wikitext-unlearning-mia
收藏Hugging Face2025-12-21 更新2025-12-22 收录
下载链接:
https://huggingface.co/datasets/h0ssn/wikitext-unlearning-mia
下载链接
链接失效反馈官方服务:
资源简介:
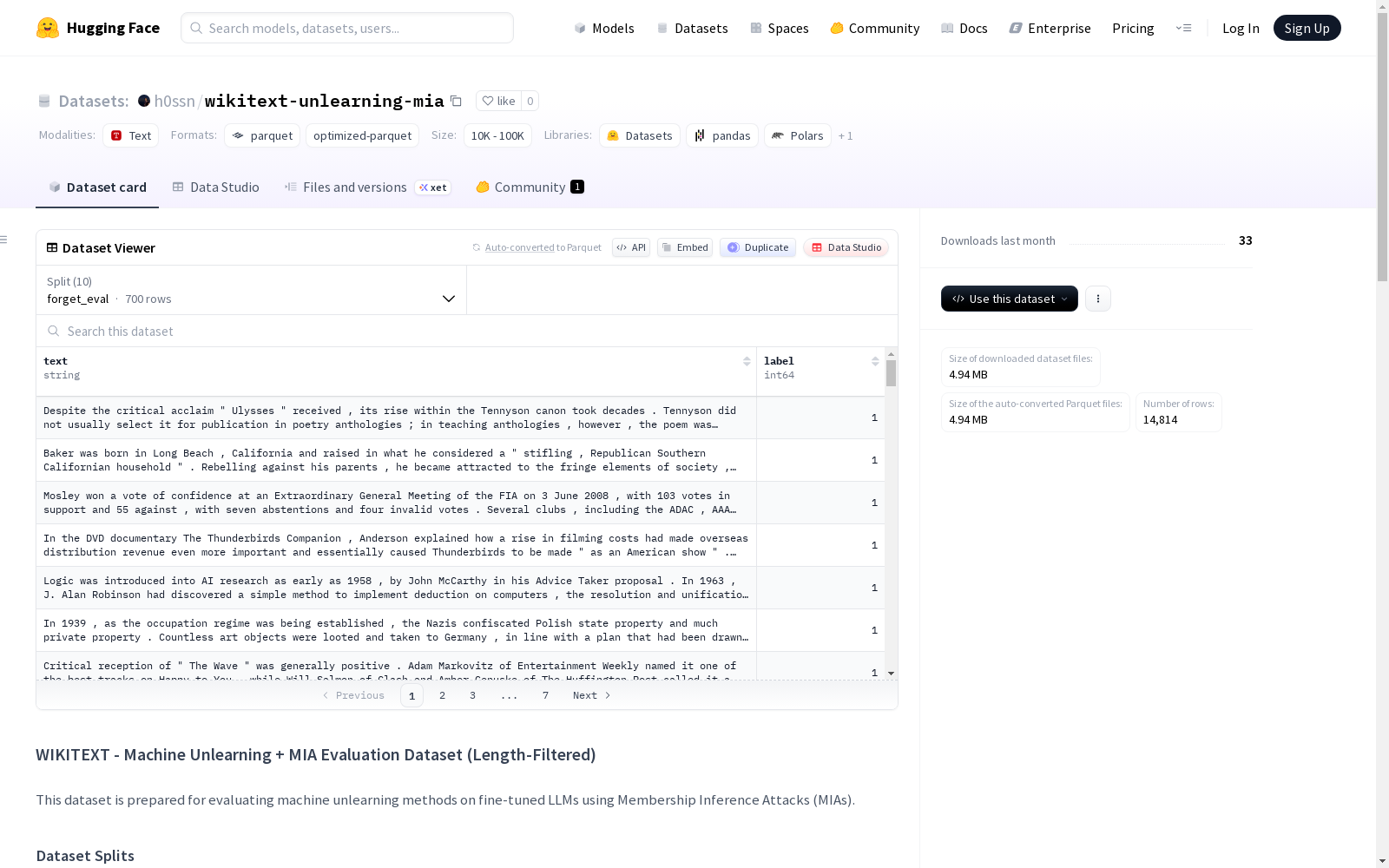
该数据集是为评估机器学习中的'遗忘学习'方法和成员推理攻击(MIA)而准备的。它包含训练集和评估集,训练集分为保留集(9000样本)和遗忘集(1000样本),评估集则根据文本长度(96、128、192 tokens)分为不同版本。评估集的结构包括来源、成员关系和标签信息,用于测量遗忘前后的成员泄漏情况。数据集适用于机器学习遗忘、MIA评估、隐私研究和长度控制的MIA评估。
创建时间:
2025-12-11
原始信息汇总
数据集概述
数据集基本信息
- 数据集名称: WIKITEXT - Machine Unlearning + MIA Evaluation Dataset (Length-Filtered)
- 地址: https://huggingface.co/datasets/h0ssn/wikitext-unlearning-mia
- 用途: 用于评估基于微调大语言模型的机器遗忘方法,并使用成员推理攻击进行评估。
数据结构
- 特征:
text(数据类型: string)label(数据类型: int64)
数据划分
训练集(用于遗忘)
- 保留集:
retain_set,包含 9,000 个样本,在遗忘过程中需要保留的数据。 - 遗忘集:
forget_set,包含 1,000 个样本,需要被遗忘的数据。
评估集(用于成员推理攻击)- 经过长度过滤
评估集包含不同长度的变体,每个评估数据集最多包含 700 个样本,结构如下:
| 索引范围 | 来源 | 成员关系 | 标签 |
|---|---|---|---|
| 0-349 | 微调数据集的子集 | 成员 | 1 |
| 350-699 | 原始测试集划分 | 非成员 | 0 |
注意: 实际样本数量可能因符合长度标准的样本可用性而异。
WikiText 长度变体
- 96 个词元: 中等长度段落,对应评估集
retain_eval_96和forget_eval_96。 - 128 个词元: 长段落(推荐使用),对应评估集
retain_eval_128和forget_eval_128。 - 192 个词元: 超长段落,对应评估集
retain_eval_192和forget_eval_192。
长度过滤
所有评估集划分都经过过滤,以匹配特定的词元长度(允许 ±10 个词元的容差)。这种长度匹配旨在防止模型使用序列长度作为成员推理的信号,该方法遵循 Win-k MIA 论文的方法论。
使用案例
该数据集设计用于:
- 机器遗忘: 训练模型以“遗忘”遗忘集,同时在保留集上保持性能。
- 成员推理攻击评估: 使用评估集划分来测量遗忘前后的成员信息泄露。
- 隐私研究: 研究遗忘方法在保护数据隐私方面的有效性。
- 长度控制的成员推理攻击: 在没有长度混淆因素的情况下评估成员推理攻击。
引用
如果使用此数据集,请引用建立了长度过滤方法论的 Win-k MIA 论文。
许可证
请参考原始数据集的许可证。
搜集汇总
数据集介绍
构建方式
在机器遗忘与成员推理攻击评估领域,该数据集基于WikiText语料库构建,通过精细划分训练与评估子集来支持系统性研究。其构建过程首先从原始数据中分离出保留集与遗忘集,分别包含九千条与一千条样本,用于模拟机器遗忘任务中需保留与需遗忘的数据。评估部分则进一步依据文本长度进行筛选,生成了96、128及192三种令牌长度的变体,每种变体均包含成员与非成员样本,并通过严格控制长度容差以消除序列长度对成员推理的潜在干扰,确保了评估的严谨性。
