latam-gpt/Trueque-Benchmark-beta-0.1
收藏Hugging Face2026-04-01 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/latam-gpt/Trueque-Benchmark-beta-0.1
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- es
- pt
pretty_name: TRUEQUE
size_categories:
- n<1K
task_categories:
- question-answering
- text-generation
tags:
- latin-america
- evaluation
- benchmark
- llm
- multilingual
- beta
license: apache-2.0
configs:
- config_name: default
data_files:
- split: train
path: data/trueque_benchmark_beta_0_1.csv
---
# 🤝 Trueque: A human-reviewed collaborative benchmark for Latin American knowledge and culture
🌐 Language versions: [Español](<README_es.md>) | [Português](<README_pt.md>)
⚠️ Official Disclaimer: Beta Release (v0.1)
Welcome to Trueque for Factual Knowledge and Cultural Appropriateness. This dataset represents an initial effort to evaluate the regional knowledge and cultural accuracy of Large Language Models (LLMs) in Latin America.
Please take the following considerations into account before using this resource:
**Beta Release (v0.1):** This version contains 500 curated questions. Its primary goal is to validate our methodology for **human question collection and curation**, reference answer generation (ground truth), and automated evaluation pipelines. The complete version is expected to include over 3,000 questions distributed across 20 countries and multiple topics.
**Human Validation in Progress:** We are currently conducting a human review phase to refine the evaluation setup, particularly in identifying answers that may be linguistically plausible but factually incorrect or culturally inappropriate in the Latin American context.
**Evaluation Methodology (LLM-as-a-Judge):** Model responses are evaluated using an LLM-as-a-judge framework, prioritizing strict factual accuracy and alignment with reference answers. To mitigate bias and ensure reliable reporting, evaluation metrics are being adjusted following the guidelines from *"How to Correctly Report LLM-as-a-Judge Evaluations"* (Lee et al., 2025).
**Current Baseline Model:** Qwen2.5-Instruct (72B) is currently used for automated evaluation experiments.
We invite the research and developer community to explore this beta version, test their models, and provide feedback as we continue improving the benchmark.
## 🚀 Upcoming Release and current state
A future release is planned to include:
- The complete benchmark version (3,000+ questions)
- Full methodological documentation
- Evaluation protocol details and reporting guidelines
- Baseline results and analysis
Current work in progress:
- Collecting and curating additional questions
- Validating reference answers with human reviewers
- Adjusting the evaluation setup following the LLM-as-a-Judge reporting paper
- Running evaluation rounds and consolidating results
- Preparing and publishing the paper after the evaluation phase
---
## Description
**Trueque** is an evaluation benchmark designed to measure the performance of language models on questions related to **Latin America**, with emphasis on factual knowledge, cultural context, and region-specific understanding.
The benchmark is built from **human-contributed questions**, collected through a survey and **manually curated** to ensure relevance, clarity, and evaluability.
This version corresponds to an initial beta release and remains under active development.
---
## Distribution by Country and Topics
<img src="assets/countrys.png" alt="Countrys" width="60%"/>
<img src="assets/topics.png" alt="Topics" width="60%"/>
---
## How It Was Built
The benchmark was constructed through a multi-stage process combining **human curation**, **evidence-based reference answers**, and **automated evaluation**.
### 1. Question Collection and Curation
Questions were **contributed by human participants** through a survey form and later **manually curated** to reflect relevant knowledge in the Latin American context.
Questions were selected based on:
- Having a factual answer
- Being sufficiently specific for evaluation
- Being relevant to Latin America (country or regional level)
- Being supportable by external sources
Subjective, ambiguous, or opinion-based questions were excluded.
This process was supported by collaborations with over 100 institutions.
<img src="assets/institutions.png" alt="Institutions collaborating in Trueque" width="100%" />
### 🤝 Contribute Questions to the Benchmark
Help us expand country and topic coverage from the following **20 Latin American countries**.
The contribution form is available **in Spanish** and welcomes submissions from:
Argentina • Brazil • Bolivia • Chile • Colombia • Costa Rica • Cuba • Dominican Republic • Ecuador • El Salvador • Guatemala • Honduras • Mexico • Nicaragua • Panama • Paraguay • Peru • Puerto Rico • Uruguay • Venezuela
All submissions are reviewed and curated before inclusion.
👉 **[Submit your contribution here](https://docs.google.com/forms/d/e/1FAIpQLSfAXbBqt9GXvFC1gYKf9ugqqQs3X2p_eywEW4kdomT6w9mDZQ/viewform?usp=dialog)**
---
### 2. Reference Answer Creation (Ground Truth)
For each question, a **reference answer (ground truth)** was constructed using an evidence-based pipeline:
- Transforming the question into a search query
- Retrieving relevant web sources
- Identifying key information from those sources
- Writing a concise answer grounded in evidence
In addition to external sources, the human answer provided by the contributor who submitted the question was incorporated as an additional reference during ground-truth construction.
