edit_amazon_reviews_multi_en
收藏Hugging Face2025-08-21 更新2025-08-22 收录
下载链接:
https://huggingface.co/datasets/KRadim/edit_amazon_reviews_multi_en
下载链接
链接失效反馈官方服务:
资源简介:
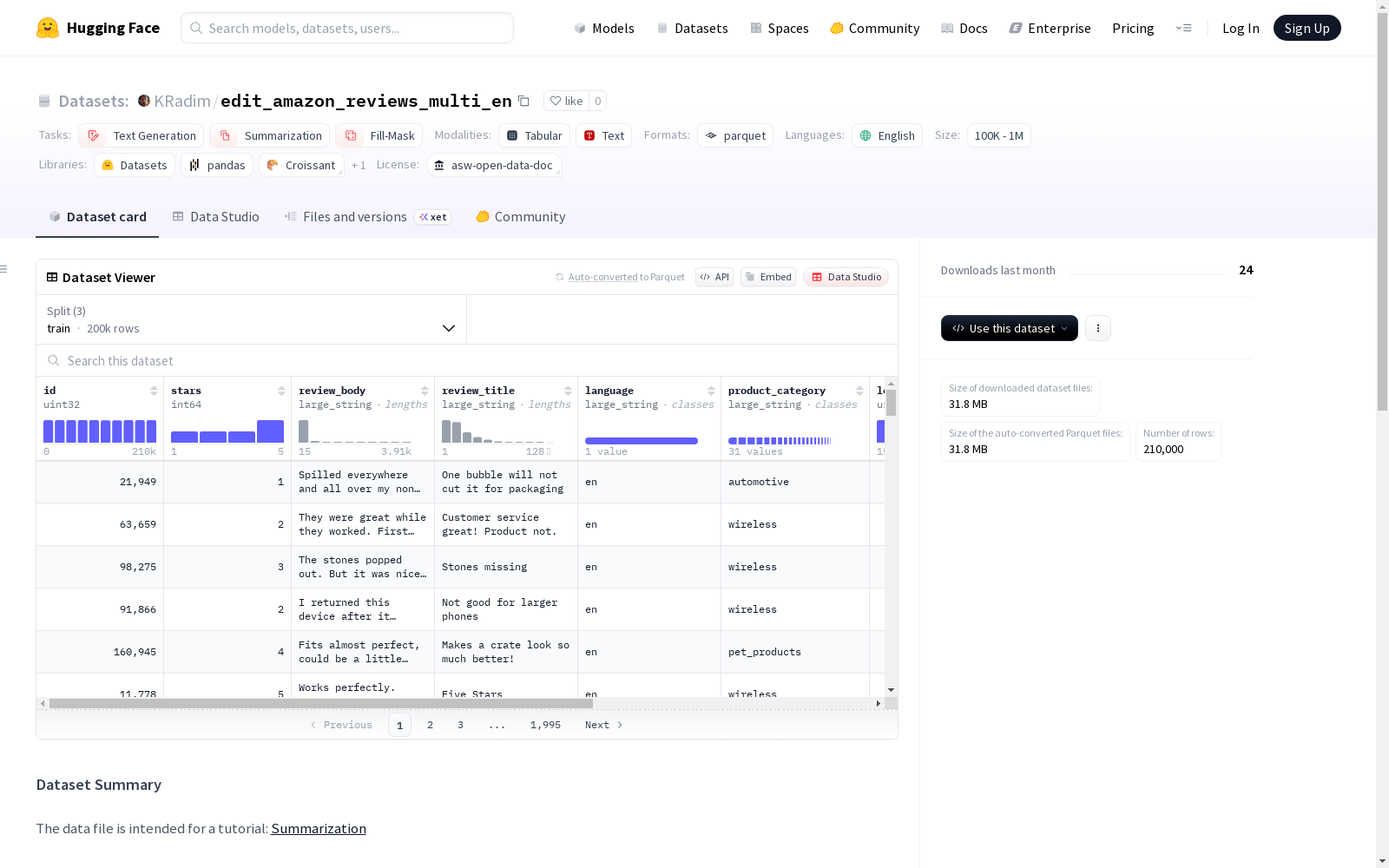
该数据集包含亚马逊多语言评论数据,适用于文本生成、摘要和填空等任务。数据集包含评论的ID、星级、评论正文、评论标题、语言、产品类别以及这些字段的长度信息。数据集分为训练集、验证集和测试集,分别占95%、2.5%和2.5%。数据集以英语为主,大小在10万到100万之间。
创建时间:
2025-08-21
搜集汇总
数据集介绍
构建方式
在电子商务自然语言处理研究领域,edit_amazon_reviews_multi_en数据集源自亚马逊多语言评论语料库的精选子集。该数据集通过系统化采样流程构建,首先从原始多语言评论中筛选英语文本,随后采用标准化数据清洗流程处理评论文本,保留核心元数据包括星级评分、产品类别和文本长度特征。数据处理过程通过Kaggle平台的开源笔记本工具实现,确保数据的一致性与可复现性,最终形成包含训练集、验证集和测试集的标准化分割方案。
特点
该数据集呈现出多维度特征体系,每条记录包含唯一标识符、1-5星级的量化评分、完整的评论文本和标题内容,以及产品分类信息和多尺度文本长度指标。其语言特征纯为英语,覆盖电子产品、家居用品等多元商品类别,文本长度字段为自然语言处理模型提供结构化特征输入。数据规模达20万条样本,采用95%-2.5%-2.5%的比例划分训练验证测试集,为文本生成和摘要任务提供充分的数据支撑。
使用方法
研究者可基于该数据集开展多任务自然语言处理实验,主要包括文本生成、自动摘要和掩码语言建模等研究方向。使用时应首先加载标准化的数据分割结构,利用review_body和review_title字段作为核心文本数据,结合stars字段进行情感分析或评分预测任务。产品类别字段可用于细粒度领域适应研究,而各类长度指标则为模型优化提供辅助特征。数据集与HuggingFace生态系统完全兼容,可通过标准数据加载接口快速集成到深度学习管道中。
