DFIR-Metric
收藏arXiv2025-05-26 更新2025-05-28 收录
下载链接:
https://github.com/DFIR-Metric
下载链接
链接失效反馈官方服务:
资源简介:
DFIR-Metric数据集是专为评估大型语言模型(LLM)在数字取证和事件响应(DFIR)领域的表现而设计的基准数据集。数据集包含三个部分:知识评估、现实取证挑战和实用分析。知识评估部分由700个专家评审的多项选择题组成,这些题目来源于行业标准认证和官方文档。现实取证挑战部分包含150个CTF风格的测试,用于检验多步推理和证据关联能力。实用分析部分则包含500个来自NIST计算机取证工具测试计划(CFTT)的磁盘和内存取证案例。DFIR-Metric数据集旨在提供一个严格、可重复的框架,以推动人工智能在数字取证领域的进步。
The DFIR-Metric dataset is a benchmark dataset specifically designed to evaluate the performance of Large Language Models (LLMs) in the field of digital forensics and incident response (DFIR). The dataset consists of three components: Knowledge Assessment, Real-World Forensic Challenges, and Practical Analysis. The Knowledge Assessment component comprises 700 expert-reviewed multiple-choice questions sourced from industry-standard certifications and official documentation. The Real-World Forensic Challenges section contains 150 Capture The Flag (CTF)-style tests intended to assess multi-step reasoning and evidence correlation capabilities. The Practical Analysis component includes 500 disk and memory forensics cases from the NIST Computer Forensic Tool Testing (CFTT) program. The DFIR-Metric dataset aims to provide a rigorous, reproducible framework to advance artificial intelligence research in the digital forensics domain.
提供机构:
阿布扎比技术革新研究所, 挪威奥斯陆大学, 匈牙利罗兰大学
创建时间:
2025-05-26
搜集汇总
数据集介绍
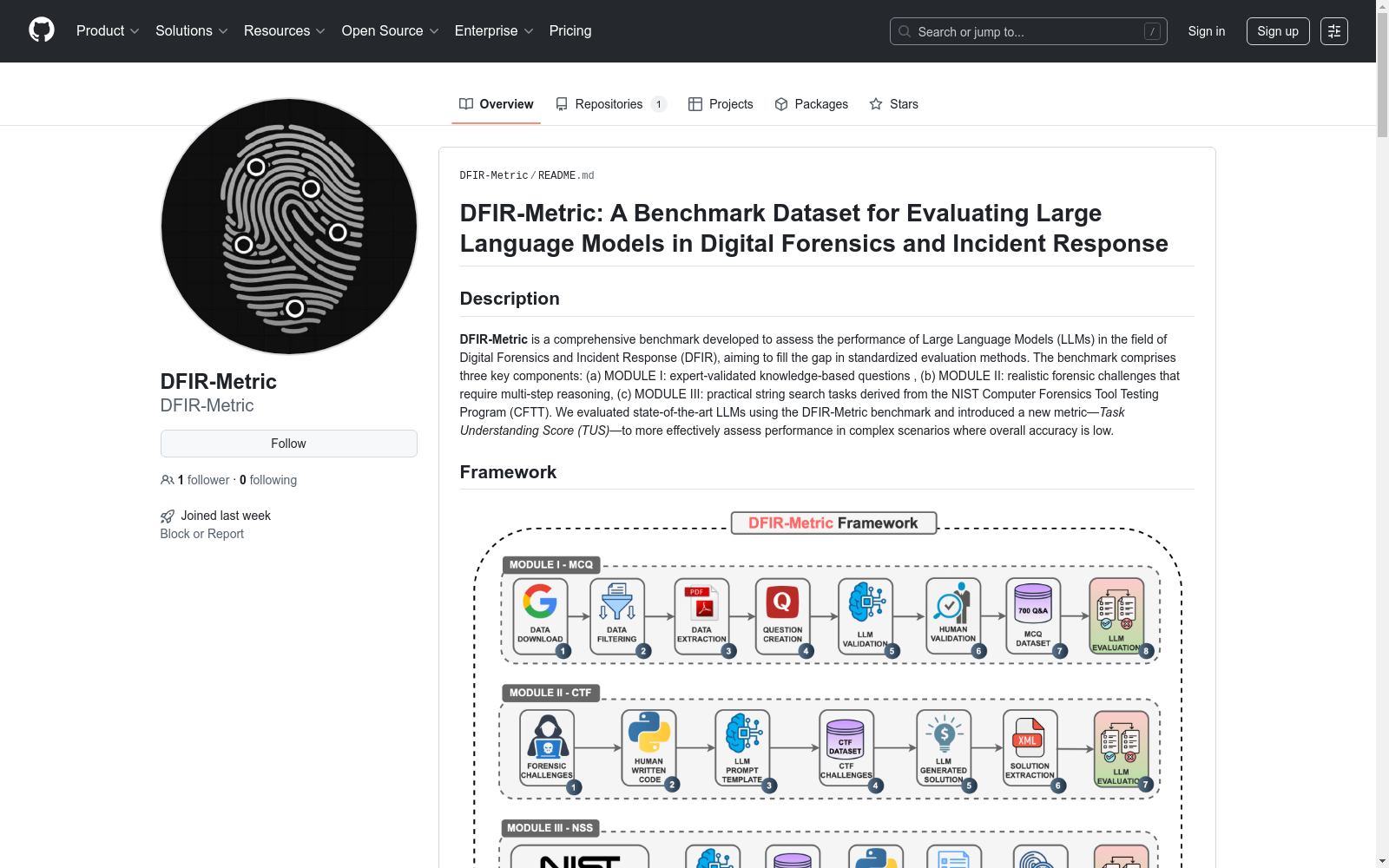
构建方式
DFIR-Metric数据集通过三个核心模块构建,旨在全面评估大型语言模型(LLM)在数字取证与事件响应(DFIR)领域的表现。模块I包含700道经过专家审核的多选题,内容源自行业标准认证和官方文档,确保问题覆盖DFIR的理论知识。模块II设计了150个CTF风格的实战挑战,模拟真实取证场景,要求模型进行多步推理和证据关联。模块III则基于NIST计算机取证工具测试程序(CFTT),提供了500个磁盘和内存取证案例,测试模型在字符串搜索等基础取证技能上的表现。每个模块均通过严格的验证流程,确保数据质量和任务多样性。
特点