---
### 3. Evaluation Design
While the benchmark content (questions and curation) is **human-generated**, the evaluation of model outputs is primarily conducted using an **LLM-as-a-judge framework**.
Model responses can be evaluated according to:
- Factual accuracy
- Level of detail
- Alignment with the reference answer
- Appropriate handling of uncertainty when evidence is insufficient
Depending on the setup, evaluation can be complemented with human review, particularly for validating edge cases or improving the evaluation framework.
---
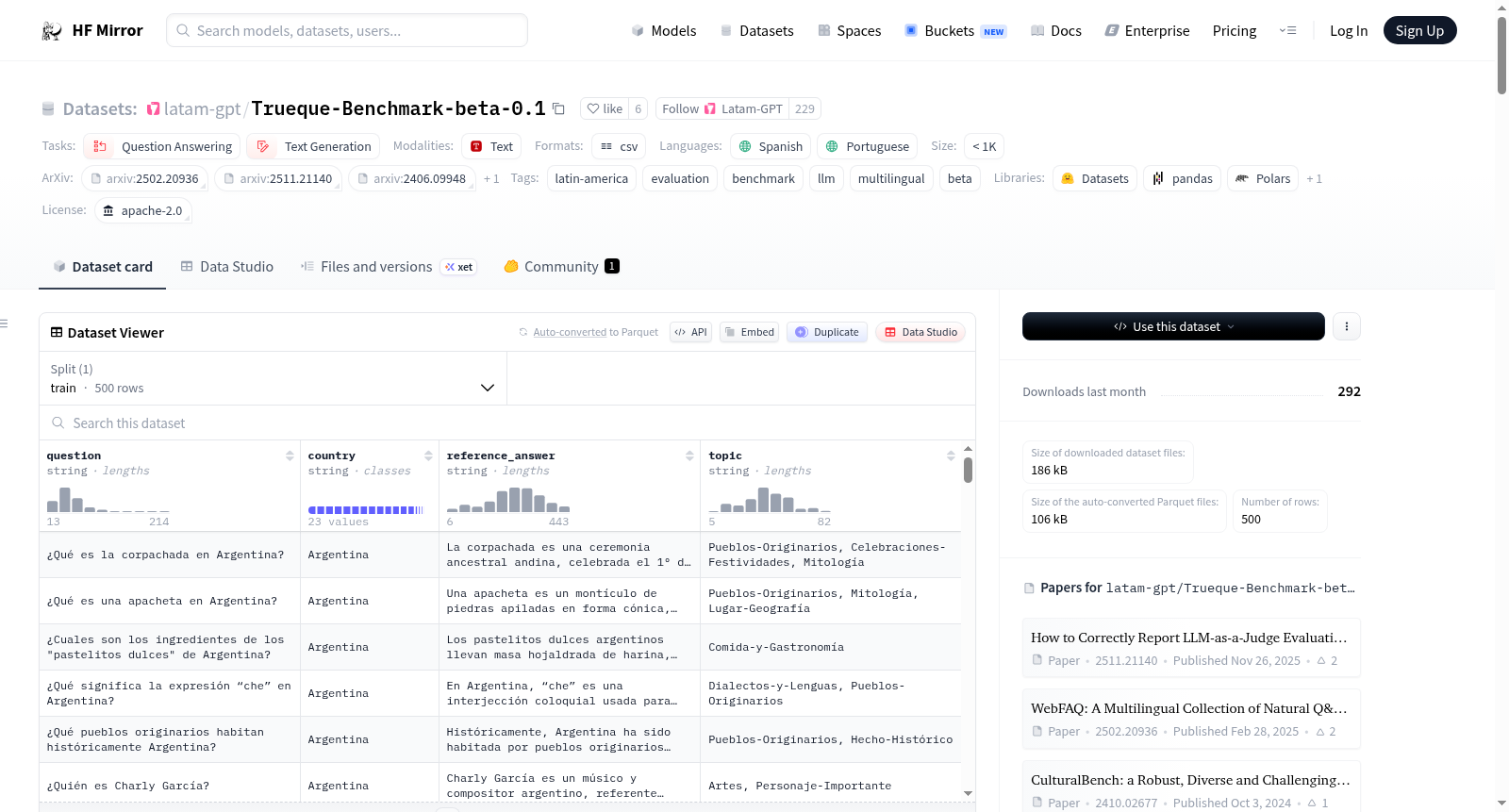
## Data Fields and How to Download
The benchmark examples include the following fields:
- `question`: evaluation question
- `reference_answer`: evidence-based reference answer
- `country`: country associated with the question, when applicable
- `topic`: topic label, when applicable
```python
from datasets import load_dataset
ds_latam = load_dataset("latam-gpt/Trueque-Benchmark-beta-0.1")
```
## Intended Uses
This benchmark is intended for:
- Evaluating LLMs on knowledge related to Latin America
- Comparing model performance on factual and culturally contextualized questions
- Studying hallucinations and uncertainty handling in regional contexts
- Supporting the development of better language technologies for Latin America
## Out-of-Scope Uses
This benchmark is **not** designed to:
- Exhaustively represent all knowledge about Latin America
- Measure all dimensions of intelligence or reasoning
- Provide legal, medical, or other high-impact advice
- Be considered a complete or definitive benchmark in its current beta state
## Limitations and Risks
This beta release has limited coverage and may underrepresent some countries, topics, or cultural domains. It may also reflect biases from retrieved sources and from annotation or curation decisions. Results should therefore be interpreted with caution and complemented with other evaluation settings or human review when possible.
