ManiSoft
收藏arXiv2026-05-19 更新2026-05-20 收录
下载链接:
https://buaa-colalab.github.io/ManiSoft
下载链接
链接失效反馈官方服务:
资源简介:
ManiSoft是由北京航空航天大学等研究机构创建的软体机器人视觉语言操纵基准数据集,旨在填补刚性机械臂与软体机械臂在视觉语言交互研究领域的空白。该数据集包含6,300个精心生成的桌面场景及其对应的专家操纵轨迹,每个场景均配备语言指令,数据来源于通过资产库程序化构建的263个三维对象,并采用混合物理仿真器生成高保真视觉观察。数据生成过程采用分层机制,结合高层规划器的规则分解与底层强化学习控制器的扭矩指令生成,确保了轨迹的稳定性与可扩展性。该数据集主要应用于评估和开发面向软体机械臂的视觉语言动作模型,重点解决在缺乏准确本体感知的情况下,如何从视觉观察中推断软体形态并利用其形变能力进行自适应障碍物避让等核心挑战。
提供机构:
北京航空航天大学; 北京航空航天大学·杭州创新研究院; 新加坡国立大学
创建时间:
2026-05-19
原始信息汇总
数据集概述:ManiSoft
ManiSoft 是一个面向软体连续体机器人的视觉-语言操作基准数据集,旨在超越当前刚性机械臂的操作范式。
核心信息
- 数据集名称:ManiSoft
- 论文标题:ManiSoft: Towards Vision-Language Manipulation for Soft Continuum Robotics
- 发布机构:北京航空航天大学(Beihang University)
- 论文出处:ICML 2026
数据集规模与组成
- 场景-轨迹对总数:6,300 对,涵盖干净场景和随机化场景。
- 资产库:包含 263 个对象。
- 可操作对象:109 个,覆盖 17 个类别。
- 障碍物对象:154 个,覆盖 35 个类别。
- 语言指令:每个场景平均约 40 条语言指令。
任务分类
ManiSoft 包含四个任务类别,每个任务都提供了干净场景和随机化场景:
-
收集 (Collection, COLL)
- 目标:拾取物体并放入容器中。
- 评估重点:基本轨迹控制和末端执行器协调。
-
对齐 (Alignment, ALN)
- 目标:将目标物体对齐到指定的 6-DoF(六自由度)位姿。
- 评估重点:精确的位置和方向调整。
-
堆叠 (Stacking, STK)
- 目标:将餐具按大小从大到小堆叠成稳定的一摞。
- 评估重点:在接触密集交互中的精确控制。该任务的轨迹通常比其他任务更长。
-
布置 (Arrangement, ARR)
- 目标:排列多个物体。
- 评估重点:感知、空间推理和障碍物感知规划。
数据生成流程
- 场景生成:基于资产库程序化生成桌面场景,包含干净和随机化(增加障碍物、改变位置/纹理/光照)两种类型。语言指令从模板库中根据物体属性自动实例化。
- 轨迹生成:采用分层机制生成专家演示:
- 高层:任务特定的规则型规划器将操作问题分解为语义路径点(如接近、抓取、缩回、放置),每个路径点表示为一个期望的 6-DoF 末端执行器位姿。
- 低层:一个基于强化学习(RL)训练的“执行器”将路径点转换为软体臂的力矩指令,通过结合位姿精度和运动稳定性的密集奖励进行优化。
