MixtureVitae
收藏arXiv2025-09-30 更新2025-11-21 收录
下载链接:
https://hf-mirror.com/datasets/ontocord/MixtureVitae-211BT
下载链接
链接失效反馈官方服务:
资源简介:
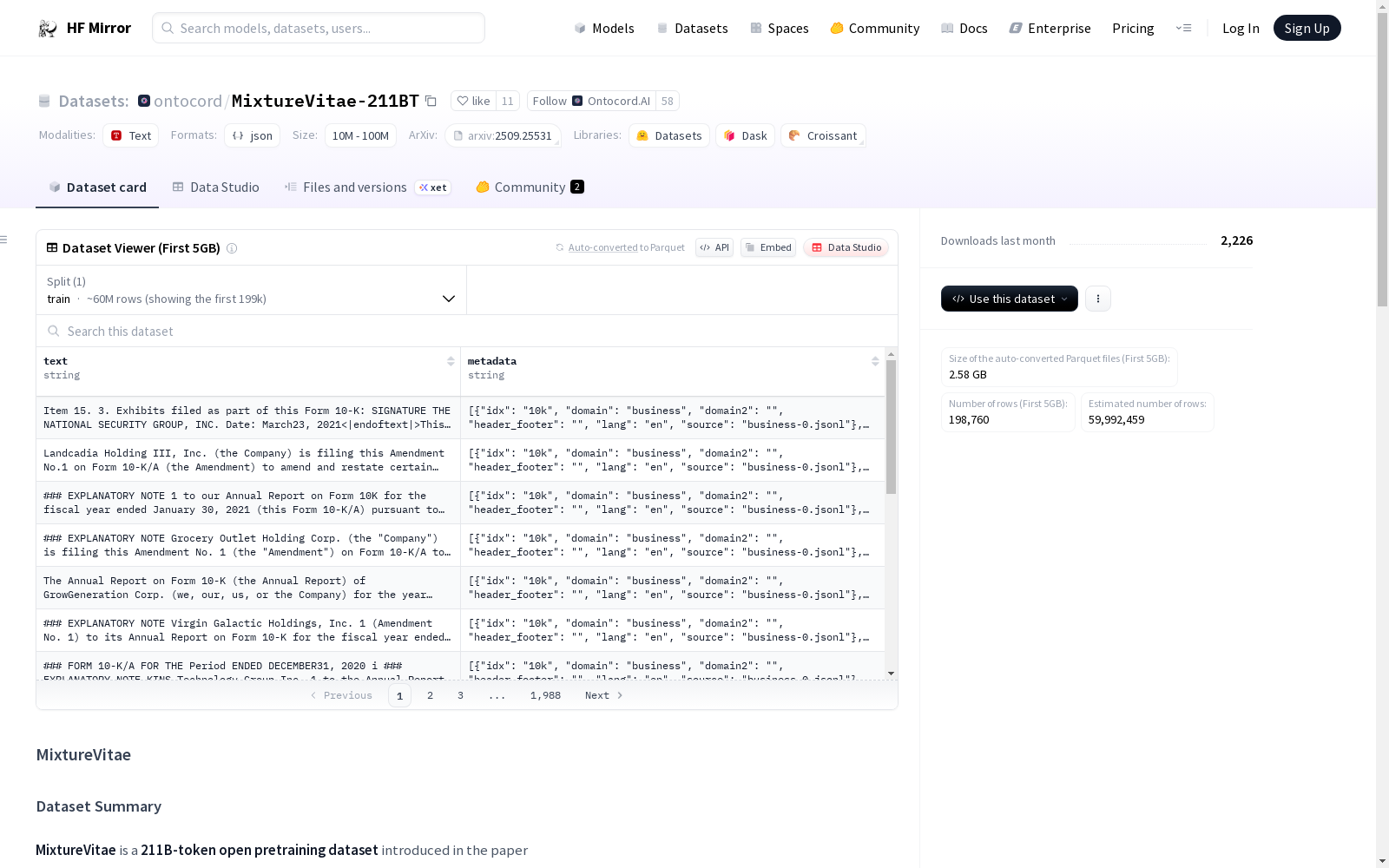
MixtureVitae是一个开放获取的预训练语料库,旨在在最小化法律风险的同时提供强大的模型性能。该数据集遵循一种风险缓解的采购策略,将公共领域和许可文本(例如,CC-BY/Apache)与精心论证的低风险添加内容(例如,政府作品和符合欧盟TDM资格的来源)相结合,以及具有明确来源的指令、推理和合成数据。MixtureVitae由三个主要类别组成:用于特定领域专业知识的精选来源、用于语言和通用知识的多样化网络数据以及用于增强推理和任务完成的指令遵循和推理数据集。数据集由三个主要类别组成:用于特定领域专业知识的精选来源、用于语言和通用知识的多样化网络数据以及用于增强推理和任务完成的指令遵循和推理数据集。数据集创建过程包括许可过滤、安全过滤、质量过滤、去重和领域感知混合等阶段。
MixtureVitae is an open-access pre-training corpus designed to deliver robust model performance while minimizing legal risks. This dataset follows a risk-mitigated sourcing strategy, combining public domain and licensed texts (e.g., CC-BY/Apache) with carefully justified low-risk additions (e.g., government works and sources eligible for EU TDM), as well as instruction, reasoning, and synthetic data with explicit provenance. MixtureVitae consists of three main categories: curated sources for domain-specific expertise, diverse web data for linguistic and general knowledge, and instruction-following and reasoning datasets for enhanced reasoning and task completion. The dataset consists of three main categories: curated sources for domain-specific expertise, diverse web data for linguistic and general knowledge, and instruction-following and reasoning datasets for enhanced reasoning and task completion. The dataset creation process includes stages such as license filtering, safety filtering, quality filtering, deduplication, and domain-aware mixing.
