test-big-dataset
收藏Hugging Face2024-08-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/huggingface/test-big-dataset
下载链接
链接失效反馈官方服务:
资源简介:
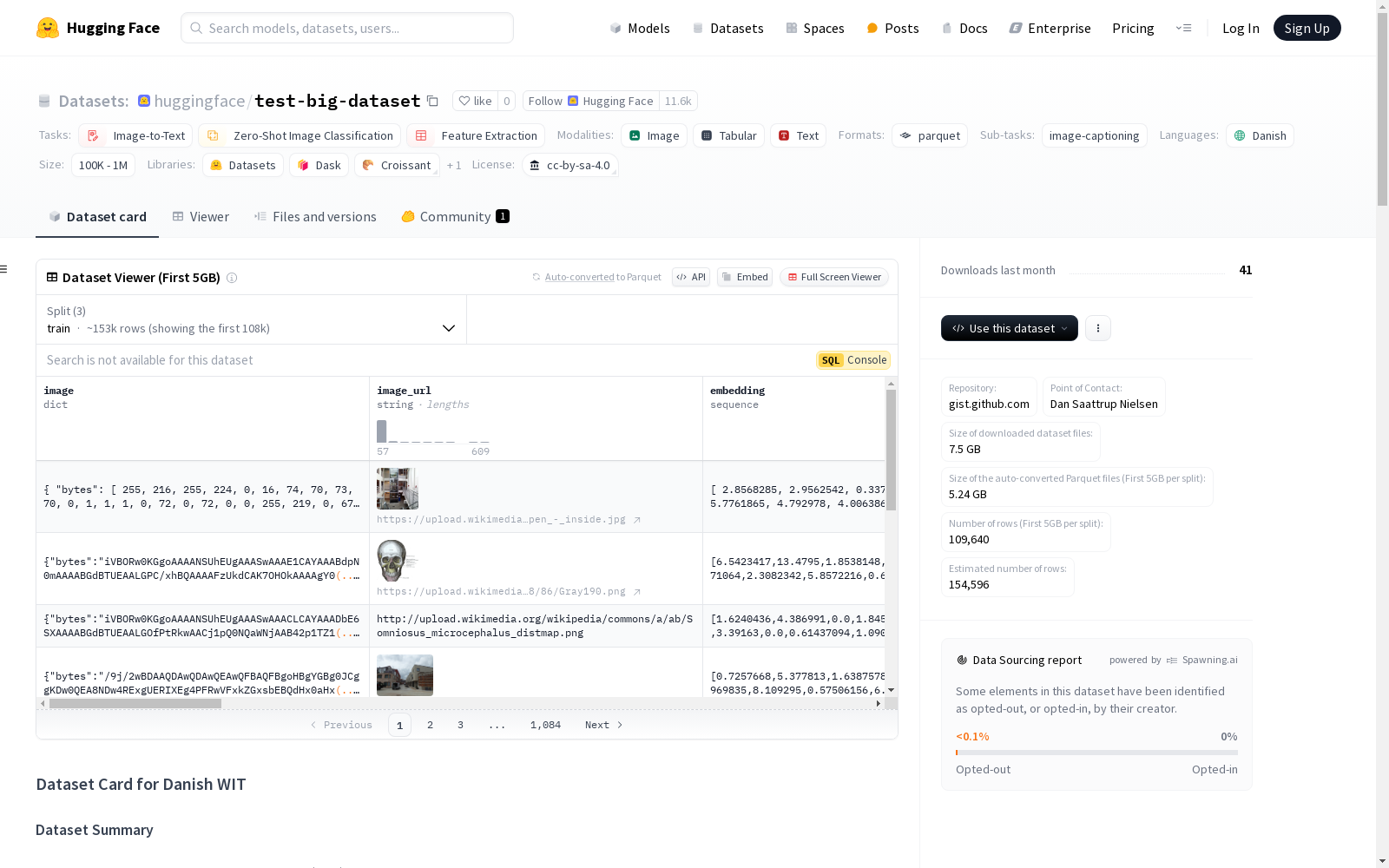
Danish WIT数据集是WIT-Base数据集的丹麦部分,包含约160,000张来自丹麦维基百科的图片及其对应的丹麦描述。该数据集主要用于图像描述生成、零样本图像分类和文本图像搜索等任务,并遵循CC BY-SA 4.0许可。
提供机构:
Hugging Face创建时间:
2024-08-20
搜集汇总
数据集介绍
构建方式
Danish WIT数据集是从WikiMedia的WIT-Base数据集中提取的丹麦语部分,旨在简化对丹麦语图像描述的研究。WIT-Base本身是Google WIT数据集的改进版本,移除了空描述、人脸覆盖超过10%的图像以及不适当的内容。该数据集包含约16万张图像及其丹麦语描述,数据格式为JSON,涵盖了图像的元数据、描述文本及相关的上下文信息。
特点
Danish WIT数据集以其丰富的丹麦语图像描述为特色,每张图像均附有详细的元数据和多层次的文本描述,包括标题、参考描述、页面上下文等。数据集还提供了图像的嵌入向量,便于进行文本-图像检索和零样本图像分类任务。其数据量适中,适合用于训练和验证多模态机器学习模型。
使用方法
该数据集适用于图像描述生成、零样本图像分类以及文本-图像检索等任务。用户可通过Hugging Face平台加载数据集,并利用其提供的图像和文本字段进行模型训练与评估。数据集已划分为训练集、验证集和测试集,便于直接用于机器学习实验。
背景与挑战
背景概述
Danish WIT数据集是Google于2021年7月发布的Wikipedia Image Text (WIT)数据集的一个子集,专注于丹麦语部分的图像与文本描述。该数据集由WikiMedia在2021年9月发布的WIT-Base版本衍生而来,剔除了无参考描述的图像以及包含超过10%人脸覆盖或不当内容的图像。数据集由Alexandra Institute的Dan Saattrup Nielsen负责整理,旨在为丹麦语的图像描述生成、零样本图像分类和文本-图像检索任务提供支持。其发布遵循CC BY-SA 4.0许可协议,为丹麦语自然语言处理研究提供了重要的多模态数据资源。
