ROCO, MIMIC-CXR, MIMIC-CXR-JPG, MIMIC-NLE, CXR-PRO, MS-CX
收藏github2024-03-19 更新2024-05-31 收录
下载链接:
https://github.com/lab-rasool/Awesome-Medical-VLMs-and-Datasets
下载链接
链接失效反馈官方服务:
资源简介:
ROCO: 医学图像-文本对数据集。MIMIC-CXR: 包含医学图像-文本对的大型数据集。MIMIC-CXR-JPG: MIMIC-CXR的JPG格式版本。MIMIC-NLE: 医学图像-文本对数据集。CXR-PRO: 包含未配对医学图像-文本对的数据集。MS-CX: 信息不完整,无法提供详细描述。
ROCO: A dataset of medical image-text pairs. MIMIC-CXR: A large dataset containing medical image-text pairs. MIMIC-CXR-JPG: The JPG format version of MIMIC-CXR. MIMIC-NLE: A dataset of medical image-text pairs. CXR-PRO: A dataset containing unpaired medical image-text pairs. MS-CX: Insufficient information available to provide a detailed description.
创建时间:
2024-03-18
原始信息汇总
数据集概述
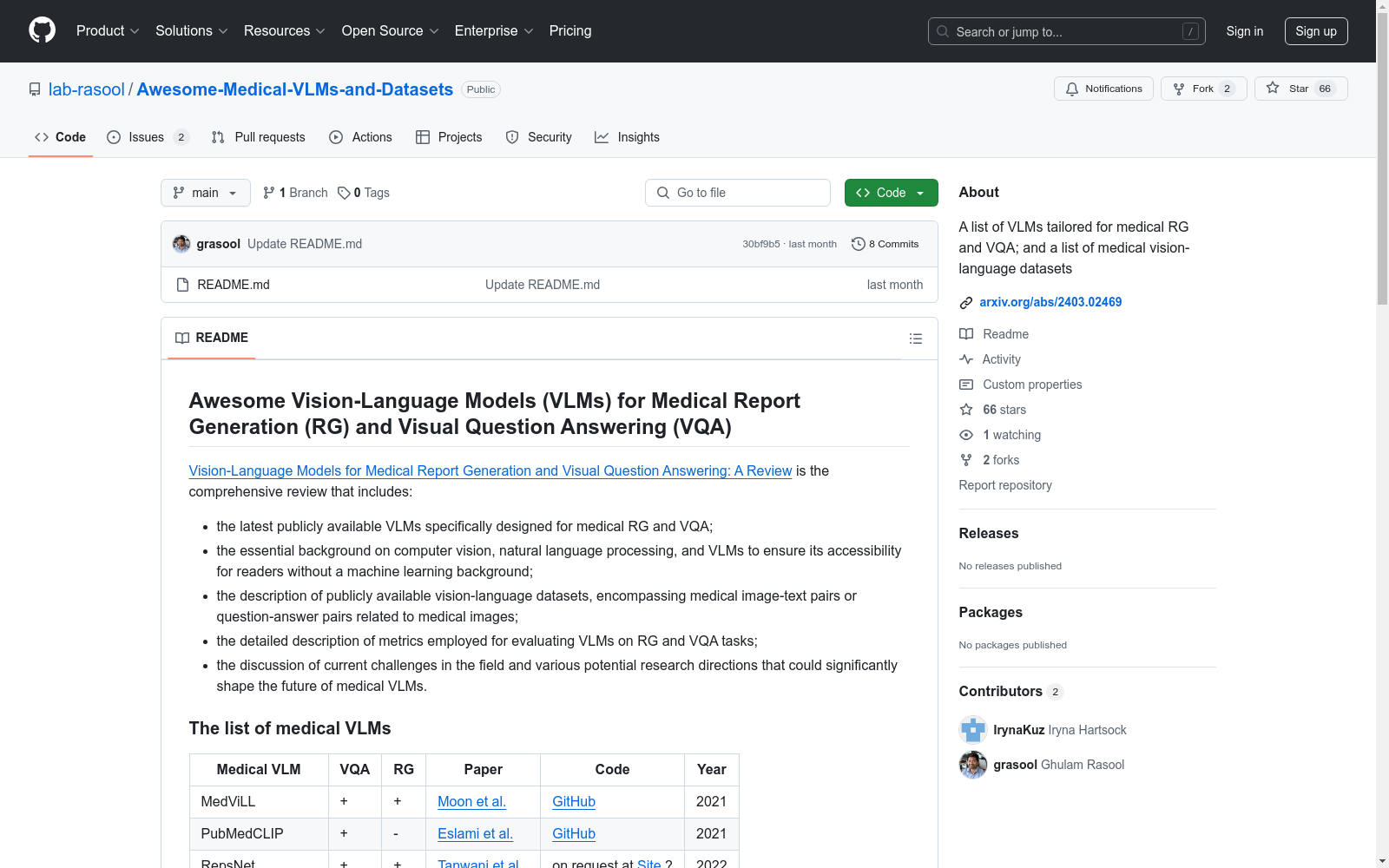
医疗视觉-语言模型(VLMs)列表
| Medical VLM | VQA | RG | Paper | Code | Year |
|---|---|---|---|---|---|
| MedViLL | + | + | Moon et al. | GitHub | 2021 |
| PubMedCLIP | + | - | Eslami et al. | GitHub | 2021 |
| RepsNet | + | + | Tanwani et al. | on request at Site ? | 2022 |
| BiomedCLIP | + | - | Zhang et al. | Hugging Face | 2023 |
| UniXGen | - | + | Lee et al. | GitHub | 2023 |
| RAMM | + | - | Yuan et al. | GitHub | 2023 |
| X-REM | - | + | Jeong et al. | GitHub | 2023 |
| Visual Med-Alpaca | + | - | - | GitHub | 2023 |
| CXR-RePaiR-Gen | - | + | Ranjit et al. | - | 2023 |
| LLaVa-Med | + | - | Li et al. | GitHub | 2023 |
| XrayGPT | + | + | Thawkar et al. | GitHub | 2023 |