背景与挑战
背景概述
亚马逊多语言评论编辑数据集诞生于自然语言处理领域对高质量文本生成与摘要任务的迫切需求,由AWS实验室团队主导构建并于近年发布。该数据集源自全球最大电商平台亚马逊的真实用户评论,核心研究聚焦于通过监督学习提升文本改写与摘要生成的精确度,对推荐系统优化和用户情感分析产生了深远影响,推动了对话式AI与个性化服务的技术演进。
当前挑战
该数据集致力于解决电商场景中多维度文本生成任务的复杂性挑战,包括评论文本的情感一致性保持、跨商品类别的语义适配性以及长短文本的结构化摘要生成。构建过程中需克服原始数据的噪声过滤问题,如非标准表达与多语言混杂,同时需确保不同星级评分的均衡分布与隐私信息的合规处理,这对数据清洗与标注策略提出了极高要求。
常用场景
经典使用场景
在自然语言处理领域,edit_amazon_reviews_multi_en数据集作为多用途文本语料库,广泛应用于文本生成与摘要任务。研究者通过该数据集训练模型学习从详细评论中提取关键信息,生成简洁的评论标题,有效模拟了真实场景中的文本压缩与重构过程。其多维度标注结构为模型提供了丰富的上下文信息,支持端到端的序列到序列学习框架。
衍生相关工作
基于该数据集衍生的经典工作包括PEGASUS等预训练摘要模型,这些模型通过在评论数据上进行领域自适应训练,显著提升了生成摘要的准确性和可读性。同时催生了多项基于注意力机制的序列生成研究,特别是在跨语言评论摘要领域取得了突破性进展。相关研究成果已成为文本生成领域的重要参考文献,推动了迁移学习在商业文本处理中的应用深度。
数据集最近研究
最新研究方向
在自然语言处理领域,亚马逊多语言评论数据集正推动情感分析与文本生成技术的深度融合。当前研究聚焦于利用大语言模型对评论进行语义重构与风格迁移,通过生成对抗网络实现评论文本的情感极性转换与质量增强。该数据集为跨语言评论生成任务提供了重要基准,尤其在电商场景下的多模态评论生成与个性化推荐系统优化方面展现出显著价值。随着可解释人工智能技术的发展,基于该数据集的细粒度情感归因分析正成为行业热点,为消费者行为研究与商业智能决策提供数据支撑。
以上内容由遇见数据集搜集并总结生成