特点
该数据集的核心特点在于其针对机器遗忘与隐私评估的专门化设计。它提供了结构清晰的训练集与评估集,其中评估集特别引入了长度过滤机制,有效避免了模型利用文本长度作为成员推断的混淆因素,从而提升了成员推理攻击评估的准确性。数据集涵盖多种文本长度变体,尤以128令牌版本为推荐选项,为不同复杂度的实验需求提供了灵活性。此外,每个评估子集均明确标注样本来源与成员身份,支持直接用于隐私泄露量化分析,为机器遗忘算法的效能与数据保护研究提供了可靠基准。
使用方法
使用该数据集时,研究人员可通过Hugging Face的datasets库便捷加载全部数据分割。首先加载数据集对象后,可分别访问retain_set与forget_set以进行机器遗忘模型的训练与微调。对于成员推理攻击评估,则需根据实验需求选择特定长度的评估子集,如retain_eval_128与forget_eval_128,这些子集已预设成员与非成员标签,便于直接计算攻击准确率等指标。通过系统比较遗忘前后模型在评估集上的表现,能够量化遗忘效果与隐私增强程度,从而推动机器遗忘与数据隐私领域的方法学进展。
背景与挑战
背景概述
随着大型语言模型在文本生成、摘要等任务中的广泛应用,模型训练数据中的隐私泄露风险日益凸显。在此背景下,wikitext-unlearning-mia数据集应运而生,专为评估机器遗忘方法在微调语言模型中的效果而设计。该数据集由研究社区基于WikiText语料库构建,旨在通过成员推理攻击来衡量遗忘机制对数据隐私的保护能力。其核心研究问题聚焦于如何使模型高效遗忘特定数据子集,同时保持整体性能,为隐私保护机器学习提供了重要的实证基础。
当前挑战
该数据集致力于解决机器遗忘领域中的关键挑战,即如何在遗忘指定数据后有效防止成员推理攻击,从而保障用户隐私。构建过程中的主要挑战在于确保评估数据的纯净性,避免序列长度等无关特征干扰攻击结果的判断。为此,数据集通过严格的长度过滤机制,将文本样本控制在特定令牌数范围内,以消除长度作为成员推断的信号源。这一设计虽提升了评估的严谨性,但也对数据筛选和平衡提出了更高要求,增加了构建复杂度。
常用场景
经典使用场景
在机器遗忘与隐私保护研究领域,wikitext-unlearning-mia数据集为评估大型语言模型的遗忘效能提供了标准化基准。其核心应用场景在于,研究者通过将数据集划分为保留集与遗忘集,模拟模型在微调后需遗忘特定敏感信息的情境,进而利用成员推理攻击(MIA)评估模型在遗忘前后对数据成员身份的泄露程度。该数据集通过严格控制文本长度变体,如128个标记的推荐版本,有效消除了序列长度作为成员推断的混淆因素,使得评估结果更具鲁棒性与可比性。
实际应用
在实际应用层面,wikitext-unlearning-mia数据集服务于需要合规性数据处理的行业场景,例如在金融服务或医疗健康领域,当模型训练涉及用户敏感文本数据后,依法需执行“被遗忘权”删除操作。该数据集允许机构测试不同遗忘策略的有效性,确保模型在移除特定数据后,不仅保持核心性能,更能显著降低通过推理攻击复原原始成员信息的风险,从而满足日益严格的数据保护法规要求,如GDPR或CCPA。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在机器遗忘算法与隐私评估框架的创新上。例如,基于其长度控制设计,后续研究扩展了多模态或跨领域场景下的遗忘评估基准。同时,许多成员推理攻击的改进方法,如基于梯度或置信度的攻击变体,常利用该数据集进行公平比较与验证。这些工作共同深化了对模型记忆机制的理解,并促进了隐私增强技术与可遗忘机器学习系统的发展。
以上内容由遇见数据集搜集并总结生成


