SpaceJudgeDataset
收藏Hugging Face2024-10-28 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/salma-remyx/SpaceJudgeDataset
下载链接
链接失效反馈官方服务:
资源简介:
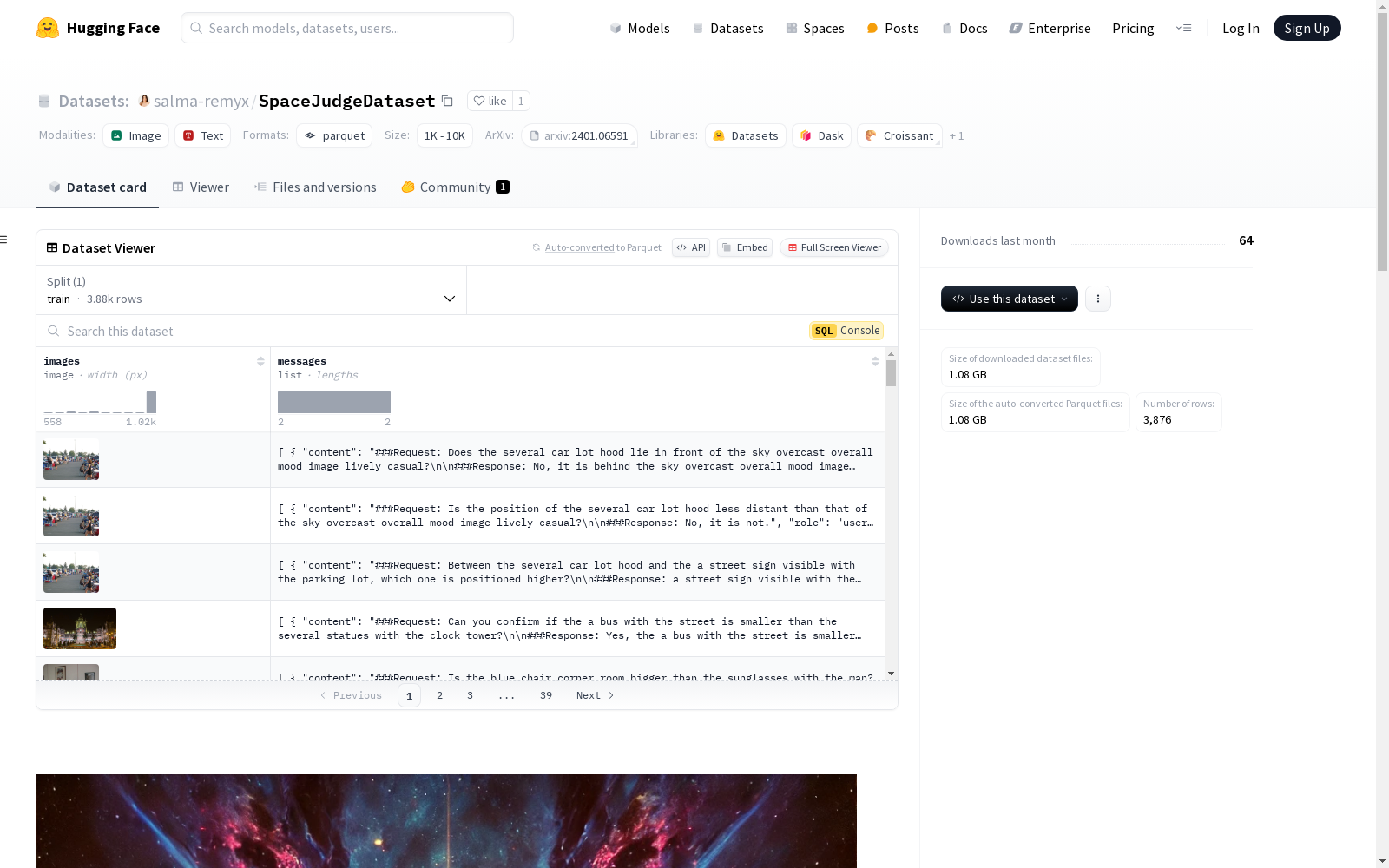
SpaceJudge数据集用于评估空间视觉问答(VQA)查询的响应质量。该数据集包含图像和消息,消息包含内容和角色信息。数据集分为训练集,包含3876个样本。该数据集旨在通过引入新的<JUDGE>任务,评估视觉语言模型(如SpaceLLaVA)的性能,并帮助将较大的模型(如13B VLM)提炼成较小的模型(如Florence-2)。数据集基于从OpenSpaces数据集中抽取的1K张图像。
创建时间:
2024-10-28
原始信息汇总
SpaceJudge Dataset
数据集概述
- 数据集名称: SpaceJudge Dataset
- 数据集用途: 用于评估空间视觉问答(VQA)查询响应的质量,评分范围为1-5的Likert量表。
数据集结构
- 特征:
- images: 图像数据,数据类型为
image。 - messages: 包含以下子特征的列表:
- content: 内容,数据类型为
string。 - role: 角色,数据类型为
string。
- content: 内容,数据类型为
- images: 图像数据,数据类型为
数据集配置
- 配置名称: default
- 数据文件:
- split: train
- path: data/train-*
数据集大小
- 下载大小: 1083523161 bytes
- 数据集大小: 3652054563.712 bytes
- 训练集:
- 样本数量: 3876
- 字节数: 3652054563.712 bytes
数据来源
- 图像来源: 从OpenSpaces数据集中抽取的1000张图像。
引用
@misc{lee2024prometheusvision, title={Prometheus-Vision: Vision-Language Model as a Judge for Fine-Grained Evaluation}, author={Seongyun Lee and Seungone Kim and Sue Hyun Park and Geewook Kim and Minjoon Seo}, year={2024}, eprint={2401.06591}, archivePrefix={arXiv}, primaryClass={cs.CL} }
搜集汇总
数据集介绍
构建方式
SpaceJudge数据集的构建依托于prometheus-vision框架,通过对SpaceLLaVA模型进行视觉问答(VQA)任务的评估,生成1-5分的Likert量表评分。该数据集从OpenSpaces数据集中抽取了1000张图像,旨在通过引入新的<JUDGE>任务,将13B规模的视觉语言模型(VLM)评估能力蒸馏至更小规模的模型,如Florence-2。
