HQ-Edit
收藏arXiv2024-04-16 更新2024-06-21 收录
下载链接:
https://thefllood.github.io/HQEdit_web
下载链接
链接失效反馈官方服务:
资源简介:
HQ-Edit是一个高质量的基于指令的图像编辑数据集,由加州大学圣克鲁兹分校创建,包含约200,000个编辑指令。该数据集通过利用GPT-4V和DALL-E 3等先进基础模型,构建了一个可扩展的数据收集管道。数据集的创建过程包括从在线资源收集多样化的示例,扩展这些示例,并创建包含详细文本提示的输入和输出图像的高质量双联画,随后通过后处理确保精确对齐。此外,HQ-Edit还提出了两个评估指标,即对齐度和一致性,以量化评估图像编辑对的质量。HQ-Edit的高分辨率图像和丰富的编辑提示显著增强了现有图像编辑模型的能力,特别是在解决图像编辑中的精确指令遵循问题。
HQ-Edit is a high-quality instruction-based image editing dataset created by the University of California, Santa Cruz, containing approximately 200,000 editing instructions. This dataset establishes a scalable data collection pipeline by leveraging advanced foundation models including GPT-4V and DALL-E 3. The dataset construction process involves collecting diverse samples from online resources, expanding these samples, generating high-quality input-output image pairs paired with detailed text prompts, and conducting post-processing to ensure precise alignment. Furthermore, HQ-Edit proposes two evaluation metrics, alignment and consistency, for quantitatively evaluating the quality of image editing pairs. The high-resolution images and abundant editing prompts of HQ-Edit significantly enhance the performance of existing image editing models, especially in resolving the issue of accurate instruction adherence in image editing.
