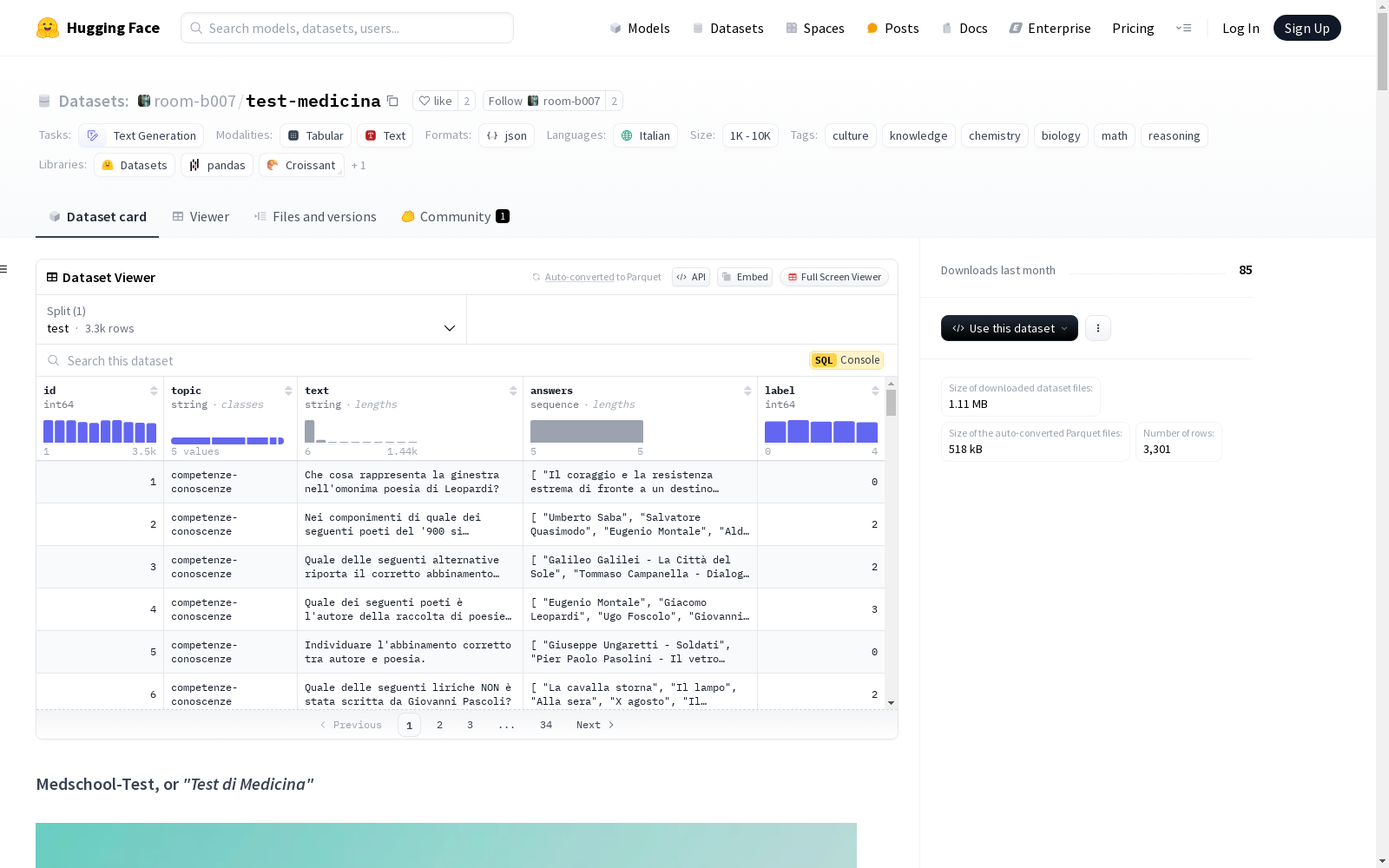
test-medicina
收藏Medschool-Test, or "Test di Medicina"
概述
- 任务类别: 文本生成
- 语言: 意大利语
- 数据规模: 1K<n<10K
- 配置:
- 配置名称: italian
- 数据文件:
- 分割: test
- 路径: medical_school_questions.jsonl
- 标签:
- culture
- knowledge
- chemistry
- biology
- math
- reasoning
- 美观名称: Test di Medicina
数据集描述
- 目标: 评估大型语言模型(LLMs)在意大利医学院入学考试中的表现。
- 内容: 包含来自意大利医学院入学考试的多项选择题,涵盖生物学、化学、物理、数学、世界知识等多个学科。
- 示例: 每个问题包含五个选项,其中一个为正确答案。
特征
- 语言: 目前仅提供意大利语版本,英语版本即将推出。
- 主题: 问题涵盖生物学、化学、物理、数学、世界知识等多个学科。
- 格式:
- 多项选择: 每个问题有五个选项,其中一个为正确答案。
- 填空风格: 问题不提供选项,模型需生成正确答案。
- 规模: 包含超过3K高质量问题,适合评估LLMs。
评估
- 评估指标:
- 多项选择格式: 模型选择正确答案的能力。
- 填空风格格式: 模型生成正确答案的能力。
- 评分:
- 正确答案: 1.5分
- 错误答案: -0.4分
- 无答案: 0.0分
- 最终得分: 根据各学科的权重计算加权平均分。
数据
- 来源: 数据集来自意大利教育、大学和研究部(MIUR)的官方网站,包含过去医学院入学考试的问题。
- 组成: 包含超过3K个问题,涵盖生物学、化学、物理、数学、世界知识等多个学科。
- 格式: 数据以JSONL格式提供,每行代表一个问题。
示例
-
生物学: json { "id": 1691, "topic": "biologia", "text": "Come sono definite le cellule staminali che sono in grado di differenziarsi in tutti i tipi di cellule presenti nel corpo umano, ma non possono dare origine ad un organismo completo?", "answers": [ "Cellule Staminali Multipotenti", "Cellule Staminali Pluripotenti", "Cellule Staminali Totipotenti", "Cellule Staminali Unipotenti", "Cellule Staminali Oligopotenti" ], "label": 1 }
-