特点
SpaceJudge数据集的核心特点在于其专注于空间视觉问答任务的评估,提供了图像与文本对话的配对数据。数据集包含3876个训练样本,每个样本由图像和对话内容组成,对话内容进一步细分为角色和文本信息。这种结构为研究视觉语言模型的评估能力提供了丰富的实验素材,尤其适用于模型蒸馏和细粒度评估任务。
使用方法
使用SpaceJudge数据集时,研究人员可通过加载训练集数据,结合图像和对话内容,进行视觉语言模型的评估与优化。数据集支持直接应用于模型蒸馏任务,帮助开发更高效的视觉语言模型。此外,研究人员可通过引入<JUDGE>任务,进一步探索模型在空间视觉问答中的表现,推动视觉语言模型在细粒度评估领域的发展。
背景与挑战
背景概述
SpaceJudge数据集由Seongyun Lee等研究人员于2024年创建,旨在通过视觉语言模型(VLM)对空间视觉问答(VQA)的响应质量进行细粒度评估。该数据集基于Prometheus-Vision框架,利用SpaceLLaVA模型对从OpenSpaces数据集中采样的1K图像进行评分,评分标准采用1-5的李克特量表。通过引入新的<JUDGE>任务,SpaceJudge数据集的目标是将13B的VLM评估能力蒸馏到更小的模型如Florence-2中,从而推动视觉语言模型在空间理解任务中的应用与发展。
当前挑战
SpaceJudge数据集在解决空间视觉问答评估问题时面临多重挑战。首先,如何确保评估标准的客观性和一致性是一个关键问题,尤其是在处理复杂的空间关系时。其次,构建过程中需要处理大量高分辨率图像和文本数据,这对计算资源和数据处理能力提出了较高要求。此外,如何将大模型的评估能力有效蒸馏到小模型中,同时保持评估的准确性和可靠性,也是一个技术难点。这些挑战不仅影响了数据集的构建效率,也对后续模型的训练和评估提出了更高的要求。
常用场景
经典使用场景
SpaceJudgeDataset在视觉问答(VQA)领域中被广泛应用于评估模型对空间相关问题的响应质量。通过使用Prometheus-Vision框架,该数据集能够对SpaceLLaVA模型生成的回答进行细粒度评分,评分范围设定为1-5的Likert量表。这种评估方法不仅适用于大规模视觉语言模型,还可用于蒸馏至更小的模型如Florence-2,从而提升模型在空间理解任务中的表现。
实际应用
在实际应用中,SpaceJudgeDataset被用于提升智能助手、自动驾驶系统等需要空间理解能力的AI系统的性能。通过评估模型对空间相关问题的响应质量,开发者能够识别并改进模型在复杂场景中的表现,从而提高系统的整体准确性和用户体验。
衍生相关工作
SpaceJudgeDataset的推出催生了一系列相关研究,特别是在视觉语言模型的评估和蒸馏领域。基于该数据集,研究者开发了新的任务如`<JUDGE>`,并探索了如何将大规模模型的性能迁移至更小的模型。这些工作不仅扩展了视觉语言模型的应用范围,还为模型优化提供了新的思路。
以上内容由遇见数据集搜集并总结生成


