Joint-1.6M-1024px
收藏Hugging Face2025-06-18 更新2025-06-19 收录
下载链接:
https://huggingface.co/datasets/VIPL-GENUN/Joint-1.6M-1024px
下载链接
链接失效反馈官方服务:
资源简介:
Joint-1.6M数据集是一个包含约20万张高质量、高分辨率图像的数据集,这些图像从多个公开来源收集而来。图像经过先进的预测器自动标注,涵盖了7个特定领域的标签。数据集还包括使用BLIP2-OPT-2.7b和Qwen2-VL-7b-Instruct生成的图像标题。
创建时间:
2025-06-13
原始信息汇总
Joint-1.6M Dataset 概述
数据集来源
- 数据集整合了多个公开来源的高质量和多样化图像,包括:
- Subjects200K
- Aesthetic-4K
- Pexels photos
- Pexels portrait
数据集特点
- 所有图像分辨率均超过1024×1024。
- 使用先进的预测器自动标注了7个特定领域的标签:
- 线稿(line arts)
- 边缘图(edge maps)
- 深度图(depth maps)
- 法线图(normal maps)
- 反射率图(albedos)
- 分割色图(segmentation colormaps)
- 人体骨架(human skeletons)
- 包含约200K图像,每张图像对应约7×200K预测标签。
- 使用BLIP2-OPT-2.7b和Qwen2-VL-7b-Instruct生成图像描述:
- BLIP2-OPT-2.7b:简洁描述图像主体。
- Qwen2-VL-7b-Instruct:详细描述主体、背景和整体氛围。
数据集配置
- Aesthetic-4K:metadata.jsonl
- Subjects200K_collection3:metadata.jsonl
- pexels-portrait:metadata.jsonl
- pexels-photos-janpf:
- 训练集:metadata.train.jsonl
- 测试集:metadata.test.jsonl
相关资源
- 论文:https://arxiv.org/abs/2505.19084
- 项目页面:https://VIPL-GENUN.github.io/Project-Jodi
- GitHub:https://github.com/VIPL-GENUN/Jodi
引用
bibtex @article{xu2025jodi, title={Jodi: Unification of Visual Generation and Understanding via Joint Modeling}, author={Xu, Yifeng and He, Zhenliang and Kan, Meina and Shan, Shiguang and Chen, Xilin}, journal={arXiv preprint arXiv:2505.19084}, year={2025} }