| CAT-ViL DeiT | + | - | Bai et al. | GitHub | 2023 |
| MUMC | + | - | Li et al. | GitHub | 2023 |
| Med-Flamingo | + | - | Moor et al. | GitHub | 2023 |
| RaDialog | + | + | Pellegrini et al. | GitHub | 2023 |
医疗视觉-语言数据集列表
| Medical Dataset | Image-Text pairs | QA pairs | Paper | Link |
|---|---|---|---|---|
| ROCO | + | - | Pelka et al. | GitHub |
| MIMIC-CXR | + | - | Johnson et al. | PhysioNet |
| MIMIC-CXR-JPG | + | - | Johnson et al. | PhysioNet |
| MIMIC-NLE | + | - | Kayser et al. | GitHub |
| CXR-PRO | + (unpaired) | - | Ramesh et al. | PhysioNet |
| MS-CXR | + | - | Boecking et al. | PhysioNet |
| IU-Xray or Open-I | + | - | Demner-Fushman et al. | Openi |
| MedICaT | + | - | Subramanian et al. | GitHub |
| PMC-OA | + | - | Lin et al. | Hugging Face |
| SLAKE | - | + | Liu et al. | MedVQA |
| VQA-RAD | - | + | Lau et al. | Osf |
| PathVQA | - | + | He et al. | GitHub |
| VQA-Med 2019 | - | + | Abacha et al. | GitHub |
| VQA-Med 2020 | - | + | Abacha et al. | GitHub |
| VQA-Med 2021 | - | + | Ionescu et al. | GitHub |
| EndoVis 2017 | - | + | Allan et al. | GitHub |
| EndoVis 2018 | - | + | Allan et al. | image frames in Challenge and the rest on GitHub |
数据集引用
@misc{hartsock2024visionlanguage, title={Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review}, author={Iryna Hartsock and Ghulam Rasool}, year={2024}, eprint={2403.02469}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
构建方式
