Reason-RFT-CoT-Dataset
收藏Hugging Face2025-04-04 更新2025-04-07 收录
下载链接:
https://huggingface.co/datasets/tanhuajie2001/Reason-RFT-CoT-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
Reason-RFT CoT数据集是一个用于视觉推理任务的强化微调框架的数据集。它包含了一系列任务,如视觉计数、结构感知和空间转换等,旨在通过监督微调和基于强化学习的方法来提高视觉语言模型的推理能力。该数据集适用于评估视觉认知、几何理解和空间泛化能力。
The Reason-RFT CoT dataset is a dataset tailored for the reinforcement fine-tuning framework of visual reasoning tasks. It includes a range of tasks such as visual counting, structure-aware perception, spatial transformation and others, aiming to enhance the reasoning capabilities of vision-language models via supervised fine-tuning and reinforcement learning-based methods. This dataset is suitable for evaluating visual cognition, geometric comprehension and spatial generalization capabilities.
创建时间:
2025-04-03
搜集汇总
数据集介绍
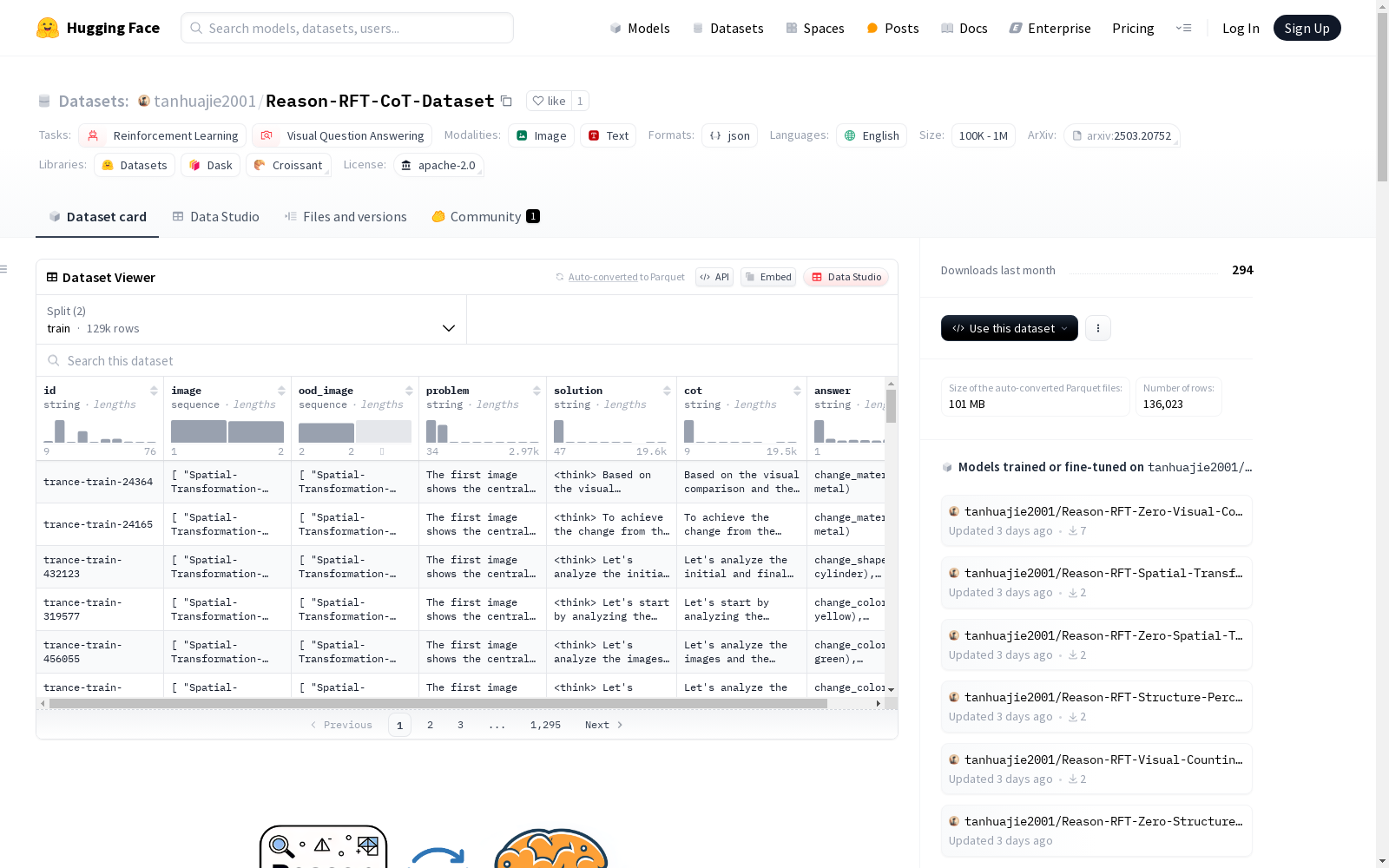
构建方式
在视觉推理领域,Reason-RFT-CoT-Dataset的构建采用了多阶段精细化的数据采集与标注策略。该数据集通过整合视觉计数、结构感知和空间变换三大核心任务,系统性地覆盖了视觉认知的多个维度。构建过程中首先收集了原始视觉问题数据,随后由专业标注团队采用思维链(Chain-of-Thought)方法进行多层次标注,确保每个问题都包含完整的推理过程。为增强数据多样性,团队还纳入了科学图表、拓扑结构和几何图形等特殊领域的视觉材料,并通过严格的交叉验证机制保证标注质量。
特点
该数据集最显著的特点是其在视觉推理任务上的全面性和系统性。数据集包含超过10万条标注样本,涵盖基础视觉认知到复杂空间推理的多个难度层次。特别值得注意的是,数据集设计了专门的域内和域外测试集,能够有效评估模型的泛化能力。数据样本均配有详细的思维链标注,为模型提供了明确的可解释性学习路径。此外,数据集还整合了科学图表、拓扑推理等特殊领域的视觉问题,为跨领域视觉理解研究提供了宝贵资源。
使用方法
使用该数据集时,建议采用两阶段训练策略:首先利用训练集中的思维链标注数据进行监督微调,随后通过强化学习框架进一步优化模型性能。数据集文件采用标准JSON格式存储,与图像文件分离管理,便于研究者灵活调用。评估阶段可使用预定义的域内和域外测试集,全面检验模型在已知场景和未知场景下的表现。为方便使用,项目提供了完整的下载脚本和目录结构说明,确保研究者能够快速部署实验环境。