主要基准测试结果
- 在干净场景中,代表性策略模型(如 Diffusion Policy (DP)、RDT、OpenVLA-OFT)的性能明显高于随机化场景,表明视觉变化、杂乱和障碍物是当前模型在软体机器人上面临的主要挑战。
- OpenVLA-OFT 在随机化场景中表现出最强的鲁棒性。
- DP 在简单的干净场景中保持竞争力。
- 在所有方法中,收集任务最易完成,而堆叠和布置任务则暴露了精确可变形控制和障碍物感知推理的难度。
引用信息
bibtex @article{wei2026manisoft, title={ManiSoft: Towards Vision-Language Manipulation for Soft Continuum Robotics}, author={Ziyu Wei and Luting Wang and Chen Gao and Li Wen and Si Liu}, journal={arXiv preprint arXiv:2605.18617}, year={2026}, }
搜集汇总
数据集介绍
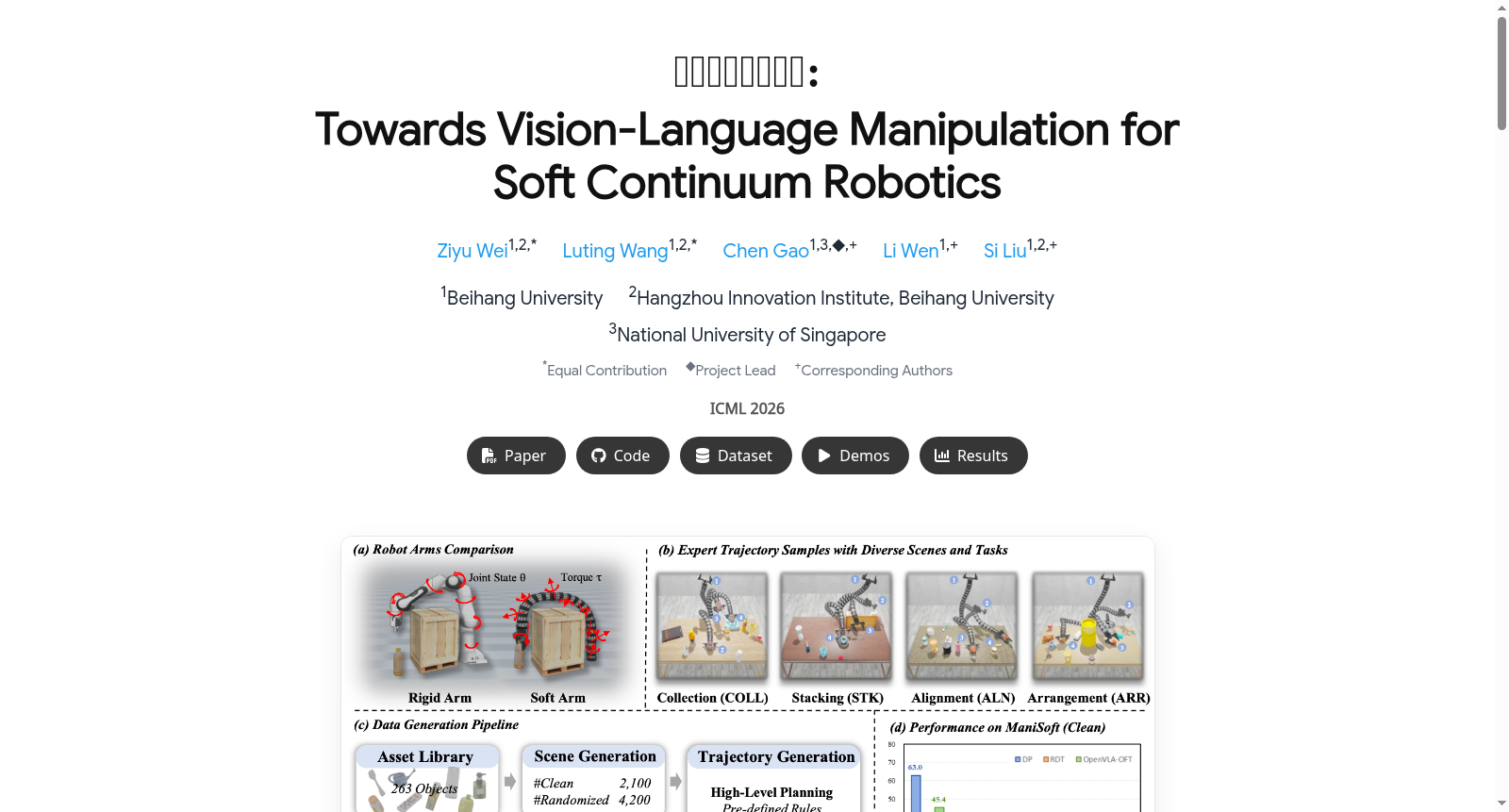
构建方式
ManiSoft数据集的构建依托于一个自动化流水线,该流水线集成了资产库、场景生成、层次化轨迹生成与仿真验证。资产库包含263个精细标注的三维物体,每个物体均预标注了适用于软体臂交互的候选操作位姿。场景生成过程首先通过从资产库中采样目标物体构建无遮挡的干净场景,随后通过引入随机障碍物、改变物体布局与纹理生成随机化场景,从而支持系统性评估。专家轨迹的生成采用层次化机制:高层规划器依据任务特定规则生成一系列6自由度末端执行器路点,低层强化学习策略则将路点转化为连续力矩指令,驱动软体臂完成稳定、无碰撞的演示轨迹。
特点
ManiSoft数据集的核心特点在于其专注于软体连续体机器人的视觉-语言操作,填补了现有刚性臂基准的空白。数据集包含四个层级递进的任务——收集、对齐、堆叠与排列,分别考察基础末端协调、精细姿态调整、接触丰富的层叠操作以及空间推理与避障能力。其模拟器创新性地通过弹性力约束将软体动力学与刚性交互耦合,实现了对可变形体与环境接触的逼真模拟。数据集包含6,300个场景-轨迹对,其中干净场景2,100个、随机化场景4,200个,每场景平均配备40条语言指令,覆盖17类109个可操作物体与35类154个障碍物,轨迹平均长度达1,272步,充分体现了数据规模与复杂度的双重挑战。
使用方法
ManiSoft数据集的使用方法围绕视觉-语言操作策略模型的训练与评估展开。每个时间步,策略模型接收一条语言指令与当前视觉观测(RGB图像),输出外部力矩与末端执行器状态等动作指令。数据集刻意不提供软体臂的内部本体状态,迫使模型仅从视觉信息推断臂构型与变形,增加了本体状态估计与可变形策略规划的难度。评估指标包括任务成功率与执行步数效率。研究者可直接使用专家轨迹进行模仿学习或离线强化学习,也可通过提供的模拟栈对模型进行在线评估。基准实验显示,扩散策略与OpenVLA-OFT在干净场景下性能较优,但在随机化场景中性能显著下降,突显了视觉本体感知与可变形利用的瓶颈。
背景与挑战
背景概述
