href
收藏魔搭社区2025-12-05 更新2025-05-31 收录
下载链接:
https://modelscope.cn/datasets/allenai/href
下载链接
链接失效反馈官方服务:
资源简介:
# HREF: Human Reference-Guided Evaluation of Instruction Following in Language Models
<!-- Provide a quick summary of the dataset. -->
<div align="left">
📑 [Paper](https://arxiv.org/abs/2412.15524) | 🤗 [Leaderboard](https://huggingface.co/spaces/allenai/href) | 📁 [Codebase](https://github.com/allenai/href)
</div>
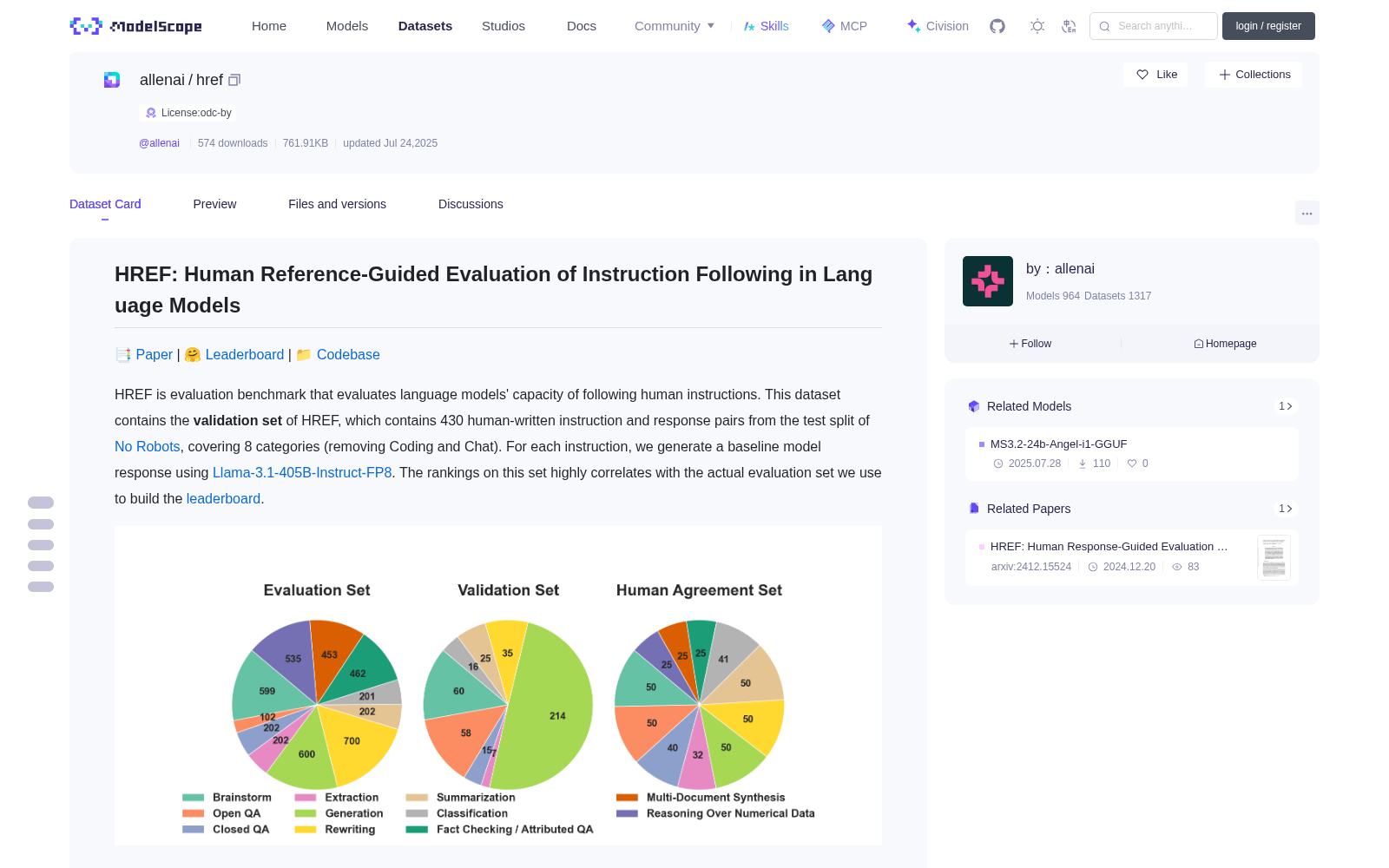
HREF is evaluation benchmark that evaluates language models' capacity of following human instructions. This dataset contains the **validation set** of HREF, which contains 430 human-written instruction and response pairs from the test split of [No Robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots), covering 8 categories (removing Coding and Chat).