DFIR-Metric数据集的特点在于其全面性和专业性。它不仅覆盖了DFIR的理论知识,还通过实战任务评估模型的实践能力。数据集的多选题经过专家审核,确保问题准确且具有挑战性;CTF挑战则通过动态生成的模板,模拟真实取证场景,测试模型的推理和问题解决能力;NIST取证任务则提供了标准化的测试环境,评估模型在基础取证技能上的表现。此外,数据集引入了任务理解评分(TUS),能够更细致地评估模型在复杂任务中的表现,尤其是在零准确率场景下的部分正确性。
使用方法
DFIR-Metric数据集的使用方法包括三个主要步骤:首先,通过模块I的多选题评估模型在DFIR理论知识上的掌握程度;其次,利用模块II的CTF挑战测试模型在实战场景中的推理和问题解决能力;最后,通过模块III的NIST取证任务评估模型在基础取证技能上的表现。每个模块均提供了详细的评估标准和自动化脚本,确保测试的可重复性和一致性。研究人员可以通过项目的GitHub页面获取所有脚本和数据集,方便进行模型评估和结果复现。数据集的设计还支持扩展,允许用户添加新的任务或模型,以适应不断发展的DFIR领域需求。
背景与挑战
背景概述
DFIR-Metric是由Technology Innovation Institute等机构的研究团队于2025年提出的首个面向数字取证与事件响应(DFIR)领域的大语言模型(LLM)评估基准数据集。该数据集填补了DFIR领域缺乏系统性评估工具的空白,包含三大模块:700道专家审核的多选题(源自行业认证标准)、150项CTF式实战挑战以及500个基于NIST CFTT程序的磁盘/内存取证案例。其创新性体现在首次将NIST 800-86标准中的取证流程(证据识别、收集、检查、分析)转化为可量化的评估框架,并引入了任务理解分数(TUS)这一新型评估指标,为AI在司法关键场景中的应用提供了可靠性衡量标准。
当前挑战
DFIR-Metric面临的挑战主要体现在两个维度:领域问题层面,数字取证要求模型具备处理多语言日志、关联碎片化证据链的能力,而现有LLMs在复杂推理(如反向工程)和输出稳定性(避免证据污染)方面表现欠佳;数据构建层面,需平衡司法严谨性与数据可得性——700道多选题需规避版权风险进行语义重构,150项CTF挑战需设计参数化模板确保可重复性,而NIST测试案例则需将二进制取证任务转化为自然语言提示。实验显示,最优模型GPT-4.1在字符串搜索任务中TUS仅38.5%,暴露出LLMs在生成可执行取证代码时存在路径幻觉和格式偏差等核心缺陷。
常用场景
经典使用场景
DFIR-Metric数据集在数字取证和事件响应(DFIR)领域中被广泛用于评估大型语言模型(LLM)的理论知识和实践能力。通过包含700道专家评审的多选题、150个CTF风格的实战任务以及500个NIST计算机取证工具测试程序(CFTT)案例,该数据集为研究者提供了一个全面且标准化的测试平台。经典使用场景包括模型在日志分析、内存取证和多步推理任务中的表现评估,帮助研究者识别模型在复杂取证环境中的优势和不足。
解决学术问题
DFIR-Metric解决了数字取证领域缺乏综合性基准数据集的学术研究问题。通过提供理论知识和实践任务相结合的评估框架,该数据集填补了LLM在DFIR任务中可靠性、一致性和准确性评估的空白。其引入的任务理解分数(TUS)进一步解决了传统评估指标在模型零准确率场景下无法有效区分性能的问题,为模型在部分正确任务中的表现提供了量化标准。
衍生相关工作
该数据集衍生了一系列数字取证与AI交叉领域的研究。例如,基于DFIR-Metric的评估方法被扩展至时间线分析工具(如Plaso)的自动化测试中;其CTF任务框架启发了AutoDFBench等专注于取证代码生成的基准测试。此外,任务理解分数(TUS)的提出推动了《Dynamic Intelligence Assessment》等研究对模型部分正确响应的量化分析,为AGI评估体系的发展提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