ManiSoft数据集的创建源于对软体连续性机器人在视觉-语言操作领域研究的迫切需求。由北京航空航天大学、杭州创新研究院及新加坡国立大学的研究人员共同于2026年提出,该数据集旨在解决传统刚性机械臂在杂乱或受限空间中适应性不足的核心问题。ManiSoft通过构建一个耦合软体动力学与环境交互的定制化仿真器,定义了四项从基础端执行器协调到避障操作的多样化任务,并生成了6300个包含专家轨迹的场景。该数据集填补了软体机器人视觉-语言操作基准的空白,为推动相关领域研究提供了关键测试平台,预计将对人机协作、服务机器人等应用产生深远影响。
当前挑战
ManiSoft所面临的挑战集中体现在三个方面。首先,在领域问题层面,软体机器人因缺乏精准本体感知而面临复杂的运动学控制难题,其分布式低层驱动产生的高维耦合动作空间使得稳定协调行为的生成极具挑战。其次,在数据集构建过程中,核心挑战在于开发能同时准确模拟弹性动力学与丰富环境接触的混合仿真器,这需要融合软体与刚体仿真系统的优势。此外,大规模高质量专家轨迹的生成也构成挑战,必须通过分层规划与强化学习结合的机制来克服直接生成扭矩序列的困难,确保轨迹的稳定性和无碰撞特性。
常用场景
经典使用场景
ManiSoft作为面向软体连续臂的视觉-语言操作基准,其最经典的使用场景在于评估和比较各类策略模型在变形体操控任务中的表现。该数据集设计了四项具有代表性的任务:收集、对齐、堆叠和排列,分别从基础末端执行器协调、精细姿态调整、接触丰富环境下的精准控制以及复杂空间推理与避障等维度,系统性地审视软体臂在视觉-语言引导下的操控能力。研究者可利用ManiSoft提供的多样化场景与专家轨迹,对扩散策略、视觉-语言-动作模型等前沿方法进行标准化评测,从而揭示软体臂特有的失败模式。
衍生相关工作
ManiSoft的发布催生了一系列相关研究工作的开展。在方法层面,针对其揭示的视觉本体感知估计难题,研究者开发了基于形态学先验的感知增强模块,通过引入物理约束提升对软体臂关节状态的推断精度。在策略层面,涌现出融合扩散模型与强化学习的混合框架,有效缓解了确定性策略在抓取后出现的停滞行为。此外,基于ManiSoft的障碍物场景,部分工作探索了隐式柔顺表征学习,使软体臂能够自适应地利用形变绕过后方障碍。这些衍生工作共同推动了软体操控从简单轨迹跟踪向智能规划与感知的方向演进。
数据集最近研究
最新研究方向
在当前具身智能领域,软体机器人因其连续形变能力在复杂环境中展现出刚性机械臂难以企及的适应性,然而其固有的自感知模糊性与分布式底层驱动特性给视觉-语言操控带来了严峻挑战。ManiSoft基准数据集应运而生,通过精巧的弹性力约束耦合软体动力学与刚体交互仿真,构建了涵盖收集、对齐、堆叠和排列的四类任务。该研究成果揭示了现有策略模型在随机化场景下性能显著退化,其根本瓶颈在于视觉自感知状态估计的失准以及对软体形变规避能力的利用不足,为下一代融合形变智能与高级语义推理的操控方法提供了关键验证平台。
相关研究论文
- 1ManiSoft: Towards Vision-Language Manipulation for Soft Continuum Robotics北京航空航天大学; 北京航空航天大学·杭州创新研究院; 新加坡国立大学 · 2026年
以上内容由遇见数据集搜集并总结生成