背景与挑战
背景概述
视觉推理能力在理解复杂多模态数据方面扮演着关键角色,对于推动领域特定应用和人工通用智能(AGI)的发展具有重要意义。Reason-RFT-CoT-Dataset由Tan Huajie等人于2025年提出,旨在通过强化微调框架提升视觉语言模型(VLMs)的推理能力。该数据集作为项目“Reason-RFT: Reinforcement Fine-Tuning for Visual Reasoning”的核心组成部分,涵盖了视觉计数、结构感知和空间变换等多个任务,为系统评估视觉认知、几何理解和空间泛化能力提供了基准。其创新性在于结合了监督微调(SFT)和基于群体相对策略优化(GRPO)的强化学习,显著提升了模型在跨领域任务中的泛化性能。该数据集的发布为多模态研究领域注入了新的活力,推动了视觉推理技术的进一步发展。
当前挑战
Reason-RFT-CoT-Dataset在构建和应用过程中面临多重挑战。在领域问题方面,视觉推理任务本身具有高度复杂性,涉及对图像内容的理解、逻辑推理和空间关系的把握,这对模型的认知能力和泛化性能提出了极高要求。数据集的构建过程中,研究人员需克服标注成本高昂、数据多样性不足以及跨领域迁移困难等问题。此外,如何确保生成的链式思维(CoT)数据既能覆盖广泛的推理场景,又能避免过拟合和认知僵化,是另一个关键挑战。在技术实现层面,两阶段训练框架的设计与优化,尤其是强化学习阶段的策略优化,需要精细调参和大量计算资源,这对研究团队的技术能力和硬件条件提出了严峻考验。
常用场景
经典使用场景
在视觉推理领域,Reason-RFT-CoT-Dataset被广泛应用于训练和评估视觉语言模型的多模态推理能力。该数据集通过精心设计的视觉计数、结构感知和空间变换任务,为模型提供了丰富的推理场景。研究人员利用其链式思维(CoT)标注数据,能够系统地探索模型在跨域视觉认知、几何理解和空间泛化方面的表现,为视觉推理研究建立了标准化基准。
衍生相关工作
该数据集催生了多项视觉推理领域的创新研究,包括RoboBrain项目对具身推理能力的探索。基于其构建的Group Relative Policy Optimization方法已成为强化微调的新范式,相关技术被拓展至科学视觉推理(AI2D、ScienceQA)和拓扑推理(GVLQA)等细分领域,形成了一系列具有影响力的后续工作。
数据集最近研究
最新研究方向
在视觉推理领域,Reason-RFT-CoT-Dataset的推出标志着强化学习与思维链(CoT)方法融合的重要进展。该数据集通过整合视觉计数、结构感知和空间变换等多维度任务,为评估模型在跨域泛化能力方面提供了系统化基准。当前研究热点集中在探索Group Relative Policy Optimization(GRPO)算法如何优化视觉语言模型的推理过程,特别是在少样本学习场景下保持性能稳定性。与RoboBrain等具身智能项目的合作,进一步拓展了该数据集在机器人认知决策中的应用潜力。这种两阶段训练框架——监督微调与强化学习的结合,正在重新定义多模态推理任务的性能上限,为解决传统方法中的过拟合和认知僵化问题提供了新思路。
以上内容由遇见数据集搜集并总结生成


