MedicalNarratives
收藏arXiv2025-01-08 更新2025-01-10 收录
下载链接:
https://medical-narratives.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
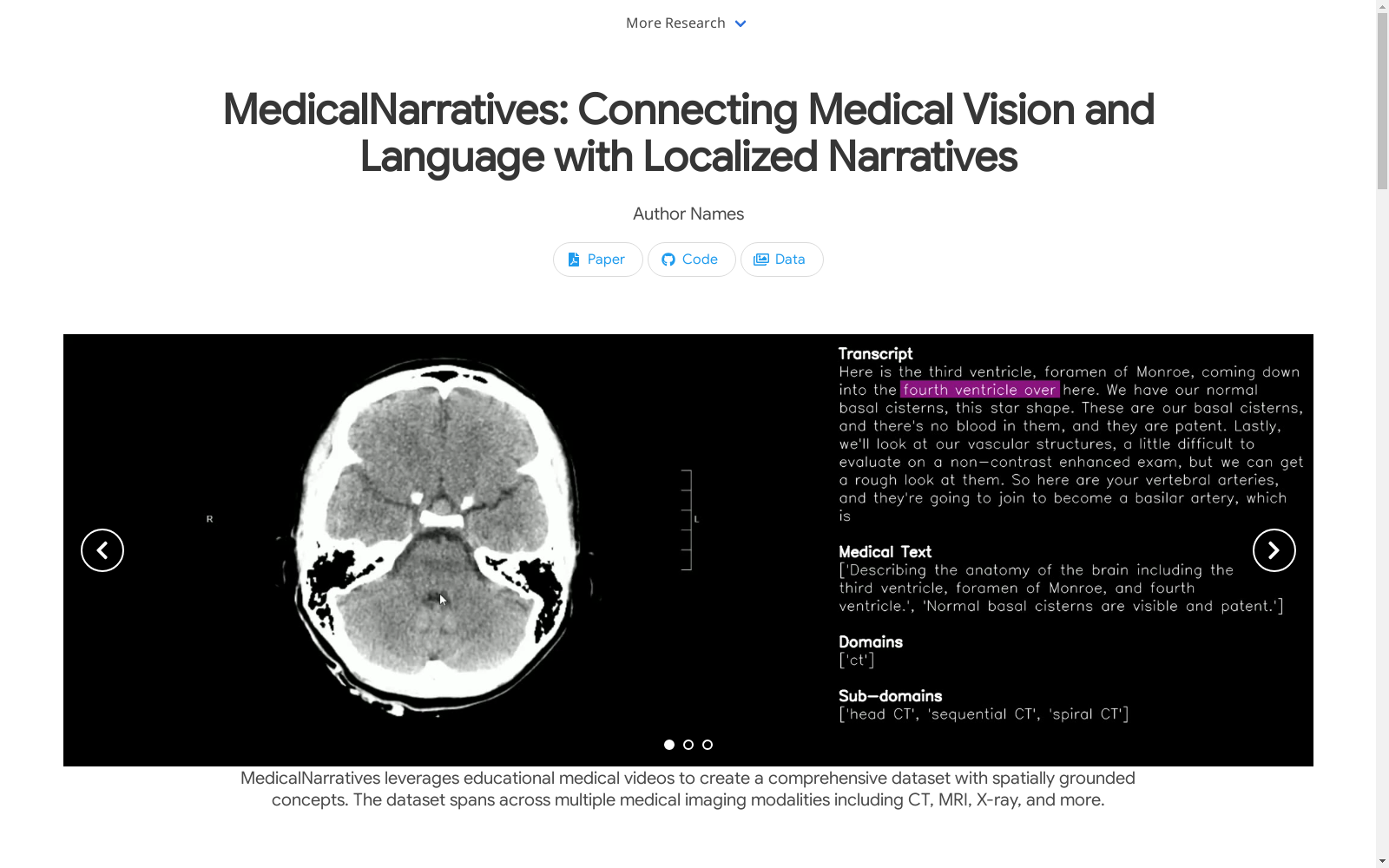
MedicalNarratives数据集由华盛顿大学的研究团队创建,旨在通过医学教学视频中的语音和鼠标光标移动同步收集图像-文本对,以解决医学图像分析中语义和密集任务训练数据不足的问题。该数据集包含470万对图像-文本数据,其中100万样本包含密集注释,如轨迹和边界框。数据来源于医学教学视频和文章,涵盖了12个医学领域。数据集的应用领域包括医学图像的分类、分割、检测和疾病监测等任务,旨在通过提供丰富的多模态数据,提升医学图像分析的模型性能。
The MedicalNarratives dataset was developed by a research team at the University of Washington. It aims to synchronously collect image-text pairs using speech and mouse cursor movement data from medical teaching videos, so as to address the shortage of training data for semantic and dense tasks in medical image analysis. This dataset contains 4.7 million image-text pairs, among which 1 million samples are equipped with dense annotations such as trajectories and bounding boxes. The data is sourced from medical teaching videos and articles, covering 12 medical fields. Its application scenarios include tasks such as medical image classification, segmentation, detection and disease monitoring, and it is designed to improve the performance of medical image analysis models by providing rich multimodal data.