提供机构:
LAION, Open-Ψ (Open-Sci)Collective, Carnegie Mellon University, Salesforce, Detomo Inc., Institute of Science Tokyo, École Polytechnique, IP Paris, ELLIS Institute Tuebingen, University of Freiburg, NASK, Montreal Institute for Learning Algorithms, University of Montreal, Université de Montréal, RSS Lab, LTH / DeepTensor AB
创建时间:
2025-09-30
搜集汇总
数据集介绍
构建方式
在大规模语言模型开发面临法律合规挑战的背景下,MixtureVitae采用风险缓释策略构建预训练语料库。该数据集通过多阶段流水线整合公共领域文本、明确许可内容与针对性合成数据,涵盖网页数据、专业领域知识及指令推理三大类别。构建过程包含许可感知过滤、安全质量筛查及领域感知混合等关键环节,最终形成211.1B令牌规模的透明可复现语料库。
特点
本数据集最显著的特征在于其法律合规框架设计,通过三级风险分级体系确保数据来源的合法性。第一层级包含明确开放许可内容,第二层级整合经过筛选的代码仓库,第三层级纳入政府出版物等低风险材料。在内容构成上,数据集特别强化数学推理与编程能力训练,其指令推理数据占比达42%,代码技术内容占比20%,这种定向增强使模型在数学编码任务中表现卓越。
使用方法
研究人员可采用标准Transformer架构直接在该数据集上进行预训练,建议参照open-sci-ref协议控制模型规模与训练令牌预算以实现最佳效果。数据集已按领域分类组织,支持均匀采样或领域加权采样策略。针对不同计算预算,提供50B与300B令牌的子集版本,用户可通过重复采样扩展训练数据。评估时需注意对基准测试集进行去污染处理,以确保性能评估的准确性。
背景与挑战
背景概述
MixtureVitae数据集由Ontocord、LAION与Open-Ψ等机构联合研发,于2025年提出,旨在构建一个兼顾高性能与法律合规性的大规模预训练语料库。该数据集聚焦于解决大语言模型开发中普遍存在的版权争议问题,通过整合公共领域文本、明确许可内容与风险缓释数据,为人工智能研究提供了法律风险可控的基础资源。其核心创新在于采用“许可优先”策略,结合高质量指令与推理数据,显著提升了模型在数学推理与代码生成等复杂任务中的表现,为合规性语言模型训练树立了新范式。
当前挑战
在领域问题层面,MixtureVitae致力于克服传统语言模型训练依赖未经授权网络爬取数据的法律困境,需在保证模型竞争力的同时实现版权风险最小化。构建过程中面临多重挑战:其一,需设计精细的许可过滤管道,从海量数据中识别符合公共领域或开放许可的内容;其二,需通过合成数据生成技术弥补纯许可数据中指令与推理资源的稀缺性;其三,需建立跨领域数据混合机制,平衡语言多样性、知识密度与训练效率,同时确保数据来源的可追溯性与合规性验证。
常用场景
经典使用场景
在大型语言模型预训练领域,MixtureVitae数据集通过融合公共领域文本、宽松许可内容与针对性合成数据,构建了法律风险最小化的训练语料库。其经典应用场景体现在为130M至1.7B参数规模的模型提供高质量预训练数据,在数学推理与代码生成任务中展现出显著优势。该数据集采用领域感知混合策略,将百科全书、学术论文、代码仓库等六类核心内容按比例组合,形成具有语义连贯性的训练样本。
衍生相关工作
该数据集推动了合规预训练技术路线的发展,其分层风险缓解策略被后续研究如Apertus等项目借鉴。在数据合成方向,启发了基于宽松许可模型的指令数据生成方法,为OpenMathInstruct等数学推理数据集提供技术参照。其公开的清洗流程与去重标准成为Dolma等开源工具链的重要参考,而领域感知混合方法则被应用于多模态数据的组织策略。这些衍生工作共同构建起以法律合规为基石的开放式模型研发生态。
数据集最近研究
最新研究方向
在大规模语言模型预训练领域,MixtureVitae数据集的研究聚焦于构建合法风险最小化的开放语料库,通过整合公共领域文本、宽松许可内容及针对性合成数据,推动模型在数学推理与代码生成任务上的显著性能提升。该数据集采用透明化多阶段处理流程,强调数据来源的可追溯性与法律合规性,有效应对当前因 indiscriminate 网络爬取引发的版权争议。其前沿探索揭示了无需依赖高风险版权材料即可训练高性能模型的可行性,为人工智能研究的可持续发展提供了重要实践范例。
相关研究论文
- 1通过LAION, Open-Ψ (Open-Sci)Collective, Carnegie Mellon University, Salesforce, Detomo Inc., Institute of Science Tokyo, École Polytechnique, IP Paris, ELLIS Institute Tuebingen, University of Freiburg, NASK, Montreal Institute for Learning Algorithms, University of Montreal, Université de Montréal, RSS Lab, LTH / DeepTensor AB · 2025年
以上内容由遇见数据集搜集并总结生成