## Citation
```bibtex
@software{Trueque_benchmark_beta_0.1,
title={Trueque: A human-reviewed collaborative benchmark for Latin American knowledge and culture},
author={Fuentes, Gonzalo and Arriagada, Alexandra and Henriquez, Clemente and García, M. Alexandra and LatamGPT Team},
year={2026},
url={https://huggingface.co/latam-gpt/Trueque-Benchmark-beta-0.1}
}
```
## References & brainstorming
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., Toutanova, K., Jones, L., Kelcey, M., Chang, M. W., Dai, A. M., Uszkoreit, J., Le, Q., & Petrov, S. (2019). Natural questions: A benchmark for question answering research. *Transactions of the Association for Computational Linguistics, 7*, 453–466. https://aclanthology.org/Q19-1026/
Dinzinger, M., Caspari, L., Ghosh Dastidar, K., Mitrović, J., & Granitzer, M. (2025). *WebFAQ: A multilingual collection of natural Q&A datasets for dense retrieval*. arXiv. https://arxiv.org/abs/2502.20936
Kim, J., Kong, J., & Son, J. (2024). CLIcK: A benchmark dataset of cultural and linguistic intelligence in Korean. In *Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)* (pp. 3154–3168). Association for Computational Linguistics. https://aclanthology.org/2024.lrec-main.296/
Seveso, A., Potertì, D., Federici, E., Mezzanzanica, M., & Mercorio, F. (2025). ITALIC: An Italian culture-aware natural language benchmark. In *Proceedings of the 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)* (pp. 1469–1478). Association for Computational Linguistics. https://aclanthology.org/2025.naacl-long.68/
Lee, C., Zeng, T. P., Jeong, J., Sohn, J., & Lee, K. (2025). *How to correctly report LLM-as-a-judge evaluations*. arXiv. https://arxiv.org/abs/2511.21140
Myung, J., Lee, N., Zhou, Y., Jin, J., Putri, R. A., Antypas, D., Borkakoty, H., Kim, E., Perez-Almendros, C., Ali Ayele, A., Gutiérrez-Basulto, V., Ibáñez-García, Y., Lee, H., ... Schockaert, S. (2024). *BLEnD: A benchmark for LLMs on everyday knowledge in diverse cultures and languages*. arXiv. https://arxiv.org/abs/2406.09948
Chiu, Y. Y., Jiang, L., Lin, B. Y., Park, C. Y., Li, S. S., Ravi, S., Bhatia, M., Antoniak, M., Tsvetkov, Y., Shwartz, V., & Choi, Y. (2024). *CulturalBench: A robust, diverse, and challenging cultural benchmark by human-AI CulturalTeaming*. arXiv. https://arxiv.org/abs/2410.02677