化学: json { "id": 19, "topic": "chimica", "text": "Rispetto alla classificazione che si trova nella tavola periodica il fluoro fa parte del: ", "answers": [ "gruppo dei gas nobili", "gruppo degli alogeni", "gruppo dei lantanidi", "secondo gruppo", "quarto periodo" ], "label": 1 }
-
数学与物理: json { "id": 1203, "topic": "fisica-matematica", "text": "Quali sono le coordinate del centro della circonferenza di equazione x^2 + y^2 + 2x – 6y + 5 = 0?", "answers": [ "(2 ; –6)", "(–2 ; 6)", "(1 ; 3)", "(–1 ; 3)", "(2 ; 3)" ], "label": 3 }
-
世界知识: json { "id": 11, "topic": "competenze-conoscenze", "text": "Quale dei seguenti è il primo romanzo di Italo Calvino, pubblicato nel 1947?", "answers": [ "Se una notte dinverno un viaggiatore", "Il barone rampante", "Palomar", "Le cosmicomiche", "Il sentiero dei nidi di ragno" ], "label": 4 }
-
逻辑与推理: json { "id": 2539, "topic": "logica", "text": "Tutti i pasticcieri praticano il kendo; Gianluca pratica il kendo. Quale delle seguenti affermazioni aggiuntive consentirebbe di dedurre con certezza che Gianluca è un pasticciere?", "answers": [ "Tra le persone che praticano kendo vi sono dei pasticcieri", "Alcune persone che praticano kendo si chiamano Gianluca", "Alcune persone che praticano kendo sono pasticcieri", "Non è certo che ogni persona che pratica kendo sia anche un pasticciere", "Ogni persona che pratica kendo è anche un pasticciere" ], "label": 4 }
许可证
- 许可证: Apache 2.0 License