ROCO、MIMIC-CXR、MIMIC-CXR-JPG、MIMIC-NLE、CXR-PRO、MS-CXR等数据集的构建均基于医学影像与文本的关联性。这些数据集通过整合公开的医学影像资源,如X光片、CT扫描等,并结合相应的医学报告或描述文本,形成图像-文本对。部分数据集还通过专家标注或自动化工具生成问答对,以支持视觉问答任务。数据集的构建过程严格遵循医学数据隐私保护规范,确保数据的合法性与安全性。
特点
这些数据集在医学视觉-语言模型领域具有显著特点。首先,它们涵盖了多种医学影像类型,如胸部X光片、病理切片等,提供了丰富的视觉信息。其次,数据集中的文本内容多为专业医学报告或描述,语言精确且信息量大。此外,部分数据集还包含问答对,能够支持视觉问答任务。这些特点使得数据集在医学报告生成和视觉问答任务中具有广泛的应用价值。
使用方法
使用这些数据集时,研究人员可通过公开的链接或平台获取数据。数据通常以图像-文本对或问答对的形式提供,可直接用于训练和评估视觉-语言模型。在使用过程中,需注意遵守数据使用协议,确保数据的合法使用。此外,研究人员可根据具体任务需求,对数据进行预处理或增强,以提高模型的性能。数据集的多样性和专业性为医学视觉-语言模型的研究提供了坚实的基础。
背景与挑战
背景概述
ROCO、MIMIC-CXR、MIMIC-CXR-JPG、MIMIC-NLE、CXR-PRO、MS-CXR等数据集是医学视觉-语言模型(VLMs)领域的重要资源,旨在推动医学报告生成(RG)和视觉问答(VQA)的研究。这些数据集由多个研究团队和机构创建,涵盖了丰富的医学图像与文本对,为医学人工智能的发展提供了坚实的基础。例如,MIMIC-CXR由麻省理工学院和哈佛医学院的研究团队开发,首次发布于2019年,成为医学影像分析领域的标杆数据集。这些数据集的核心研究问题在于如何通过多模态学习,提升医学影像的自动化分析与解释能力,从而辅助临床决策。它们在医学人工智能领域的广泛应用,显著推动了医学影像分析、自然语言处理以及多模态学习的交叉研究。
当前挑战
这些数据集在构建和应用过程中面临多重挑战。首先,医学影像数据的获取与标注成本高昂,且需要专业医学知识,导致数据集的规模和质量受限。其次,医学影像的多样性和复杂性使得模型在泛化能力上面临严峻考验,尤其是在处理罕见病例或跨机构数据时。此外,医学文本的多样性和术语的复杂性也对自然语言处理模型提出了更高的要求。在构建过程中,数据隐私与伦理问题也是不可忽视的挑战,如何在保护患者隐私的前提下实现数据的开放共享,成为数据集开发中的关键问题。这些挑战不仅影响了数据集的构建效率,也对后续模型的性能和应用效果产生了深远影响。
常用场景
经典使用场景
在医学影像与自然语言处理交叉领域,ROCO、MIMIC-CXR等数据集被广泛应用于医学报告生成和视觉问答任务。这些数据集通过提供丰富的医学图像与文本对,支持研究者开发先进的视觉-语言模型,从而提升医学影像的自动分析与解释能力。
解决学术问题
这些数据集有效解决了医学影像分析中的关键问题,如自动生成诊断报告、辅助医生进行影像解读等。通过提供高质量的标注数据,研究者能够训练出更精准的模型,减少人工干预,提高诊断效率与准确性,推动医学人工智能的发展。
衍生相关工作
基于这些数据集,研究者提出了多种经典模型,如MedViLL、PubMedCLIP等,这些模型在医学报告生成和视觉问答任务中表现出色。这些工作不仅推动了医学人工智能的技术进步,还为后续研究提供了宝贵的参考与基础。
以上内容由遇见数据集搜集并总结生成