提供机构:
加州大学圣克鲁兹分校
创建时间:
2024-04-16
搜集汇总
数据集介绍
构建方式
在图像编辑领域,高质量数据集的匮乏长期制约着指令驱动编辑模型的发展。HQ-Edit的构建采用了一种可扩展的自动化流水线,首先从在线资源收集293个种子三元组,每个三元组包含输入/输出图像描述及编辑指令。随后利用GPT-4将种子集扩展至约10万条实例,确保编辑指令的广泛多样性。在生成阶段,通过GPT-4将三元组精炼为详细的联画提示,输入DALL-E 3以生成并排的输入与输出图像,这一设计显著提升了图像对的相关性与一致性。最后,后处理阶段通过YOLOv8分解联画、DIFT进行语义扭曲对齐,并利用GPT-4V重写编辑指令及生成逆编辑指令,最终得到约20万条高质量编辑样本。
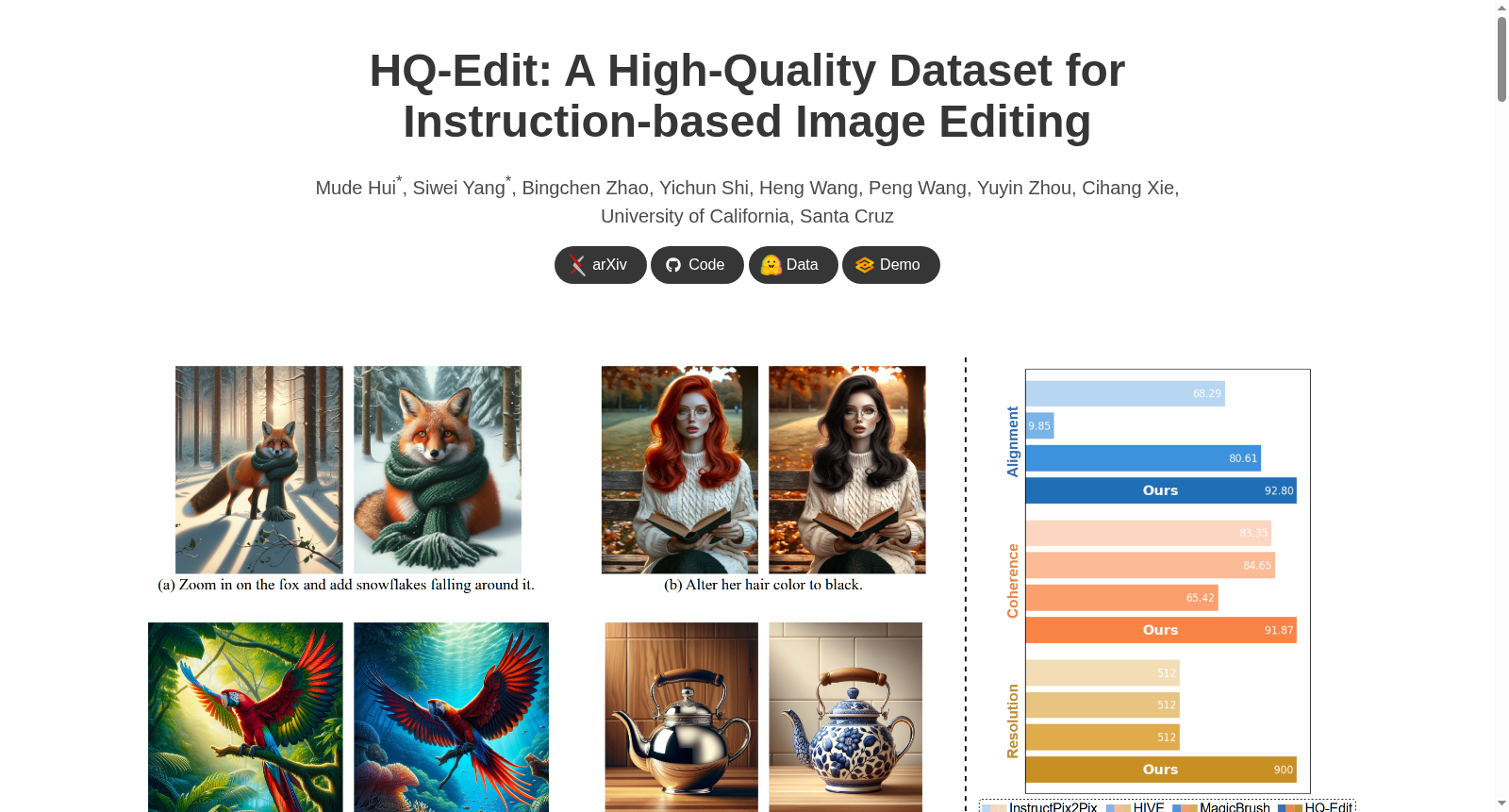
特点
HQ-Edit的核心优势在于其卓越的数据质量与丰富的多样性。图像分辨率高达约900×900像素,几乎为现有数据集的两倍,细节表现力突出。编辑指令涵盖全局操作如天气、背景与风格变换,以及局部操作如物体添加、移除与颜色调整,其长度分布更为均匀广阔,体现了更高的细节与灵活性。基于GPT-4V提出的对齐性与连贯性两项评估指标显示,HQ-Edit分别达到92.80与91.87分,远超InstructPix2Pix、HIVE与MagicBrush等现有数据集。此外,逆编辑指令的引入使数据量翻倍,进一步增强了模型的泛化能力。
使用方法
HQ-Edit可直接用于微调指令驱动的图像编辑模型,如InstructPix2Pix。使用时,将数据集中的输入图像与编辑指令作为训练对,设置图像分辨率为512,总训练步数15000,学习率5e-5,条件丢弃概率0.05。推理阶段可设定图像引导尺度1.5与指令引导尺度7.0,迭代20步生成编辑结果。研究者还可利用数据集中的逆编辑指令进行数据增强,或采用后处理中的扭曲与过滤步骤筛选高质量子集。实验表明,基于HQ-Edit微调的模型在对齐性与连贯性上分别提升12.30与5.56,超越了使用人工标注数据的同类方法。
背景与挑战
背景概述
在指令式图像编辑领域,高质量数据集的匮乏长期制约着模型性能的突破。为此,加州大学圣克鲁兹分校的Mude Hui、Siwei Yang等研究者于2024年提出了HQ-Edit数据集,该数据集包含约20万组高分辨率编辑样本,其核心创新在于构建了一条可扩展的自动化数据流水线,巧妙融合GPT-4V与DALL-E 3等前沿基础模型,通过“扩展-生成-后处理”三阶段策略,实现了从种子样本到海量高质图文对的高效产出。HQ-Edit的诞生不仅解决了传统数据集分辨率低、编辑指令与图像对齐不佳的痼疾,更通过引入Alignment与Coherence两项基于GPT-4V的量化评估指标,为图像编辑领域树立了新的数据质量标杆,其微调后的InstructPix2Pix模型性能甚至超越了基于人工标注数据训练的同类模型,展现出对领域发展的深远影响力。