For each instruction, we generate a baseline model response using [Llama-3.1-405B-Instruct-FP8](https://huggingface.co/meta-llama/Llama-3.1-405B-Instruct-FP8). The rankings on this set highly correlates with the actual evaluation set we use to build the [leaderboard]().

## Data Fields
- `category`: A category label of the instruction following the instruction-tuning terminology. Full list: Brainstorm, Open QA, Closed QA, Extract, Generation, Rewrite, Summarize, Classify.
- `instruction`: A text written by human experts to be used as an input to a language model.
- `output`: A response generated by Llama-3.1-405B-Instruct with the `instruction` as the input.
- `reference`: A response to the `instruction` written by the same human expert who writes the `instruction`.
## Why HREF
| Benchmark | Size | Evaluation Method | Baseline Model | Judge Model | Task Oriented | Contamination Resistant | Contains Human Reference|
|--------------------|-------|------------|----------------|----------------|----------|------------|-----------|
| MT-Bench | 80 | Score | --- | gpt4 | ✓ | ✗ | ✗ |
| AlpacaEval 2.0 | 805 | PWC | gpt4-turbo | gpt4-turbo | ✗ | ✗ | ✗ |
| Chatbot Arena | --- | PWC | --- | Human | ✗ | ✓ | ✗ |
| Arena-Hard | 500 | PWC | gpt4-0314 | gpt4-turbo | ✗ | ✗ | ✗ |
| WildBench | 1,024 | Score/PWC | gpt4-turbo | three models | ✗ | ✗ | ✗ |
| **HREF** | 4,258 | PWC | Llama-3.1-405B-Instruct | Llama-3.1-70B-Instruct | ✓ | ✓ | ✓ |
- **Human Reference**: HREF leverages human-written answer as reference to provide more reliable evaluation than previous method.
- **Large**: HREF has the largest evaluation size among similar benchmarks, making its evaluation more reliable.
- **Contamination-resistant**: HREF's evaluation set is hidden and uses public models for both the baseline model and judge model, which makes it completely free of contamination.
- **Task Oriented**: Instead of naturally collected instructions from the user, HREF contains instructions that are written specifically targetting 8 distinct categories that are used in instruction tuning, which allows it to provide more insights about how to improve language models.
