thomas-2018-spark-all
收藏Hugging Face2025-10-22 更新2025-10-23 收录
下载链接:
https://huggingface.co/datasets/scbirlab/thomas-2018-spark-all
下载链接
链接失效反馈官方服务:
资源简介:
SPARK数据集:一个包含人类整理和标准化MICs的数据集,适用于不同细菌物种,包括化合物的SMILES字符串和相关特征,已分割为训练集、验证集和测试集,用于抗生素药物发现模型的开发。
创建时间:
2025-10-21
原始信息汇总
SPARK数据集概述
基本信息
- 数据集名称: SPARK dataset of human-curated and standardized MICs
- 许可证: CC-BY-NC-4.0
- 任务类别: 文本分类
- 标签: 化学、生物学、抗生素、SMILES
- 数据规模: 10万到100万条之间
数据集描述
- 数据集内容: 人类整理和标准化的最小抑菌浓度数据
- 主要用途: 开发抗生素药物发现的化学模型
- 整理者: @eachanjohnson
- 资助方: The Francis Crick Institute
数据配置
数据集提供多种配置:
主要配置
- unsplit: 包含单个训练文件 spark-all.csv.gz
- all: 包含训练、验证和测试分割的完整数据集
物种特定配置
12个细菌物种的独立数据集,每个都包含训练、验证和测试分割:
- 鲍曼不动杆菌 (5,247行)
- 炭疽芽孢杆菌 (9,940行)
- 流产布鲁氏菌 (9,947行)
- 粪肠球菌 (1,342行)
- 大肠杆菌 (28,863行)
- 土拉弗朗西斯菌 (9,681行)
- 肺炎克雷伯菌 (6,306行)
- 铜绿假单胞菌 (37,260行)
- 金黄色葡萄球菌 (4,024行)
- 肺炎链球菌 (1,540行)
- 小肠结肠炎耶尔森菌 (1,405行)
- 鼠疫耶尔森菌 (10,003行)
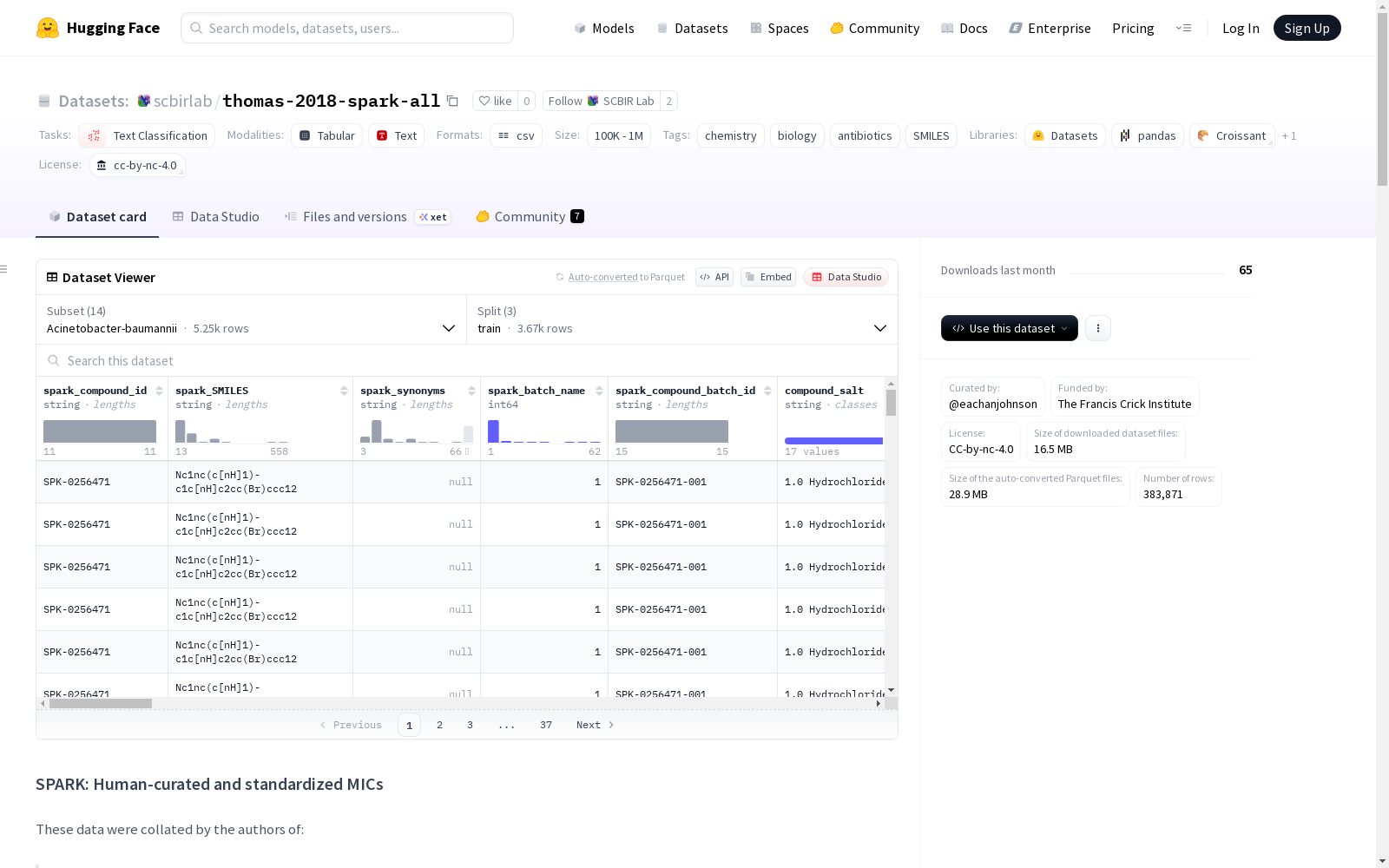
数据结构
数据集包含以下主要字段:
化合物标识
- spark_compound_id: 原始化合物标识符
- spark_SMILES: 原始SMILES字符串
- inchikey: 化合物唯一标识符
- smiles: RDKit规范化的SMILES字符串
MIC数据
- mic_micromolar: 原始最小抑菌浓度
- mic_ineq_operator: 不等式操作符转换
- plain_mic_micromolar: 去除不等式符号的MIC
- pmic: pMIC值
生物学信息
- species: 细菌物种
- strain_name: 细菌菌株
- strain_genotype: 菌株基因型
- accumulation_phenotype: 积累表型
化学特征
- scaffold: Murcko骨架
- mwt: 分子量
- clogp: Crippen LogP
- tpsa: 拓扑极性表面积
数据分割
- is_train: 训练集标记
- is_test: 测试集标记
- is_validation: 验证集标记
数据处理
- SMILES字符串已规范化
- 使用Murcko骨架进行数据分割
- 训练集70%,验证集15%,测试集15%
- 使用schemist工具进行数据处理
数据来源
- 原始数据: https://www.collaborativedrug.com/spark-data-downloads
- 相关论文: https://doi.org/10.1021/acsinfecdis.8b00193
引用信息
