GenVidBench
收藏arXiv2025-01-20 更新2025-01-23 收录
下载链接:
https://genvidbench.github.io
下载链接
链接失效反馈官方服务:
资源简介:
GenVidBench是由华为诺亚方舟实验室创建的一个大规模、高质量的AI生成视频检测数据集。该数据集包含143,131条视频,涵盖8种最先进的AI视频生成器生成的视频,并提供了丰富的语义标签,如对象类别、动作和位置。数据集通过跨源和跨生成器的设计,确保了训练集和测试集之间的多样性,避免了内容过于相似的问题。GenVidBench旨在解决AI生成视频检测中的挑战,帮助研究人员开发和评估更有效的检测模型,应用于防止虚假信息的传播和网络安全威胁的应对。
GenVidBench is a large-scale, high-quality AI-generated video detection dataset developed by Huawei Noah's Ark Lab. This dataset contains 143,131 video clips, covering content generated by 8 state-of-the-art AI video generators, and is annotated with rich semantic tags including object categories, actions, and spatial locations. Adopting a cross-source and cross-generator design, the dataset ensures diversity between the training and test sets, thus avoiding the problem of overly similar content. GenVidBench is intended to address the challenges in AI-generated video detection, enabling researchers to develop and evaluate more effective detection models, which can be applied to curbing the spread of disinformation and addressing cybersecurity threats.
提供机构:
华为诺亚方舟实验室
创建时间:
2025-01-20
搜集汇总
数据集介绍
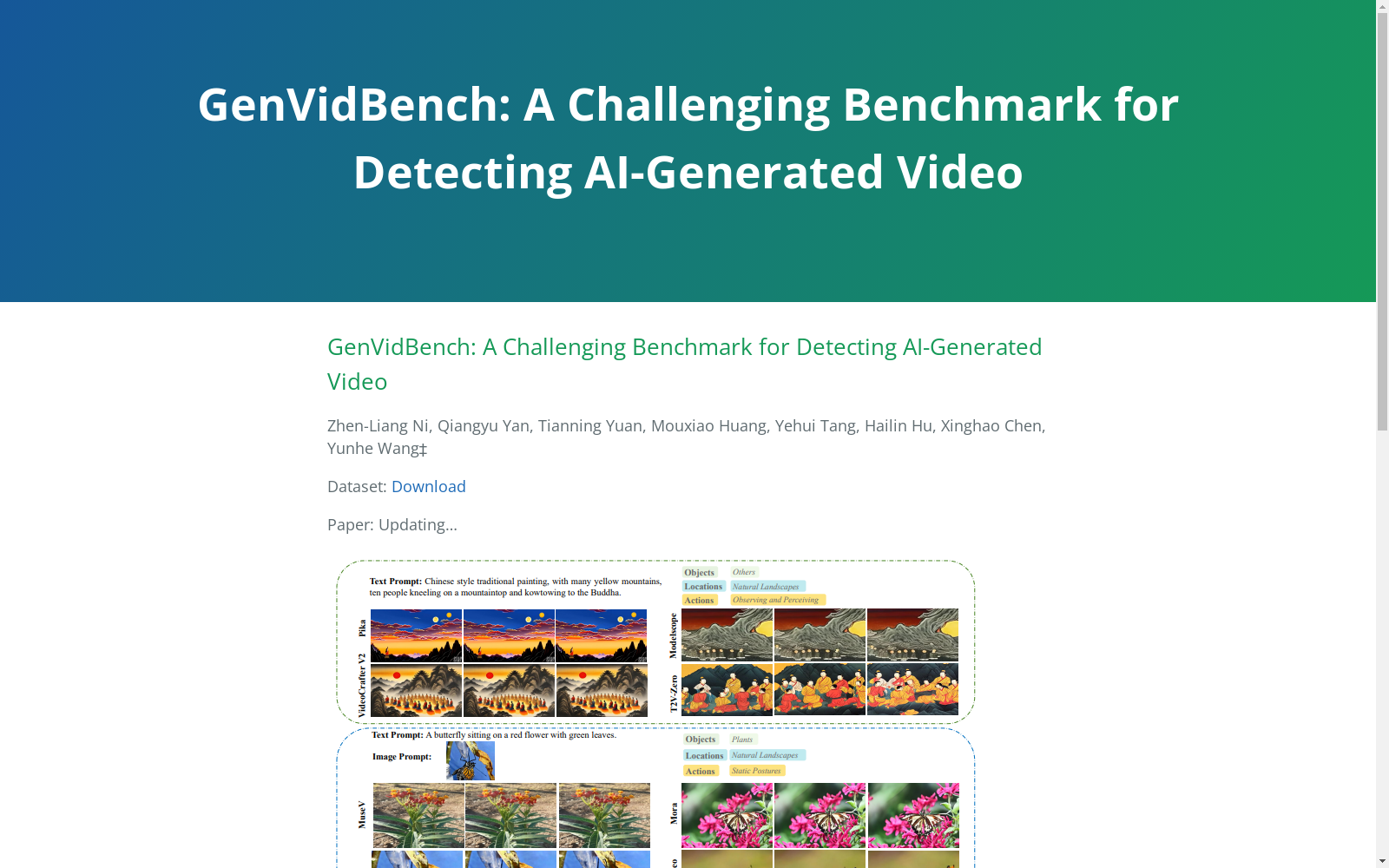
构建方式
GenVidBench数据集的构建基于跨源和跨生成器的设计理念,旨在为AI生成视频检测提供更具挑战性的基准。数据集包含来自8种最先进的AI视频生成器的生成视频,以及来自Vript和HD-VG130M两个真实视频源的真实视频。为了确保数据集的多样性和挑战性,生成视频通过相同的文本提示或图像生成,并分为两个视频对。训练集和测试集的生成器不同,以避免生成器属性过于相似。此外,数据集还提供了丰富的语义标签,涵盖对象、动作和场景等多个维度,确保数据集的广泛适用性和研究价值。
特点
GenVidBench数据集的特点在于其跨源和跨生成器的设计,确保了生成视频的多样性和检测任务的挑战性。数据集包含14.3万个视频样本,涵盖8种生成器和2种真实视频源,提供了丰富的语义标签,如对象类别、动作和场景等。这些标签不仅有助于视频内容的分类,还为检测模型提供了更全面的训练和评估环境。此外,数据集中的生成视频质量高,涵盖了最新的视频生成技术,能够有效模拟真实视频的复杂性,为AI生成视频检测研究提供了坚实的基础。
