voiceclap-data
收藏Hugging Face2026-05-07 更新2026-05-08 收录
下载链接:
https://huggingface.co/datasets/laion/voiceclap-data
下载链接
链接失效反馈官方服务:
资源简介:
VoiceCLAP数据集是一个用于训练音频和密集字幕混合模型的数据集,支持音频分类和特征提取任务。数据集包含多个子集,如Emolia、LAIONs Got Talent、Majestrino等,每个子集都有不同的来源和特点。数据以WebDataset格式存储,每个样本包含一个48 kHz单声道音频文件(.flac)和一个JSON文件(包含字幕和元数据)。字幕和属性注释由音频感知的LLM自动生成,包括情感、音色、韵律等标签。数据集规模在1B到10B之间,适用于多语言和语音相关的研究。使用该数据集时需注意伦理问题,避免用于可能重新识别、分析或监视说话者的任务。数据集采用CC-BY-4.0许可证,部分子集可能继承上游来源的许可条款。
The VoiceCLAP dataset is a dataset for training audio and dense caption hybrid models, supporting audio classification and feature extraction tasks. The dataset contains multiple subsets, such as Emolia, LAIONs Got Talent, Majestrino, etc., each with different sources and characteristics. Data is stored in WebDataset format, with each sample containing a 48 kHz mono audio file (.flac) and a JSON file (containing captions and metadata). Captions and attribute annotations are automatically generated by audio-aware LLMs, including labels for emotion, timbre, prosody, etc. The dataset size ranges from 1B to 10B, suitable for multilingual and speech-related research. Ethical considerations should be taken when using this dataset, avoiding tasks that may re-identify, analyze, or monitor speakers. The dataset is licensed under CC-BY-4.0, with some subsets potentially inheriting licensing terms from upstream sources.
提供机构:
LAION eV
创建时间:
2026-05-07
搜集汇总
数据集介绍
构建方式
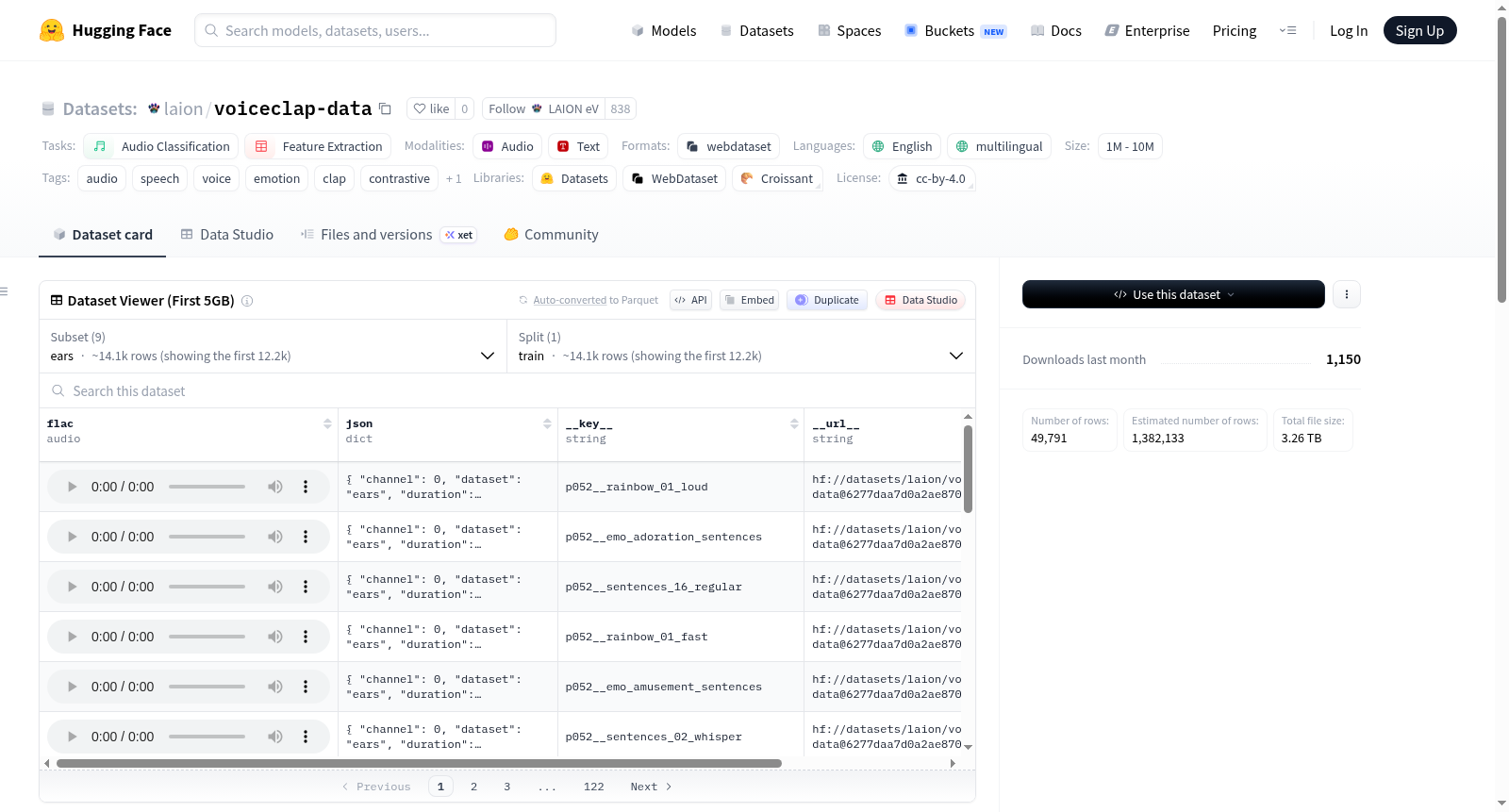
VoiceCLAP Data 数据集旨在为语音表征学习提供大规模、多模态的配对数据,其构建方式基于一个完全自动化的流水线。该数据集将来源于多个公开语料库的音频片段,通过一系列音频感知的大语言模型进行密集标注。具体而言,流水线依次运用了 Qwen-Audio、Gemini Flash 2.5 和一个采用思维链推理模式的模型,为每个音频剪辑生成结构化描述与属性标签。标注内容涵盖了情感(依据 EmoNet 分类体系)、嗓音爆发、音色、韵律以及录音上下文等信息。所有标注和元数据被整合为 WebDataset 格式,每个分片包含成对的 FLAC 音频文件和 JSON 描述文件,确保了数据的高效存储与流式加载。
特点
