DiTEC-WDN
收藏arXiv2025-03-21 更新2025-03-25 收录
下载链接:
https://huggingface.co/datasets/rugds/ditec-wdn
下载链接
链接失效反馈官方服务:
资源简介:
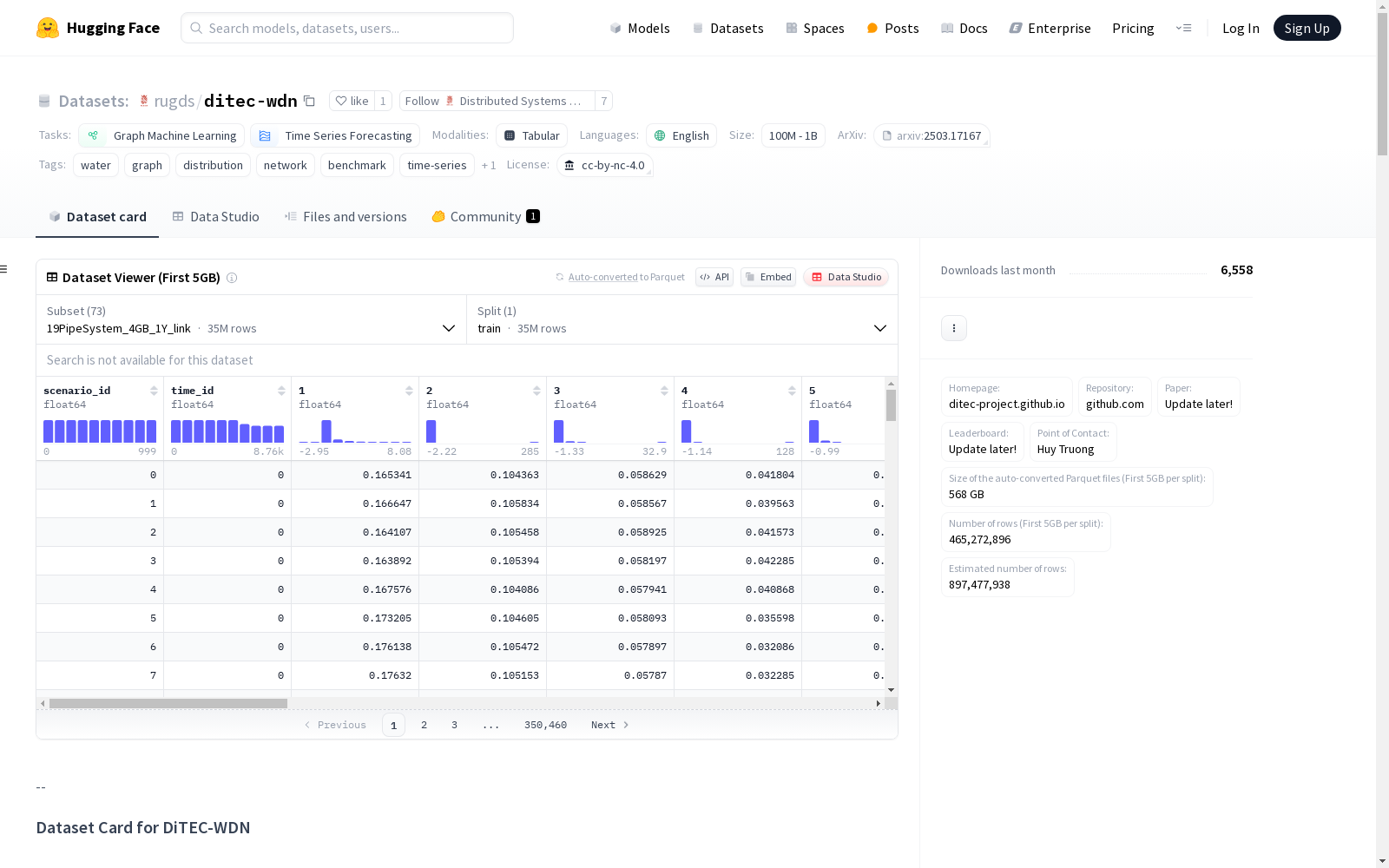
DiTEC-WDN是一个大规模的水力情景数据集,由荷兰格罗宁根大学伯努利学院和阿姆斯特丹大学信息学院共同创建。该数据集包含36,000个独特的模拟场景,覆盖短期(24小时)和长期(1年)周期。通过自动化的管道优化关键参数,生成228百万个基于规则验证和事后分析的离散、合成但水力现实的网络状态。该数据集支持多种机器学习任务,如图级、节点级和链接级回归以及时间序列预测,为水 distribution 网络领域的研究提供了一个大型基准数据集。
DiTEC-WDN is a large-scale hydraulic scenario dataset jointly created by the Bernoulli Institute of the University of Groningen and the School of Informatics of the University of Amsterdam, the Netherlands. This dataset contains 36,000 unique simulation scenarios covering both short-term (24-hour) and long-term (1-year) cycles. Through automated, pipeline-based optimization of critical parameters, it generates 228 million discrete, synthetic yet hydraulically realistic network states validated via rule-based verification and post-hoc analysis. This dataset supports a variety of machine learning tasks including graph-level, node-level, link-level regression and time series forecasting, providing a large-scale benchmark dataset for research in the field of water distribution networks.