当前挑战
HQ-Edit数据集所应对的核心挑战源于指令式图像编辑领域长期存在的两大困境:其一,现有数据集如InstructPix2Pix受限于GPT-3与Stable Diffusion 1.5等过时模型,生成的图像分辨率低且编辑对齐性差,而MagicBrush等人工标注数据集虽质量可控,却规模有限且偏重局部编辑,难以覆盖风格迁移等全局操作;其二,构建过程中面临的技术挑战尤为突出,包括如何利用仅提供API接口的DALL-E 3生成成对的输入输出图像、如何确保大规模合成数据中编辑指令与图像变更的精确匹配,以及如何通过后处理技术(如基于DIFT的语义对齐、GPT-4V驱动的指令重写与逆编辑生成)来弥补基础模型在图像生成一致性上的不足,最终实现数据质量与规模的双重突破。
常用场景
经典使用场景
在指令式图像编辑领域,HQ-Edit数据集最经典的使用场景是作为微调基础模型(如InstructPix2Pix)的训练数据,以提升模型对复杂编辑指令的理解与执行能力。该数据集包含约20万对高分辨率图像编辑样本,覆盖全局操作(如风格迁移、天气变换)与局部操作(如对象替换、颜色调整),为模型提供了丰富的编辑范例。研究者通常利用HQ-Edit对预训练模型进行监督微调,使其能够精准遵循自然语言指令完成图像修改,从而在保真度与对齐性上达到新高度。这一应用场景极大地降低了手工标注成本,推动了指令式编辑模型的规模化发展。
解决学术问题
HQ-Edit数据集主要解决了指令式图像编辑研究中训练数据稀缺且质量低下的核心学术问题。此前,数据集如InstructPix2Pix和MagicBrush受限于模型能力(如SD1.5、GPT-3),生成的图像分辨率低、编辑对齐性差,且多聚焦于局部变换。HQ-Edit通过引入GPT-4V和DALL·E 3,构建了自动化、可扩展的数据生成流水线,产出了高分辨率(约900×900像素)、高对齐性(Alignment得分92.80)的图像对,并提出了Alignment与Coherence两项量化评估指标。这一贡献不仅填补了高质量编辑数据集的空白,还验证了合成数据在超越人工标注数据方面的潜力,为后续研究提供了可靠的基准与评估范式。
衍生相关工作
HQ-Edit数据集衍生了一系列经典工作,推动了指令式图像编辑领域的纵深发展。其核心贡献在于证明了合成数据在质量与规模上可超越人工标注,启发了后续研究如利用更大规模基础模型(如GPT-4V、Midjourney)构建更具多样性的编辑数据集。此外,HQ-Edit提出的Alignment与Coherence评估指标被广泛采纳,成为衡量编辑模型性能的标准工具,例如后续的Emu Edit和MagicBrush-v2均参考了该评价体系。在模型层面,基于HQ-Edit微调的InstructPix2Pix变体成为基线模型,催生了针对特定编辑任务(如人脸编辑、3D场景编辑)的改进方法,进一步拓展了指令式编辑的应用边界。
以上内容由遇见数据集搜集并总结生成