Lin, S., Hilton, J., & Evans, O. (2022). TruthfulQA: Measuring how models mimic human falsehoods. In *Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)* (pp. 3214–3252). Association for Computational Linguistics. https://aclanthology.org/2022.acl-long.229/
## License
Apache 2.0 - See LICENSE file
提供机构:
latam-gpt
搜集汇总
数据集介绍
构建方式
在拉丁美洲知识评估领域,Trueque数据集的构建体现了严谨的多阶段协作流程。该数据集通过开放式调查问卷广泛征集人类贡献的问题,随后由专业团队进行人工筛选与优化,确保每个问题均具备明确的事实性答案、清晰的评估边界以及与拉丁美洲地区的高度相关性。构建过程中,参考答案的生成采用了证据驱动的自动化流程,即先将问题转化为检索查询,从网络资源中提取关键信息,再结合原始贡献者提供的答案,综合形成基于证据的标准化参考答案。这一方法不仅保障了答案的客观性与可验证性,也为后续的自动化评估奠定了可靠基础。
特点
Trueque数据集的核心特点在于其专注于拉丁美洲地区的知识与文化语境,旨在评估语言模型在该区域的事实准确性与文化适宜性。数据集覆盖了包括阿根廷、巴西、墨西哥等20个拉丁美洲国家,问题主题涉及历史、地理、社会文化等多个维度,具有鲜明的区域代表性与多样性。作为测试版,当前版本收录了500道经过人工审核的问题,并计划扩展至3000道以上,以增强覆盖的广度与深度。数据集的另一显著特征是采用了LLM-as-a-Judge的自动化评估框架,强调对模型回答的事实准确性、细节丰富度以及与参考答案的一致性进行严格量化,同时通过持续的人工审核来校准评估标准,减少因语言模型偏差可能带来的误判。
使用方法
该数据集主要用于评估大型语言模型在拉丁美洲知识与文化背景下的表现。研究人员可通过Hugging Face的datasets库直接加载数据集,利用其中的问题字段对模型进行提问,并将模型生成的回答与提供的参考答案进行对比。评估过程可依托内置的LLM-as-a-Judge框架,从事实准确性、答案对齐度等维度自动评分;也可结合人工审核,尤其针对文化语境微妙或证据不足的案例进行深入分析。数据集适用于跨模型性能比较、区域特异性幻觉研究以及面向拉丁美洲的语言技术优化,但需注意其测试版当前覆盖范围有限,建议在使用时辅以其他评估方法或人工校验以提升结论的稳健性。
背景与挑战
背景概述
随着大语言模型在全球范围内的广泛应用,其在不同文化与地域背景下的知识准确性与文化适应性评估成为自然语言处理领域的关键研究议题。Trueque-Benchmark-beta-0.1数据集由LatamGPT团队于2026年发布,旨在构建一个专注于拉丁美洲知识与文化的评估基准。该数据集通过人类协作方式收集并精心筛选了涵盖20个国家、多个主题的500个问题,并采用证据驱动的流程生成参考答案,以评估模型在区域特定事实与文化语境下的表现。其核心研究问题聚焦于衡量大语言模型对拉丁美洲地区知识的掌握程度与文化恰当性,为开发更具包容性和准确性的语言技术提供了重要数据支撑,推动了多语言与跨文化评估研究的发展。
当前挑战
Trueque-Benchmark-beta-0.1数据集面临的挑战主要体现在两个方面:在领域问题层面,该数据集旨在解决大语言模型在拉丁美洲特定知识与文化背景下的评估难题,这要求模型不仅需具备高精度的事实检索能力,还需深入理解区域文化细微差别,避免生成语言流畅但事实错误或文化不恰当的回应,对模型的跨文化语义理解与事实一致性提出了严峻考验。在构建过程层面,挑战源于数据收集与验证的复杂性,包括确保问题覆盖拉丁美洲多元国家与主题的代表性、通过人工审核剔除主观或模糊内容,以及依据外部证据构建可靠参考答案,同时还需在LLM-as-a-Judge的自动化评估框架中调整指标以减少偏见,确保评估结果的稳健性与可复现性。
常用场景
经典使用场景
在评估大语言模型对拉丁美洲地区知识与文化的理解能力时,Trueque-Benchmark-beta-0.1数据集提供了一个经典的使用场景。该数据集通过精心收集和人工审核的500个问题,覆盖了拉丁美洲20个国家的多元主题,旨在测试模型在区域特定事实知识、文化背景及语言适用性方面的表现。研究者通常利用这一基准,结合LLM-as-a-Judge的自动化评估框架,系统性地衡量模型生成的答案在事实准确性、细节丰富度以及与参考答案的对齐程度上的优劣,从而揭示模型在跨文化语境中的潜在局限与优势。
解决学术问题
Trueque-Benchmark-beta-0.1数据集主要解决了大语言模型在区域知识与文化评估领域的若干学术研究问题。它针对模型在拉丁美洲语境下可能出现的知识幻觉、文化误判及事实性错误提供了系统的测量工具,帮助研究者深入探究模型在多语言、跨文化环境中的泛化能力与偏差来源。该数据集的构建强调了证据驱动的参考答案生成与人工审核流程,为评估方法的标准化与可靠性设立了初步范例,推动了语言技术在地域化应用中的科学评估与理论发展。
衍生相关工作
Trueque-Benchmark-beta-0.1数据集的推出,衍生并启发了多项围绕文化与地域知识评估的经典研究工作。它借鉴并融合了如Natural Questions、BLEnD、CulturalBench等基准在问答构建与多文化评估方面的设计理念,同时其采用的LLM-as-a-Judge评估框架亦受到相关方法论研究的指导。这些工作共同促进了区域化评估基准的多样化发展,为后续针对特定语言或文化群体的评估工具开发提供了可参考的范式与协作模式。
以上内容由遇见数据集搜集并总结生成