使用方法
GenVidBench数据集的使用方法主要包括跨源和跨生成器的检测任务。研究人员可以利用数据集中的训练集和测试集,分别训练和评估AI生成视频检测模型。训练集包含来自不同生成器的视频,而测试集则包含与真实视频相同生成源的视频,增加了检测任务的难度。此外,数据集提供的语义标签可以帮助研究人员针对特定场景或对象类别进行定制化研究。通过使用GenVidBench,研究人员能够开发更具泛化能力的检测模型,并评估其在复杂场景下的性能。
背景与挑战
背景概述
随着视频生成模型的快速发展,区分AI生成的视频与真实视频变得越来越具有挑战性。这一问题凸显了开发高效的AI生成视频检测器的迫切需求,以防止通过此类视频传播虚假信息。然而,当前缺乏专门为生成视频检测设计的大规模高质量数据集,阻碍了高性能生成视频检测器的发展。为此,华为诺亚方舟实验室的研究团队于2025年推出了GenVidBench数据集。该数据集具有跨源和跨生成器的特点,涵盖了8种最先进的AI视频生成器生成的视频,并提供了丰富的语义分类标签。GenVidBench的推出为开发更通用和有效的检测模型提供了坚实的基础,推动了AI生成视频检测领域的研究进展。
当前挑战
GenVidBench数据集在解决AI生成视频检测问题时面临多重挑战。首先,跨源和跨生成器的设置使得训练集和测试集之间的视频属性差异较大,增加了检测模型的泛化难度。其次,数据集构建过程中,确保生成视频的多样性和高质量是一个关键挑战,尤其是在使用不同生成器和源的情况下。此外,语义标签的丰富性虽然有助于提升模型的检测能力,但也增加了数据标注的复杂性和成本。最后,如何在实际应用中应对未知生成器的挑战,进一步提升检测器的鲁棒性和适应性,仍然是该领域亟待解决的问题。
常用场景
经典使用场景
GenVidBench数据集在AI生成视频检测领域具有广泛的应用,尤其是在跨源和跨生成器的视频检测任务中表现出色。该数据集通过提供来自8种最先进的AI视频生成器的视频样本,确保了生成视频的多样性和高质量。研究人员可以利用GenVidBench开发和评估AI生成视频检测模型,特别是在面对不同生成器和生成源时,测试模型的泛化能力和鲁棒性。
衍生相关工作
GenVidBench的推出催生了一系列相关研究工作,特别是在AI生成视频检测模型的开发方面。基于该数据集,研究人员提出了多种先进的检测算法,如基于时空卷积神经网络的AIGDet和基于视频帧一致性的DeCoF模型。此外,GenVidBench还为视频分类模型如VideoSwin和UniformerV2提供了新的基准测试平台,推动了该领域的技术进步。
数据集最近研究
最新研究方向
随着生成式视频模型的快速发展,AI生成的视频与真实视频之间的界限日益模糊,这为虚假信息的传播带来了新的挑战。GenVidBench作为首个大规模、高质量的AI生成视频检测数据集,通过跨源和跨生成器的设计,显著提升了检测模型的泛化能力。该数据集涵盖了8种先进视频生成器生成的视频,并通过丰富的语义标签对视频内容进行多维度分类,确保了数据集的多样性和挑战性。当前的研究方向主要集中在如何利用GenVidBench开发更高效的跨源和跨生成器检测模型,以应对未知生成器的威胁。此外,针对特定场景(如植物、交通工具等)的生成视频检测也成为研究热点,旨在通过语义标签分析提升检测模型在复杂场景下的表现。GenVidBench的推出为AI生成视频检测领域提供了重要的基准,推动了该领域的技术进步。
相关研究论文
- 1GenVidBench: A Challenging Benchmark for Detecting AI-Generated Video华为诺亚方舟实验室 · 2025年
以上内容由遇见数据集搜集并总结生成