bibtex @article{doi:10.1021/acsinfecdis.8b00193, author = {Thomas, Joe and Navre, Marc and Rubio, Aileen and Coukell, Allan}, title = {Shared Platform for Antibiotic Research and Knowledge: A Collaborative Tool to SPARK Antibiotic Discovery}, journal = {ACS Infectious Diseases}, volume = {4}, number = {11}, pages = {1536-1539}, year = {2018}, doi = {10.1021/acsinfecdis.8b00193} }
搜集汇总
数据集介绍
构建方式
在抗生素药物发现领域,SPARK数据集通过整合多源文献中的最小抑菌浓度数据构建而成。原始数据经过系统清洗,剔除了空值并精简了字段命名,同时采用schemist化学数据处理工具对SMILES字符串进行标准化处理。为确保模型泛化能力,数据集依据Murcko骨架结构对每个物种的化合物进行划分,生成训练集、验证集和测试集,并计算了分子量、拓扑极性表面积等关键分子描述符。
特点
该数据集涵盖12种重要病原菌的标准化MIC数据,规模达十万至百万级别,每个物种配置独立的数据子集。其核心特征在于包含原始文献来源标识、标准化pMIC数值以及完整的分子结构信息,特别是通过Murcko骨架划分策略有效避免了分子相似性对模型评估的干扰。所有数据均经过人工校验与化学信息学处理,确保了抗生素活性数据的准确性与可比性。
使用方法
研究人员可通过HuggingFace平台直接加载特定病原菌配置或完整数据集,利用预划分的训练-验证-测试集开展抗生素活性预测模型开发。数据集提供的标准化SMILES字符串与分子描述符可直接用于构建化学信息学模型,而丰富的元数据字段支持多维度分析。建议遵循CC-BY-NC-4.0许可协议,在模型训练时注意利用骨架划分特性验证模型的泛化性能。
背景与挑战
背景概述
抗生素耐药性危机已成为全球公共卫生领域的严峻挑战,促使研究人员开发新型抗菌药物。2018年,由Joe Thomas、Marc Navre、Aileen Rubio和Allan Coukell等学者创建的SPARK数据集应运而生,该数据集汇集了人类精心整理和标准化的最小抑菌浓度数据。作为化学与生物学交叉领域的重要资源,该数据集通过SMILES字符串和Murcko骨架结构等分子表征,为抗生素发现研究提供了标准化基准。其涵盖鲍曼不动杆菌、炭疽杆菌等十余种病原菌的MIC数据,有效推动了计算化学与药物设计领域的协同发展。
当前挑战
在抗生素效力预测领域,模型需克服分子结构多样性带来的泛化难题,同时准确解析包含不等式的MIC数值表征。数据集构建过程中,研究者面临原始数据标准化处理的复杂性,包括SMILES字符串规范化、Murcko骨架分割以及不等式运算符转换等技术瓶颈。跨物种数据整合时,还需解决不同实验条件下MIC测量方法的异质性,确保十余种病原菌数据的可比性与一致性。
常用场景
经典使用场景
在抗生素药物发现领域,SPARK数据集以其标准化最小抑菌浓度数据和规范化的SMILES分子表示,成为机器学习模型训练的重要基础。该数据集通过支架分割策略确保模型泛化能力,广泛应用于化合物抗菌活性预测任务。研究人员利用其丰富的分子特征和多种病原菌的MIC数据,构建能够准确识别潜在抗生素候选分子的分类模型,为高通量虚拟筛选提供可靠支持。
实际应用
在制药工业实践中,SPARK数据集被广泛应用于先导化合物优化阶段。药物化学家利用基于该数据集训练的预测模型,快速评估新合成化合物的抗菌谱和效力,显著缩短研发周期。临床前研究中,该数据集支持的模型能够辅助研究人员识别对多重耐药菌有效的候选分子,为应对日益严峻的抗生素耐药性问题提供计算工具。
衍生相关工作
基于SPARK数据集衍生的研究工作主要集中在深度学习方法开发领域。研究人员构建了多种图神经网络和Transformer架构,用于学习分子结构与抗菌活性间的复杂映射关系。这些模型在预测新型化合物的抗菌活性方面展现出卓越性能,推动了计算辅助药物设计方法的发展。相关成果已应用于抗菌肽设计和多靶点抗生素发现等前沿研究方向。
以上内容由遇见数据集搜集并总结生成


