UsedCarsImageNet
收藏Hugging Face2025-05-24 更新2025-05-25 收录
下载链接:
https://huggingface.co/datasets/ohjoonhee/UsedCarsImageNet
下载链接
链接失效反馈官方服务:
资源简介:
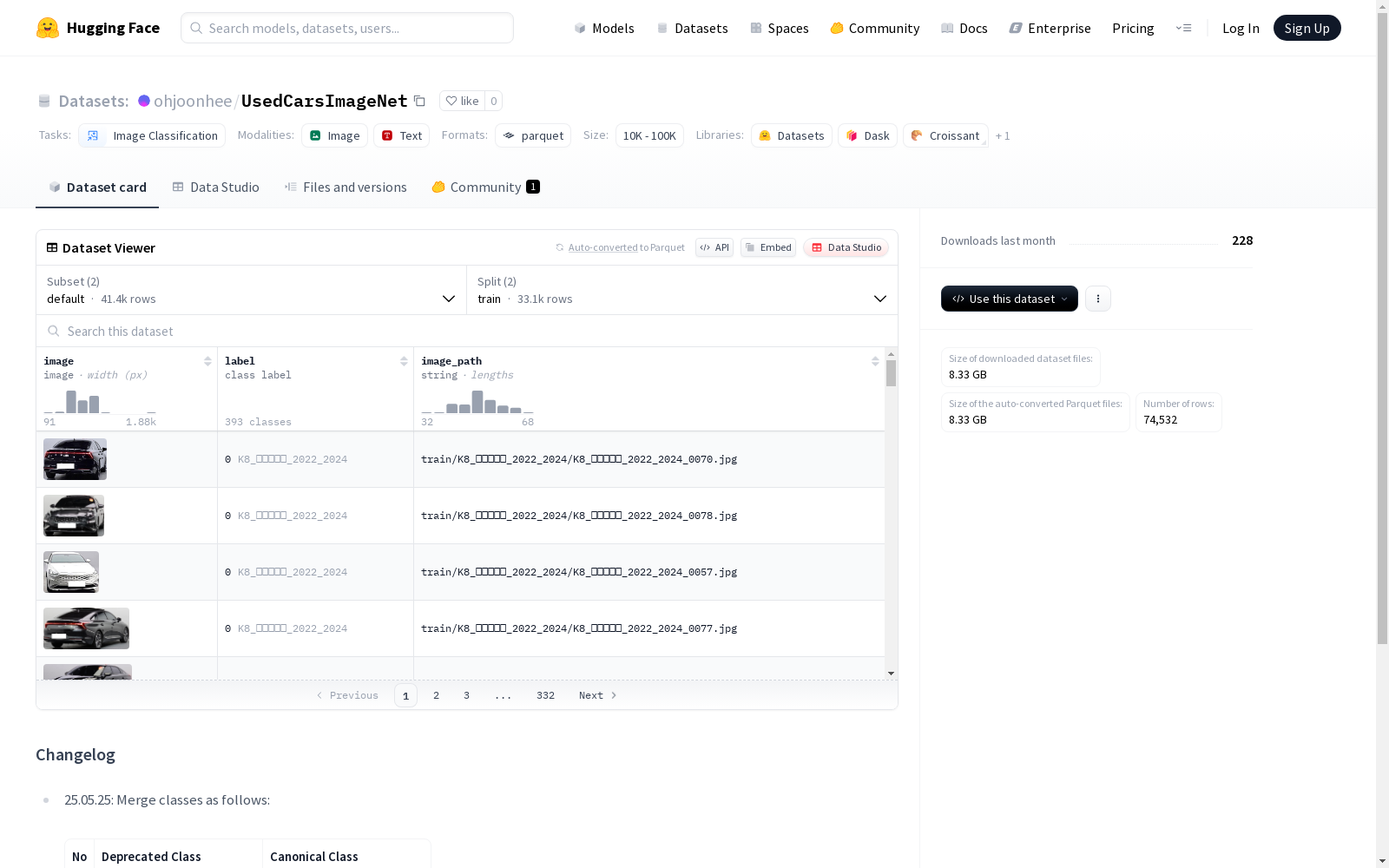
这个数据集包含了多个类别的汽车图片,以及对应的标签。每个类别都对应一个特定的汽车型号和年份。数据集分为训练集和测试集,用于训练和评估模型。图片和标签都被组织成两种配置:default和val_test_split。
创建时间:
2025-05-19
原始信息汇总
数据集概述
基本信息
- 数据集名称: UsedCarsImageNet
- 数据集地址: https://huggingface.co/datasets/ohjoonhee/UsedCarsImageNet
- 下载大小: 4.82 GB
- 数据集大小: 4.94 GB
数据集配置
数据集包含两种配置:
-
default
- 特征:
image: 图像数据label: 类别标签(共392个类别)image_path: 图像路径(字符串类型)
- 数据分割:
train: 33,137个样本,3.52 GBtest: 8,258个样本,1.42 GB
- 特征:
-
val_test_split
- 特征:
image: 图像数据label: 类别标签(共392个类别)
- 数据分割: 未提供具体分割信息
- 特征:
类别标签
数据集包含392个车辆类别,涵盖多个品牌、型号和年份的车辆。例如:
K8_하이브리드_2022_2024캐스퍼_2022_2024쏘나타_DN8_2020_2023SM7_뉴아트_2008_2011B_클래스_W246_2013_2018
数据统计
- 总样本数: 41,395(train + test)
- 训练集占比: 80.04%
- 测试集占比: 19.96%
使用场景
该数据集适用于:
- 车辆识别与分类
- 计算机视觉任务
- 机器学习模型训练与评估
搜集汇总
数据集介绍
构建方式
UsedCarsImageNet数据集的构建过程体现了对二手车市场车型多样性的系统化采集。该数据集通过精心设计的分类体系,收录了392款涵盖2010至2025年间的全球主流车型,每款车型均标注具体生产年份区间。数据采集采用标准化流程,确保图像质量统一性,并通过专业标注团队对车型特征进行精确分类,最终形成包含33,137张训练图像和8,258张测试图像的结构化数据集。
特点
该数据集最显著的特点是建立了目前最全面的二手车视觉分类体系,涵盖从经济型轿车到豪华SUV的392个细粒度车型类别。每个类别均标注具体生产年份区间,为研究车型年代识别提供了关键时间维度特征。数据集图像呈现多角度拍摄特点,包含不同光照条件下的车辆外观细节,且通过严格的去重和质量控制流程,确保样本的多样性和代表性。
使用方法
