post-ocr-correction
收藏Hugging Face2024-11-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/jeanflop/post-ocr-correction
下载链接
链接失效反馈官方服务:
资源简介:
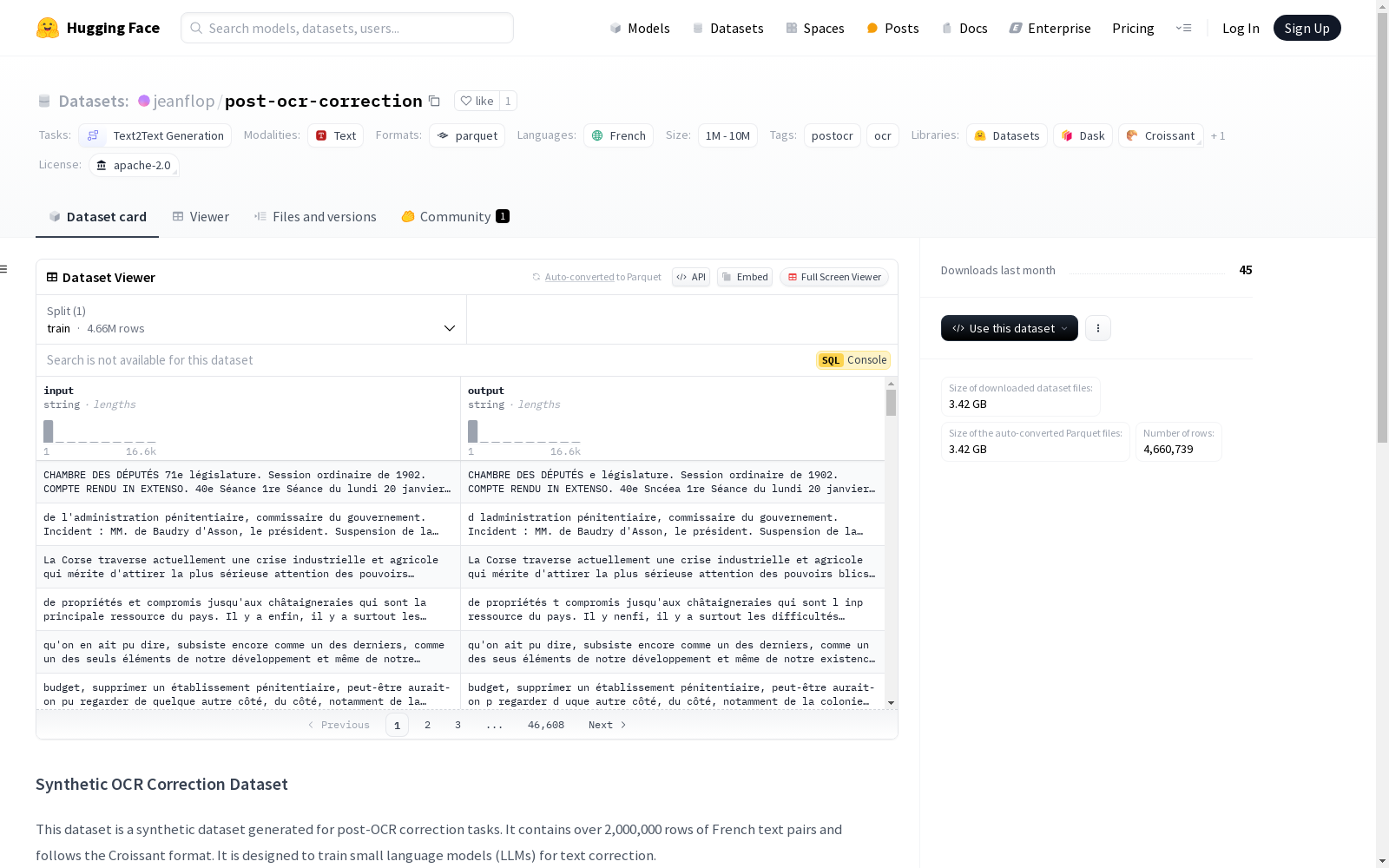
该数据集是一个用于OCR后校正任务的合成数据集,包含超过2,000,000行的法语文本对,并遵循Croissant格式。数据集旨在训练小型语言模型(LLMs)进行文本校正。为了确保数据集与OCR畸变文本相似,应用了多种随机变换,以避免LLM识别特定模式,并鼓励其根据上下文选择正确的单词。变换包括删除元音、替换多个空格、删除单个字母、删除标点符号、随机删除字符和随机打乱单词等。每个文本中的单词有50%的几率被选中进行变换,且随机应用一定数量的变换。在当前版本中,每段文本中10%到50%的单词可以被变换。
创建时间:
2024-10-28
原始信息汇总
Synthetic OCR Correction Dataset
概述
- 语言: 法语 (fr)
- 许可证: Apache 2.0
- 大小: 1M < n < 10M
- 任务类别: 文本到文本生成 (text2text-generation)
- 标签:
- postocr
- ocr
数据集信息
- 特征:
input: 字符串类型output: 字符串类型
- 分割:
train:- 字节数: 5716780692
- 样本数: 4660739
- 下载大小: 3419064772
- 数据集大小: 5716780692
配置
- 配置名称: default
- 数据文件:
train: data/train-*
- 数据文件:
描述
该数据集是一个用于OCR后校正任务的合成数据集,包含超过2,000,000行的法语文本对,遵循Croissant格式。设计用于训练小型语言模型(LLMs)进行文本校正。
数据生成
为确保数据集与OCR畸变文本相似,应用了多种随机变换。这些变换有助于避免LLM识别特定模式,并鼓励其根据上下文选择正确的单词。以下是一些应用的变换:
- 删除元音
- 用单个空格替换多个空格
- 删除单个字母
- 删除标点符号
- 随机删除字符
- 随机打乱单词
此外,还修改了标点符号、添加了单词并创建了重复。可以根据需要自定义这些变换。
生成规则
- 每个单词有50%的几率被选中进行变换。
- 对选中的单词应用随机数量的变换。
- 在此版本中,每段文本中10%到50%的单词可以被变换。
欢迎社区反馈以进一步改进此数据集。
搜集汇总
数据集介绍
构建方式
该数据集通过合成方法构建,专门用于OCR后文本校正任务。为了模拟OCR处理过程中常见的文本错误,研究者采用了多种随机变换策略,包括删除元音、替换多余空格、移除单字母、去除标点符号、随机丢弃字符以及随机打乱单词顺序等。这些变换旨在避免模型识别特定模式,从而鼓励其根据上下文选择正确的词汇。此外,数据集还引入了标点修改、添加词汇和重复文本等操作,进一步增强了数据的多样性和复杂性。
