pd-extended
收藏Hugging Face2025-06-07 更新2025-06-08 收录
下载链接:
https://huggingface.co/datasets/Spawning/pd-extended
下载链接
链接失效反馈官方服务:
资源简介:
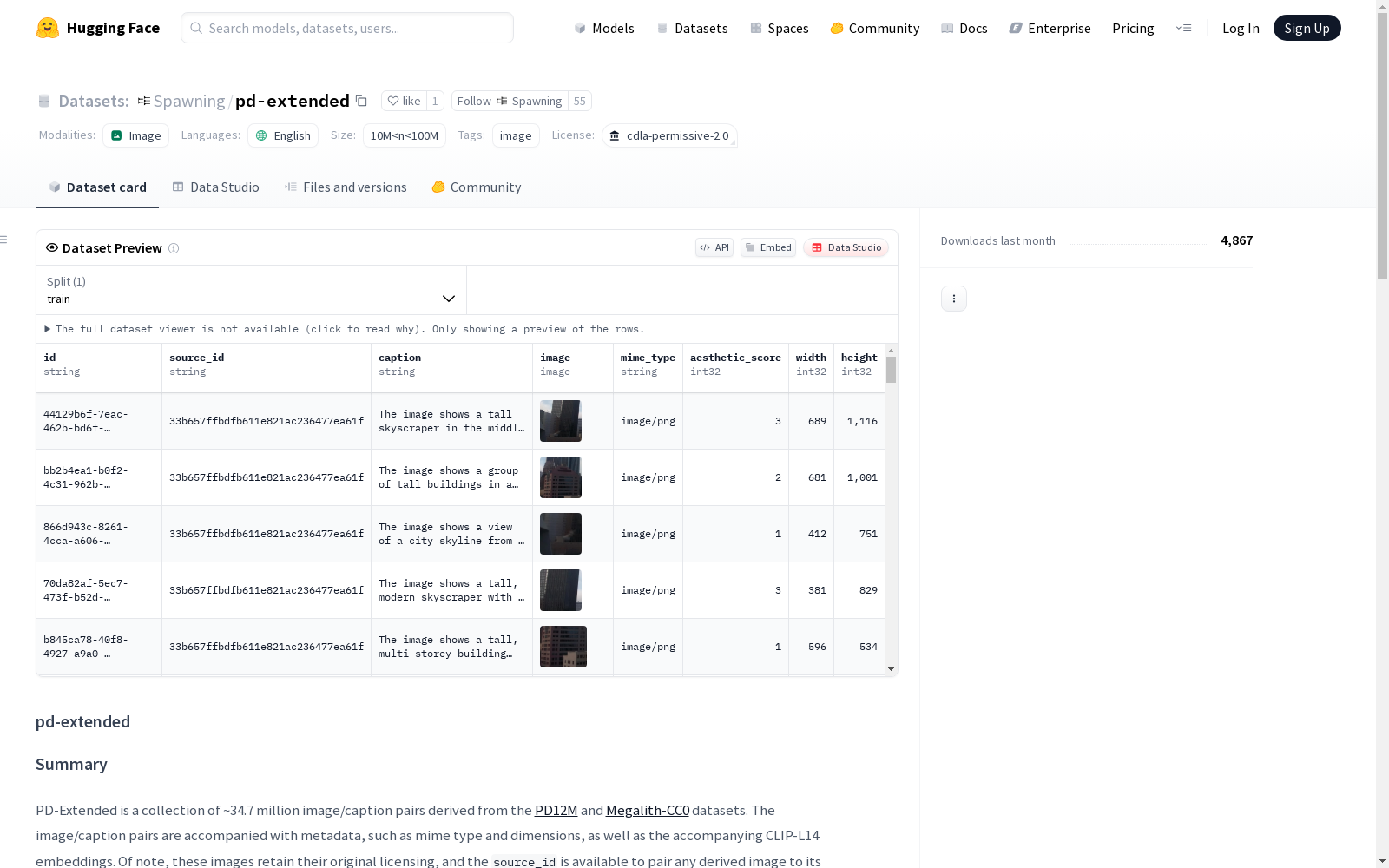
pd-extended是一个从PD12M中提取并经过合成裁剪的图片集合。数据集包含图片的id、来源id、标题、图片本身、MIME类型、审美评分、宽度和高度等信息。
创建时间:
2025-06-06
搜集汇总
数据集介绍
构建方式
PD-Extended数据集通过美学裁剪技术对PD12M和Megalith-CC0原始图像进行智能扩展,运用目标检测算法从原始图像中提取有效对象区域,生成符合256×256像素阈值的新图像样本。该构建过程严格遵循尺寸过滤、重叠区域排除及美学评分筛选三重质量控制机制,最终从3470万原始图像中衍生出3475万高质量图像-文本对,显著提升了数据密度与多样性。
特点
本数据集核心特征在于全面覆盖公共领域与CC0许可图像资源,每张图像均配备由Florence-2模型生成的合成文本描述及CLIP-L14嵌入向量。数据集提供多维元数据支持,包括图像尺寸、美学评分、MIME类型等结构化字段,并通过source_id字段保持与原始数据集的溯源关联。其独特价值体现在通过美学裁剪技术突破公共领域数据量限制,为生成模型训练提供富含细节的增强样本。
使用方法
研究者可通过HuggingFace数据集库直接加载parquet格式图像数据与numpy格式嵌入向量,利用caption字段进行多模态模型训练。数据集采用分目录结构组织,pd12m与megalith-cc0子目录分别包含图像文件与嵌入向量,用户可通过source_id实现跨数据集溯源。建议通过GIT_LFS_SKIP_SMUDGE参数优化大文件下载流程,高效获取图像字节数据与关联元数据用于模型训练。
背景与挑战
背景概述