## Usage
```python
from datasets import load_dataset
href_data = load_dataset("allenai/href_validation", split="dev")
```
## Citation
```
@article{lyu2024href,
title={HREF: Human Response-Guided Evaluation of Instruction Following in Language Models},
author={Xinxi Lyu and Yizhong Wang and Hannaneh Hajishirzi and Pradeep Dasigi},
journal={arXiv preprint arXiv:2412.15524},
year={2024}
}
```
# HREF: 人类参考引导的语言模型指令遵循评估(Human Reference-Guided Evaluation of Instruction Following in Language Models)
<!-- 请提供数据集的简要概述。 -->
<div align="left">
📑 [论文](https://arxiv.org/abs/2412.15524) | 🤗 [排行榜](https://huggingface.co/spaces/allenai/href) | 📁 [代码库](https://github.com/allenai/href)
</div>
HREF是一款用于评估语言模型遵循人类指令能力的基准测试集。本数据集为HREF的验证集,包含从[No Robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots)测试拆分中提取的430条人工编写的指令与响应对,涵盖8大类别(移除了编程与对话类别)。针对每条指令,我们使用[Llama-3.1-405B-Instruct-FP8](https://huggingface.co/meta-llama/Llama-3.1-405B-Instruct-FP8)生成基线模型响应。该验证集上的排名与我们用于构建排行榜的实际评估集高度相关。

## 数据字段
- `category`:遵循指令微调(Instruction Tuning)术语的指令类别标签,完整列表包括:头脑风暴(Brainstorm)、开放域问答(Open QA)、封闭域问答(Closed QA)、信息抽取(Extract)、文本生成(Generation)、文本改写(Rewrite)、文本摘要(Summarize)、文本分类(Classify)。
- `instruction`:由人类专家编写、用作语言模型输入的文本。
- `output`:以`instruction`为输入,由Llama-3.1-405B-Instruct生成的响应。
- `reference`:与编写`instruction`的为同一人类专家所撰写的对应指令响应。
## 为何选择HREF
| 基准测试名称 | 数据规模 | 评估方法 | 基线模型 | 评判模型 | 面向任务 | 抗污染性 | 包含人类参考响应|
|--------------------|-------|------------|----------------|----------------|----------|------------|-----------|
| MT-Bench | 80 | 评分(Score) | 无 | GPT-4 | ✔️ | ❌ | ❌ |
| AlpacaEval 2.0 | 805 | 成对比较(Pairwise Comparison,PWC) | GPT-4 Turbo | GPT-4 Turbo | ❌ | ❌ | ❌ |
| Chatbot Arena | 未标注 | 成对比较(Pairwise Comparison,PWC) | 无 | 人类评估者 | ✔️ | ✔️ | ❌ |
| Arena-Hard | 500 | 成对比较(Pairwise Comparison,PWC) | GPT-4-0314 | GPT-4 Turbo | ❌ | ❌ | ❌ |
| WildBench | 1024 | 评分/成对比较(Score/Pairwise Comparison,PWC) | GPT-4 Turbo | 三个模型 | ❌ | ❌ | ❌ |
| **HREF** | 4258 | 成对比较(Pairwise Comparison,PWC) | Llama-3.1-405B-Instruct | Llama-3.1-70B-Instruct | ✔️ | ✔️ | ✔️ |
- **人类参考响应**:HREF采用人工编写的答案作为参考依据,相比此前的评估方法能够提供更可靠的评估结果。
- **大规模数据集**:HREF在同类基准测试中拥有最大的评估规模,可保障评估结果的可靠性。
- **抗污染性**:HREF的评估集处于未公开状态,且基线模型与评判模型均采用公开模型,因此完全不受训练数据污染的影响。
- **面向任务设计**:HREF的指令并非来自用户自然收集的内容,而是专门针对指令微调(Instruction Tuning)中常用的8个类别编写的,能够为如何改进语言模型提供更具针对性的见解。
## 使用方法
python
from datasets import load_dataset
href_data = load_dataset("allenai/href_validation", split="dev")
## 引用
@article{lyu2024href,
title={HREF: 人类参考引导的语言模型指令遵循评估},
author={Xinxi Lyu and Yizhong Wang and Hannaneh Hajishirzi and Pradeep Dasigi},
journal={arXiv预印本 arXiv:2412.15524},
year={2024}
}
提供机构:
maas创建时间:
2025-05-28
搜集汇总
数据集介绍
背景与挑战
背景概述
HREF是一个评估语言模型遵循人类指令能力的基准数据集,包含430条人类编写的指令-响应对,覆盖了包括头脑风暴、问答、生成等8个任务类别。该数据集通过提供人类参考响应来提升评估的可靠性,并具有规模大、抗污染和任务导向的特点。
以上内容由遇见数据集搜集并总结生成