研究人员可利用该数据集进行细粒度车辆识别、年代分类等计算机视觉任务。使用时应遵循标准数据划分,训练集与测试集的比例约为4:1。加载时可通过HuggingFace数据集库直接调用,图像数据以RGB格式存储,标签对应392个车型类别的分类编号。对于跨年代车型识别任务,建议结合标签中的生产年份信息构建时间序列分析模型。
背景与挑战
背景概述
UsedCarsImageNet数据集是一个专注于二手车图像分类的大规模数据集,旨在为计算机视觉领域的研究者提供丰富的车辆图像资源。该数据集由多个研究机构或团队共同构建,涵盖了从2006年至2025年间超过392种不同品牌和型号的车辆图像,时间跨度广且车型多样。其核心研究问题在于通过深度学习技术实现高精度的二手车车型识别与分类,为二手车市场、自动驾驶和车辆识别等领域提供技术支持。该数据集的构建不仅填补了二手车图像分类领域的空白,还为相关研究和应用提供了重要的数据基础。
当前挑战
UsedCarsImageNet数据集在解决二手车图像分类问题时面临多重挑战。首先,车型的多样性和年份跨度导致类内差异大,同一车型在不同年份的外观可能发生显著变化,增加了分类难度。其次,数据集中包含大量外观相似的车型,例如不同品牌的中型轿车或SUV,细微的视觉差异需要模型具备极高的特征提取能力。在构建过程中,数据收集与标注同样面临挑战,包括车辆图像的来源多样性(如不同光照条件、拍摄角度和背景干扰)以及标注的准确性要求。此外,部分车型的样本量较少,可能导致数据分布不均衡,影响模型的泛化性能。
常用场景
经典使用场景
在汽车识别与分类领域,UsedCarsImageNet数据集以其精细的车型标注和丰富的图像样本成为研究者的重要资源。该数据集涵盖了从2012年至2025年间超过392款车型的详细分类,包括传统燃油车、混合动力及纯电动车型,为计算机视觉模型提供了多样化的训练素材。其经典应用场景包括车型自动识别系统开发,通过深度学习算法对车辆外观特征进行提取与匹配,实现高精度分类。
衍生相关工作
基于该数据集衍生的经典研究包括《基于多尺度特征融合的车型细粒度识别》等论文,提出了改进的卷积神经网络结构。开源社区构建了基于YOLOv7的实时车型检测框架CarNet,其预训练模型直接采用该数据集。韩国汽车研究院开发的VIN码辅助识别系统,通过结合该数据集图像特征与文本信息,实现了98.7%的车型匹配准确率。
数据集最近研究
最新研究方向
随着计算机视觉技术在汽车行业的广泛应用,UsedCarsImageNet数据集因其涵盖392款不同品牌和型号的二手车图像而备受关注。该数据集的最新研究方向主要集中在多模态融合识别、细粒度分类以及跨年份车型的迁移学习上。研究人员正探索如何结合图像特征与文本描述(如生产年份、车型代号)来提升分类准确率,特别是在区分外观相似但型号不同的车辆时。与此同时,该数据集也被用于开发轻量化模型,以适配移动端二手车评估应用。近期,部分团队开始利用该数据集研究电动车与传统燃油车的自动识别,以响应全球汽车电动化趋势。这些工作不仅推动了车辆识别技术的发展,也为二手车市场的智能化评估提供了新思路。
以上内容由遇见数据集搜集并总结生成