提供机构:
荷兰格罗宁根大学伯努利学院,荷兰阿姆斯特丹大学信息学院
创建时间:
2025-03-21
搜集汇总
数据集介绍
构建方式
DiTEC-WDN数据集通过自动化流程构建,基于36个公开可用的供水网络(WDN)模型,采用EPANET和WNTR物理仿真工具生成合成数据。该流程优化关键水力参数(如压力、流量和需求模式),并通过规则验证和后分析确保生成的离散状态具有水力现实性。数据集包含短期(24小时)和长期(1年)模拟场景,总计生成2.28亿个基于图的状态快照,覆盖多种水力条件。
特点
DiTEC-WDN数据集以其规模大、多样性高和合成数据的隐私安全性著称。数据集包含36,000个独特场景,每个场景均具有独立的节点需求模式,避免了现有数据集中需求模式重复使用的问题。通过自动需求生成算法(ADG)和社区检测技术,数据集模拟了真实世界中的家庭和商业用水行为差异,并引入极端需求和零需求节点以增强数据多样性。此外,数据集支持图级、节点级和链路级回归以及时间序列预测等多种机器学习任务。
使用方法
DiTEC-WDN数据集以压缩的.parquet文件格式提供,支持高效读取和处理。用户可通过Hugging Face平台访问数据,并利用多核处理能力进行大规模分析。数据集适用于训练数据驱动的深度学习模型,如替代建模、状态估计和需求预测。用户需注意,数据集未包含异常情况(如泄漏)和流向信息,但可通过转换输入参数为.INP文件并重新仿真来补充。数据加载时需预处理跳过特定节点,并参考元数据中的邻接表分析图拓扑结构。
背景与挑战
背景概述
DiTEC-WDN是由荷兰格罗宁根大学Bernoulli研究所的Huy Truong和Andrés Tello等人于2025年提出的一个大规模水力场景数据集,旨在解决水资源分配网络(WDN)研究中真实数据稀缺的问题。该数据集包含36,000个独特场景,模拟了36个不同水网在短期(24小时)和长期(1年)内的水力状态,生成了2.28亿个基于图的网络状态快照。DiTEC-WDN通过自动化流程优化关键参数(如压力、流量和需求模式),并利用规则验证和后验分析生成离散但水力真实的合成数据。这一数据集支持多种机器学习任务,如图级、节点级和链接级回归以及时间序列预测,为水资源领域的研究提供了重要的基准数据。
当前挑战
DiTEC-WDN面临的挑战主要包括两方面:领域问题的挑战和构建过程的挑战。在领域问题方面,水资源分配网络的复杂性和动态性使得数据驱动的机器学习方法难以直接应用,尤其是真实数据的隐私限制导致数据共享困难。此外,节点需求模式的稀缺性和重复使用问题进一步限制了模型的鲁棒性和多样性。在构建过程中,数据生成涉及高维参数空间的优化,如节点高程、管道直径等参数的采样策略和范围确定,这需要通过改进的粒子群优化(PSO)算法解决。同时,确保生成数据的真实性和水力稳定性也是一大挑战,需通过严格的规则验证和统计指标(如四分位距)来保证数据的多样性和实用性。
常用场景
经典使用场景
在水利工程与机器学习交叉领域,DiTEC-WDN数据集通过构建36个供水网络的22.8亿个水力状态快照,为图神经网络、时间序列预测等任务提供了标准化基准。其多尺度模拟特性(24小时短期与1年长期)特别适用于研究供水系统在昼夜周期和季节性变化下的动态行为,例如通过节点级回归分析预测管网压力波动,或基于链路级流量数据优化泵站调度策略。
解决学术问题
该数据集有效解决了供水网络研究中真实数据稀缺的瓶颈问题,其合成的多样化水力场景(涵盖压力、流量、需求模式等38个参数)打破了传统研究中因隐私限制导致的数据同质化困局。通过自动生成的独特节点需求模式,克服了既有数据集(如LeakDB)中模式重复使用导致的模型过拟合问题,为数据驱动的水力模型校准、不确定性量化等前沿课题提供了可靠验证平台。
衍生相关工作
基于该数据集衍生的经典工作包括Truong等人开发的图神经网络压力估计模型(Water Resources Research 2024),以及Kerimov提出的边缘图神经网络元模型(Water Research 2024)。其标准化格式还催生了BattLeDIM等国际竞赛,推动了泄漏检测算法的横向比较。数据集构建方法中的水力参数优化策略(HSPO)更被拓展应用于配电网等关键基础设施建模领域。
以上内容由遇见数据集搜集并总结生成