特点
该数据集包含超过200万行法语文本对,采用Croissant格式,专为训练小型语言模型进行文本校正而设计。其显著特点在于通过多种随机变换模拟OCR处理中的文本错误,确保数据集的多样性和真实性。每段文本中的单词有50%的概率被选中进行变换,且每个被选中的单词会应用随机数量的变换。这种设计使得模型能够在复杂的文本环境中学习并纠正错误,提升其在实际应用中的表现。
使用方法
该数据集主要用于训练和评估OCR后文本校正模型。用户可以通过加载数据集中的文本对,将输入文本作为模型的训练数据,输出文本作为目标校正结果。研究者可以根据需要自定义变换策略,以进一步优化模型的性能。此外,数据集支持社区反馈,用户可以通过分享建议或改进意见,共同推动数据集的完善和模型的进步。
背景与挑战
背景概述
在光学字符识别(OCR)技术日益普及的背景下,OCR后文本校正(Post-OCR Correction)成为提升文本识别准确性的关键环节。Post-OCR Correction数据集由法国研究团队于近年开发,旨在通过合成数据训练小型语言模型(LLMs),以校正OCR过程中产生的错误文本。该数据集包含超过200万条法语文本对,采用Croissant格式,通过随机应用多种文本变换,模拟OCR错误,从而增强模型在上下文中的纠错能力。该数据集的推出,为OCR后处理领域的研究提供了重要的数据支持,推动了相关技术的进一步发展。
当前挑战
Post-OCR Correction数据集在构建与应用过程中面临多重挑战。首先,OCR错误类型多样且复杂,如何通过合成数据准确模拟真实OCR错误,是数据集构建的核心难题。其次,文本变换的随机性与多样性需在保持语义连贯性的同时,避免模型过度依赖特定模式。此外,数据集规模庞大,如何在保证数据质量的前提下高效处理与存储,也是技术实现中的一大挑战。最后,如何通过社区反馈持续优化数据集,使其更贴近实际应用场景,仍需进一步探索与改进。
常用场景
经典使用场景
在光学字符识别(OCR)技术领域,post-ocr-correction数据集被广泛用于训练和评估文本校正模型。该数据集通过模拟OCR过程中常见的错误模式,如字符缺失、单词混淆和标点符号错误,为研究者提供了一个理想的实验平台。通过使用该数据集,研究人员能够开发出更加鲁棒的文本校正算法,从而提升OCR系统的整体性能。
实际应用
在实际应用中,post-ocr-correction数据集被广泛用于提升OCR系统的文本识别质量。例如,在数字化档案管理、法律文档处理和医疗记录转录等领域,OCR系统的准确性至关重要。通过使用该数据集训练的校正模型,能够显著减少识别错误,提高文档的可读性和可用性,从而提升工作效率和数据的可靠性。
衍生相关工作
基于post-ocr-correction数据集,研究者们开发了多种先进的文本校正模型和算法。例如,一些工作利用深度学习技术,结合上下文信息进行错误检测和纠正;另一些研究则专注于多语言OCR校正,扩展了数据集的应用范围。这些衍生工作不仅推动了OCR技术的发展,还为自然语言处理领域的文本校正研究提供了新的思路和方法。
以上内容由遇见数据集搜集并总结生成


