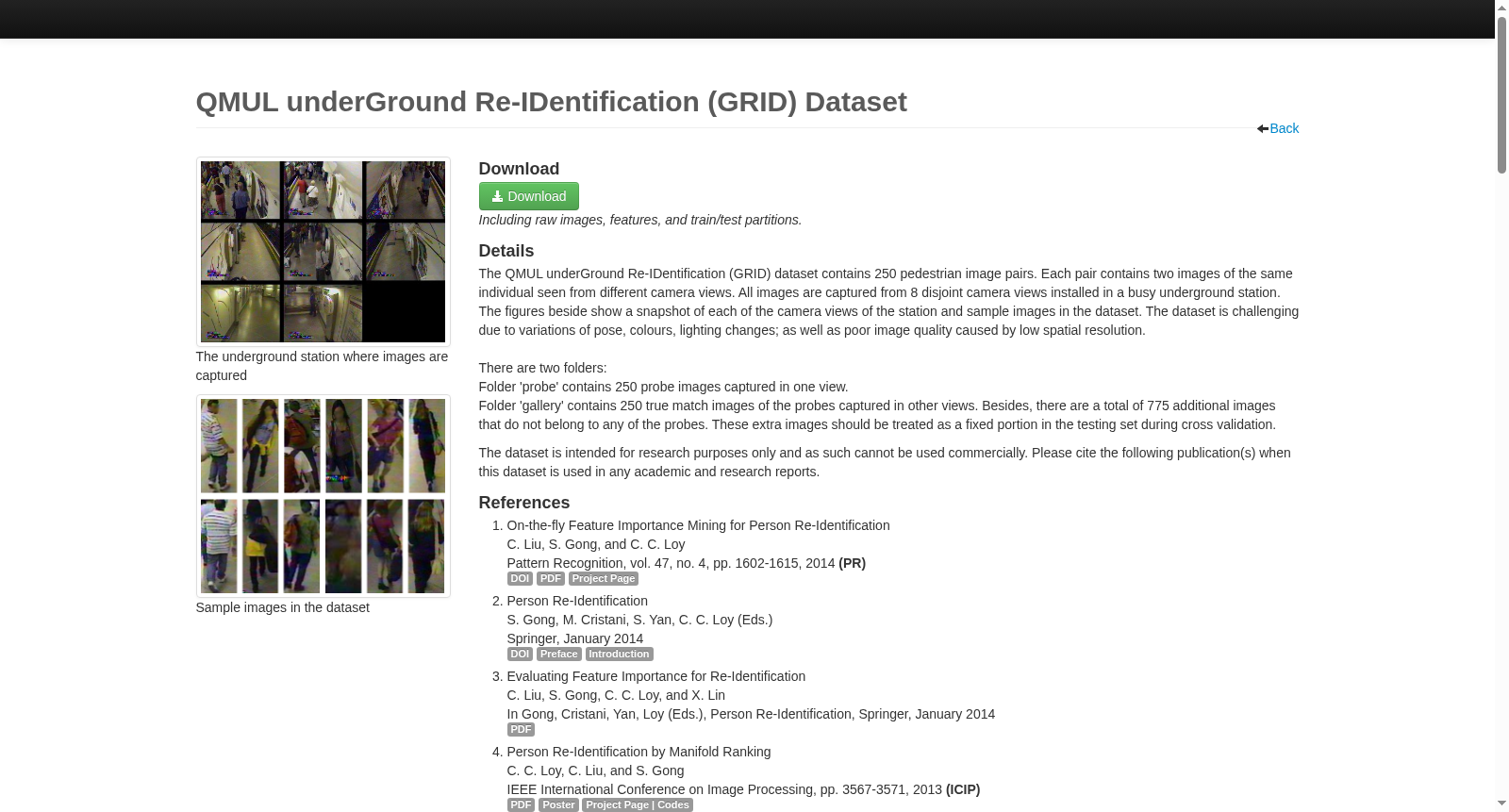
背景与挑战
背景概述
GRID Dataset是一个用于行人重识别研究的数据集,包含250对来自不同摄像头视角的行人图像,具有姿态、光照和分辨率等挑战性因素。数据集分为探针和匹配图像,额外包含775张非匹配图像用于测试,适用于学术研究。
以上内容由遇见数据集搜集并总结生成