该数据集最显著的特征在于其规模宏大与高度自动化的标注流程。其九个配置子集涵盖了从 Emilia 的平衡子集、LAION's Got Talent 的清理语音、多语言的 Common-Voice 子集,到合成非语言嗓音爆发以及多种情感与表现力语音库,总计包含超过十亿个样本。所有标注均由模型自动生成,无需人工介入,这种软标签策略虽然可能引入噪声,却赋予了数据极强的扩展性与多样性。尤为突出的是,Emolia、LAION's Got Talent 和 Majestrino 三个主要子集还保留了大语言模型原始的思维链痕迹,为深入研究模型推理过程与标注质量提供了宝贵线索。
使用方法
用户可通过 Hugging Face 的 datasets 库便捷地加载该数据集。加载时需指定配置名称(如 'emolia')并启用流式模式,示例代码为 'load_dataset("laion/voiceclap-data", "emolia", streaming=True)'。每个配置对应一组以 tar 包形式存储的分片文件。数据集主要用于语音分类与特征提取任务,尤其适合训练诸如 VoiceCLAP 之类的对比学习模型。需要注意的是,由于语音数据具有生物识别敏感性,使用者在进行任何可能涉及重新识别、画像或监听说话者的应用前,必须获得相应的伦理许可。数据集的授权协议为 CC-BY-4.0,但某些子集可能沿用上游数据集的原始许可条款。
背景与挑战
背景概述
VoiceCLAP Data 数据集由 LAION 研究机构于近期创建,旨在为对比语音-语言预训练模型 VoiceCLAP 提供大规模、多样化且富含密集标注的音频-文本配对数据。该数据集的核心研究问题是:如何通过自动化的音频感知大语言模型管道,生成结构化的语音属性描述,从而弥合原始音频信号与高层语义表征之间的鸿沟。通过整合来自多语言情感语音(Emilia)、表现性朗读(Expresso)、名人发言(VoxCeleb)以及合成非语言发声等九个子集,VoiceCLAP Data 为语音情感识别、说话人特征提取等下游任务提供了前所未有的数据支撑,在推动多模态语音理解领域的发展中具有重要影响力。
当前挑战
VoiceCLAP Data 所解决的领域挑战在于,传统语音数据集通常缺乏细粒度、结构化的语言描述,限制了对语音中蕴含的情感、音色、韵律等复杂属性的捕获与建模;该数据集通过无人工标注的自动化管道生成密集描述,但由此引入了标签置信度较低的挑战。构建过程中的核心挑战则包括:多源异构数据(如真实录音与合成音频)的统一格式与对齐,以及处理大规模数据(子集 shard 数量从 8 到 1052 不等)时的存储与流式传输效率;此外,语音作为生物特征数据,在整合公开语料时需审慎应对隐私与伦理合规问题。
常用场景
经典使用场景
VoiceCLAP Data作为大规模音频-稠密描述配对数据集,最经典的使用场景在于训练对比性语音-语言联合表征模型,尤其是其配套的VoiceCLAP系列模型。该数据集整合了来自Emilia、LAION's Got Talent、Common-Voice多语种子集、VoxCeleb等九个来源的千万级音频片段,每个样本均配有由Qwen-Audio、Gemini Flash 2.5等先进音频感知大语言模型自动生成的稠密描述与结构化属性标注。研究者可基于该数据集进行音频与文本模态间的对比学习,构建能够同时理解语音内容、说话人特质、情感色彩及副语言信息的鲁棒嵌入空间,从而推动语音表征向更为细腻、可解释的方向演进。
解决学术问题
该数据集精准回应了语音领域中文本-音频跨模态对齐标注匮乏的长期困境,解决了传统语音数据集仅提供文本转录或简单标签而导致语义粒度不足的问题。通过引入包含情感分类(EmoNet体系)、副语言爆发音、音色韵律及录音环境等多维属性的稠密描述,VoiceCLAP Data为研究者提供了大规模弱监督训练素材,使得模型能够学习从原始语音中抽取高维语义与情感线索。这一突破显著推动了语音分类、特征提取及零样本语音理解等学术任务的发展,尤其为多语言、多场景下的情感计算与说话人分析提供了可比肩视觉-语言领域对比学习的坚实基础。
衍生相关工作
VoiceCLAP Data直接催生了其同名VoiceCLAP系列对比学习模型(涵盖了small与large两种规模),并因其开源性质和CC-BY-4.0许可协议,已成为后续多项语音表征研究的基础资源。依托该数据集,研究者得以探索基于指令微调的语音理解、稠密描述引导的说话人验证以及情感感知的语音生成等前沿方向。此外,数据集所采用的自动化合成描述管线——即利用多模型级联生成结构化语音元数据的范式——也为其他语音数据集的建设提供了可复现的新思路,启发了关于利用大语言模型进行语音标签增强和副语言信息提取的系列后续工作。
以上内容由遇见数据集搜集并总结生成


