MMInstruction/ArxivQA
收藏数据集卡片:Mutlimodal Arxiv QA
数据集加载说明
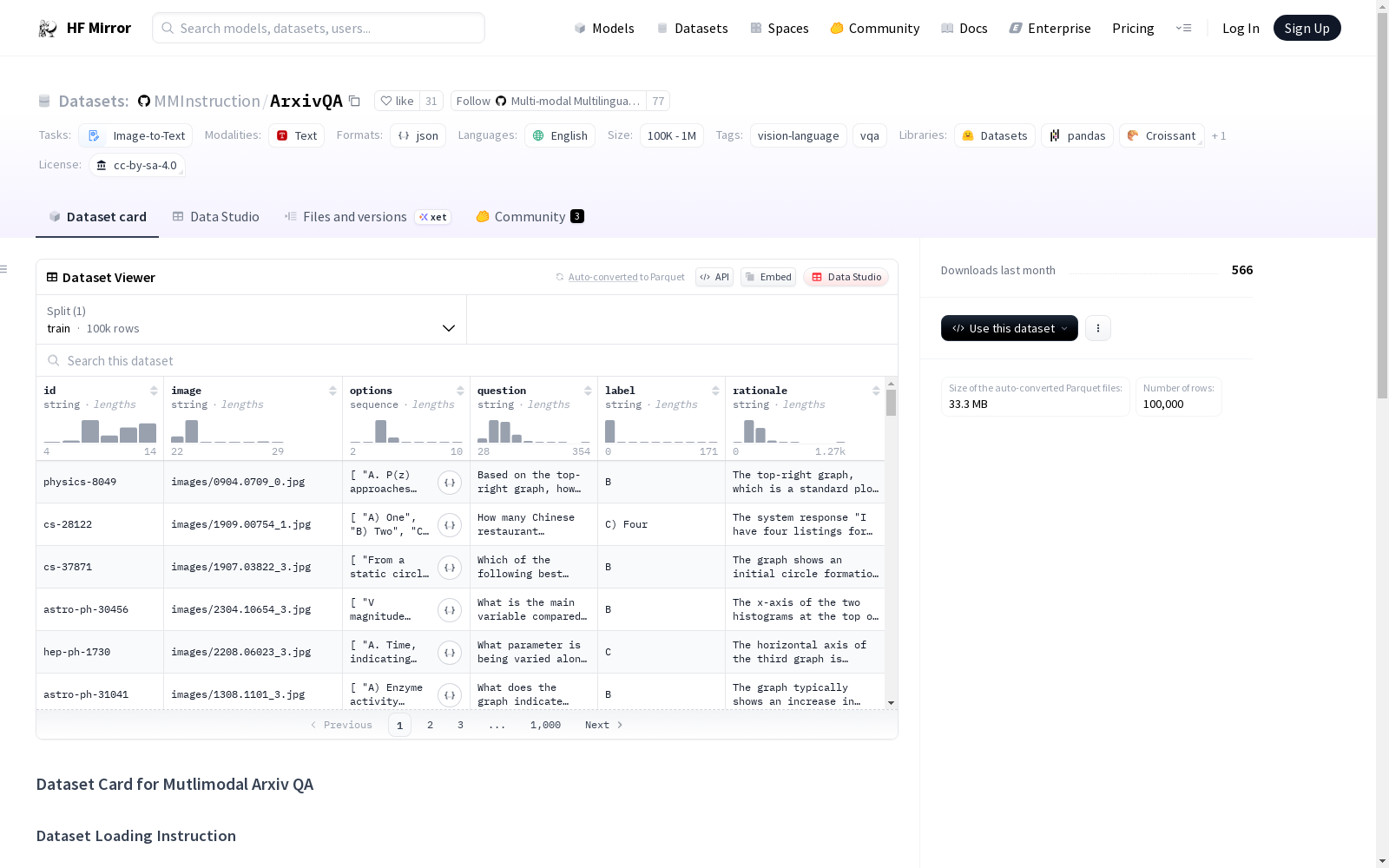
每个 arxivqa.jsonl 文件中的一行是一个示例:
json {"id": "cond-mat-2862", "image": "images/0805.4509_1.jpg", "options": ["A) The ordering temperatures for all materials are above the normalized temperature ( T/T_c ) of 1.2.", "B) The magnetic ordering temperatures decrease for Dy, Tb, and Ho as the normalized temperature ( T/T_c ) approaches 1.", "C) The magnetic ordering temperatures for all materials are the same across the normalized temperature ( T/T_c ).", "D) The magnetic ordering temperature is highest for Yttrium (Y) and decreases for Dy, Tb, and Ho."], "question": "What can be inferred about the magnetic ordering temperatures of the materials tested as shown in the graph?", "label": "B", "rationale": "The graph shows a sharp decline in frequency as the normalized temperature ( T/T_c ) approaches 1 for Dy, Tb, and Ho, indicating that their magnetic ordering temperatures decrease. No such data is shown for Yttrium (Y), thus we cant infer it has the highest magnetic ordering temperature." }
- 下载
arxivqa.json和images.tgz到您的机器。 - 解压缩图像:
tar -xzvf images.tgz。 - 根据需要加载数据集并处理样本。
python import json
with open("arxivqa.jsonl", r) as fr: arxiv_qa = [ json.loads(line.strip()) for line in fr]
sample = arxiv_qa[0] print(sample["image"]) # 图像文件
数据集详情
数据集类型:ArxivQA 是一组基于 Arxiv 论文中的图表生成的 GPT4V 生成的 VQA 样本。
许可证:CC-BY-SA-4.0;并且应遵守 OpenAI 的政策:https://openai.com/policies/terms-of-use
预期用途:
主要预期用途:ArxivQA 的主要用途是研究大型多模态模型。
主要预期用户:该模型的主要预期用户是计算机视觉、自然语言处理、机器学习和人工智能领域的研究人员和爱好者。