当前挑战
Danish WIT数据集在构建过程中面临多重挑战。首先,原始WIT-Base数据集规模庞大(333GB),从中提取丹麦语部分需要高效的数据筛选与处理技术。其次,确保图像描述的质量与语言一致性是另一大难题,尤其是在处理多语言环境下的文本-图像对齐问题时。此外,数据集中部分图像可能存在描述缺失或不准确的情况,这对模型的训练与评估提出了更高的要求。最后,如何在保证数据多样性的同时,避免引入偏见或不适当内容,也是数据集构建过程中需要解决的关键问题。
常用场景
经典使用场景
Danish WIT数据集在图像到文本生成任务中展现了其独特的价值,尤其是在丹麦语环境下的图像描述生成。该数据集通过提供大量带有丹麦语描述的图像,为研究人员和开发者提供了一个丰富的资源库,用于训练和评估图像描述生成模型。这些模型能够自动生成与图像内容相匹配的文本描述,极大地提升了图像理解与自然语言处理的结合能力。
衍生相关工作
基于Danish WIT数据集,许多经典的研究工作得以展开。例如,研究者们开发了多种基于深度学习的图像描述生成模型,这些模型在丹麦语环境下的表现得到了显著提升。此外,该数据集还催生了一系列关于跨语言图像描述生成的研究,推动了多模态学习领域的前沿发展。这些工作不仅丰富了学术界的理论体系,也为实际应用提供了强有力的技术支持。
数据集最近研究
最新研究方向
近年来,随着多模态学习技术的快速发展,丹麦WIT数据集在图像到文本生成、零样本图像分类以及特征提取等领域展现出广泛的应用潜力。该数据集作为维基百科图像文本(WIT)的丹麦语子集,为研究者提供了丰富的图像与文本对,特别适用于跨语言和多模态任务的研究。当前,研究热点集中在如何利用该数据集提升多模态模型的泛化能力,尤其是在低资源语言环境下的表现。此外,结合预训练模型(如CLIP、BLIP等)进行零样本学习,已成为该领域的前沿方向。丹麦WIT的发布不仅推动了北欧语言在人工智能领域的研究,也为跨文化、跨语言的多模态学习提供了重要数据支持。
以上内容由遇见数据集搜集并总结生成