提供机构:
华盛顿大学
创建时间:
2025-01-08
搜集汇总
数据集介绍
构建方式
MedicalNarratives数据集通过从医学教学视频中提取图像-文本对构建而成,结合了教师的语音和鼠标光标移动的同步数据。数据集的构建过程包括从YouTube和PubMed中筛选相关视频和文章,提取关键帧、语音转录、去噪处理,并将图像、文本和光标轨迹进行对齐。数据集包含470万图像-文本对,其中100万样本包含密集注释,如轨迹和边界框。
特点
MedicalNarratives数据集的特点在于其多模态性,涵盖了12个医学领域的图像和文本数据,并且通过光标轨迹实现了图像区域与文本描述的精确对齐。数据集中的图像来自多种医学成像模式,如X射线、CT、MRI和病理学图像,且每张图像都配有详细的医学描述和区域注释。此外,数据集还包含丰富的元数据,如UMLS实体和子领域分类,便于进行多任务学习。
使用方法
MedicalNarratives数据集可用于训练多模态医学模型,支持语义任务(如分类、检索)和密集任务(如分割、检测)。通过该数据集,可以预训练视觉-语言模型,如GENMEDCLIP,并在医学图像分类、检索等任务中评估模型性能。数据集还可用于生成多模态语言模型和图像生成模型,进一步推动医学图像分析领域的研究。
背景与挑战
背景概述
MedicalNarratives数据集由华盛顿大学的研究团队于2025年创建,旨在通过结合医学教学视频中的语音和鼠标光标轨迹,构建一个多模态的医学图像-文本数据集。该数据集包含470万张图像-文本对,其中100万样本带有密集注释,涵盖12个医学领域。其核心研究问题是通过同步的语音和光标轨迹,捕捉医学图像的空间区域与临床理解之间的联系,从而支持语义任务(如分类、描述)和密集任务(如分割、检测)的联合训练。该数据集对医学图像分析领域具有重要意义,尤其是在多模态医学数据的生成和理解方面。
当前挑战
MedicalNarratives数据集面临的挑战主要包括两个方面:首先,医学图像分析领域缺乏能够同时处理语义和密集任务的大规模数据集,导致模型训练时需要在不同任务之间进行分离训练。其次,数据集的构建过程中,如何从非结构化的教学视频中提取并同步语音、图像和光标轨迹是一个复杂的问题。视频中的噪声、语音识别的准确性、以及光标轨迹的提取都增加了数据处理的难度。此外,医学领域的专业术语和多样化的图像模态(如X光、CT、MRI等)也使得数据集的构建更具挑战性。
常用场景
经典使用场景
MedicalNarratives数据集广泛应用于医学图像分析领域,特别是在医学图像与文本的多模态任务中。该数据集通过同步记录医学教学视频中的语音和鼠标光标轨迹,提供了丰富的图像-文本对,能够用于训练和评估医学图像分类、分割、检测等任务。其经典使用场景包括医学图像的语义理解、区域定位以及多模态生成任务。
实际应用
在实际应用中,MedicalNarratives数据集被用于开发医学图像的多模态生成模型和区域定位模型。例如,基于该数据集训练的GENMEDCLIP模型在医学图像分类和检索任务中表现优异,能够帮助医生快速定位病变区域并生成相应的医学报告。此外,该数据集还可用于开发医学教育工具,帮助医学生通过视频和图像学习医学知识。
衍生相关工作
MedicalNarratives数据集衍生了许多相关的研究工作,特别是在医学多模态生成模型和区域定位模型方面。例如,基于该数据集训练的Quilt-LLaVA模型在病理学图像的空间推理任务中表现出色,能够生成与图像区域相关的详细描述。此外,PathNarratives模型利用该数据集的结构,提供了可解释的诊断线索,增强了人类与AI在医学诊断中的协作能力。
以上内容由遇见数据集搜集并总结生成