PD-Extended数据集作为计算机视觉与多模态学习领域的重要资源,由Spawning研究团队于2023年构建完成。该数据集整合了PD12M与Megalith-CC0两大开源图像资源,通过Florence-2模型生成合成标注,形成了包含3470万图像-文本对的大规模集合。其核心研究目标在于突破公共领域图像数据稀缺性对生成模型训练的制约,通过技术创新最大化有限数据的利用效率。该数据集为图像生成、跨模态检索等研究方向提供了高质量的合法数据支撑,显著降低了版权风险对人工智能研究的干扰。
当前挑战
在领域问题层面,PD-Extended致力于解决公共领域图像数据规模有限与生成模型训练需求之间的矛盾。传统方法直接缩放图像会导致细节丢失,而该数据集通过美学裁剪技术实现对象级数据增强,但需克服对象检测精度与美学评分可靠性的双重挑战。构建过程中面临原始图像异构性处理、跨数据集标识符映射,以及大规模图像处理的计算复杂度等工程难题。同时需确保衍生图像保持原始许可协议,并在合成标注生成过程中维持语义一致性,这些因素共同构成了数据集构建的多维度挑战。
常用场景
经典使用场景
在计算机视觉与多模态学习领域,pd-extended数据集通过美学裁剪技术将原始图像分解为高质量的对象级图像-文本对,为生成模型训练提供了丰富素材。该数据集广泛应用于视觉-语言预训练任务,特别是文本到图像生成模型的训练过程中,能够有效提升模型对细节特征的捕捉能力与生成图像的真实感。
实际应用
pd-extended数据集在创意产业和数字内容生成领域具有重要应用价值,为广告设计、游戏资产创建和影视特效制作提供高质量的视觉素材。其CC0许可特性使得商业应用无需担心版权问题,而丰富的对象级图像数据特别适合训练定制化的图像生成系统,支持个性化内容创作需求。
衍生相关工作
基于pd-extended数据集衍生了多项重要研究,包括基于美学评分的图像筛选算法改进、多尺度对象检测技术的优化,以及结合CLIP嵌入的跨模态检索系统。这些工作显著提升了生成模型对复杂场景的理解能力,并为数据增强技术在视觉任务中的应用提供了新的方法论指导。
以上内容由遇见数据集搜集并总结生成