搜集汇总
数据集介绍
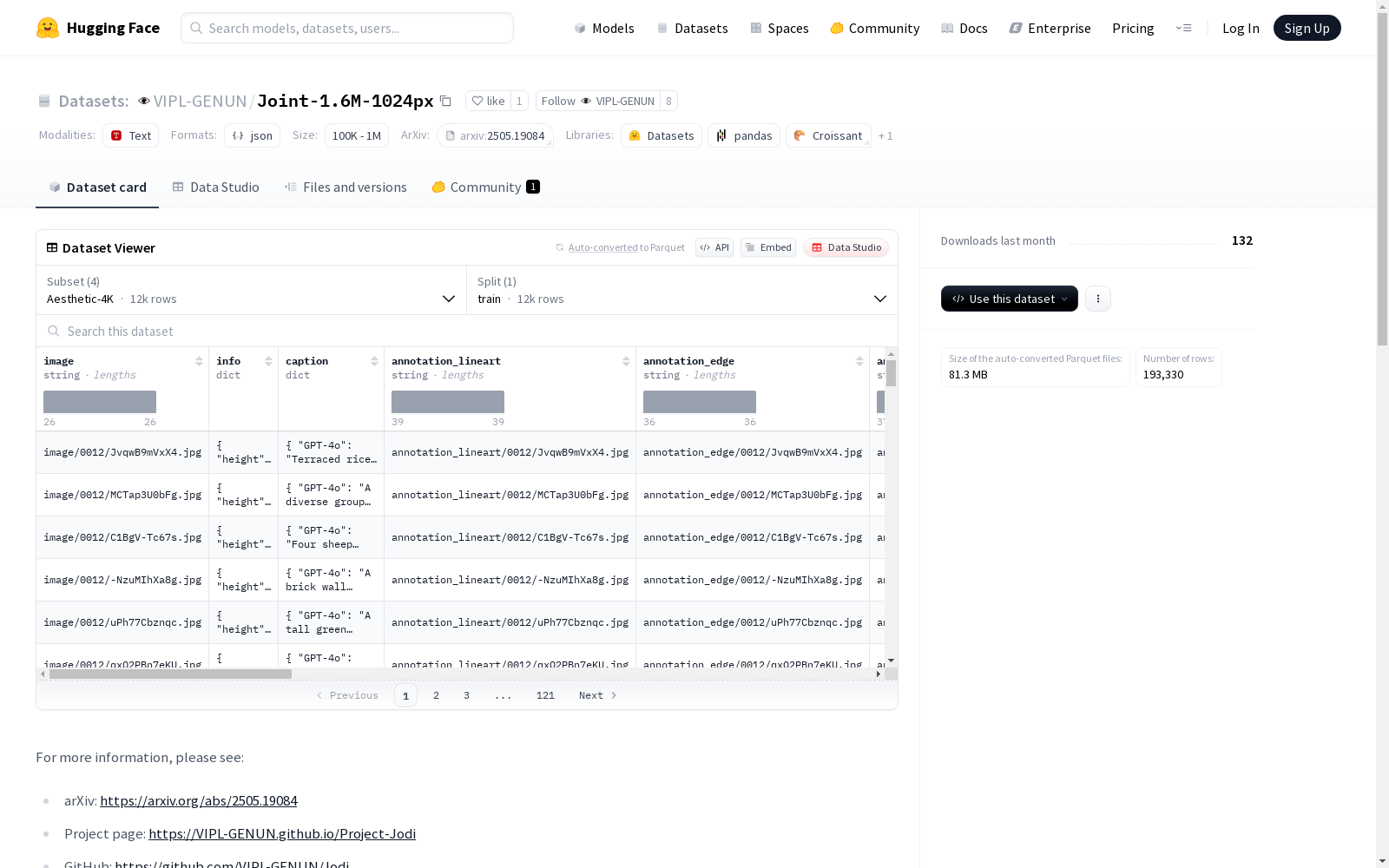
构建方式
在计算机视觉与生成模型领域,高分辨率图像数据集的构建对模型性能具有决定性影响。Joint-1.6M-1024px数据集通过整合多个公开高质量图像源,包括Subjects200K、Aesthetic-4K及Pexels系列数据集,精选分辨率超过1024×1024的图像样本。采用前沿预测模型进行多模态标注,通过Informative Drawings生成线稿、PiDiNet提取边缘图、Depth Anything V2和Lotus预测深度图与法线图,并辅以RGB2X估算反射率、Oneformer进行语义分割、Openpose捕捉人体姿态,最终形成包含约200K图像及7倍对应标注的多维度数据集。文本描述方面融合BLIP2-OPT-2.7b的简洁主体描述与Qwen2-VL-7b-Instruct的细节场景刻画,实现视觉-语言数据的协同构建。
特点
该数据集的核心价值体现在其多模态特性与高分辨率优势。所有图像均经过严格筛选保持1024px以上分辨率,为生成模型训练提供丰富的像素级细节。七种专业标注覆盖线稿、边缘、深度、法线、反射率、分割及人体姿态等视觉理解关键维度,形成立体化的标注体系。文本描述采用双模型融合策略,既保留主体信息的准确性,又增强场景描述的丰富性。这种多粒度、多层次的标注结构,使数据集能同时支持图像生成、跨模态理解、三维重建等复杂任务的联合训练。
使用方法
使用本数据集时需注意其多配置特性,不同子集通过metadata.jsonl文件进行结构化组织。研究者可根据任务需求选择Aesthetic-4K、Subjects200K_collection3等特定配置,或通过train/test划分实现数据分割。加载时建议结合HuggingFace数据集库,直接调用对应config_name获取标准化数据流。对于生成任务,可联合使用图像与BLIP2/Qwen2生成的文本描述;理解任务则可利用七类视觉标注进行多任务学习。通过arXiv文献提供的技术细节与GitHub示例代码,能快速实现数据加载、预处理及模型训练的全流程整合。
背景与挑战
背景概述
Joint-1.6M-1024px数据集由VIPL-GENUN团队于2025年构建,旨在推动高分辨率生成模型与视觉理解任务的联合建模研究。该数据集整合了Subjects200K、Aesthetic-4K等公开资源,精选超过1024×1024分辨率的图像,通过深度估计、语义分割等7类前沿预测模型实现多模态标注,并采用BLIP2与Qwen2-VL模型生成差异化文本描述。作为视觉生成与理解交叉领域的重要基础设施,其多维度标注体系为Jodi等统一框架的研发提供了关键数据支撑。
当前挑战
构建过程中面临两大核心挑战:在领域问题层面,需平衡生成模型对高分辨率数据的依赖与标注成本间的矛盾,传统手工标注难以应对百万级数据的多模态标注需求;在技术实现层面,异构数据源的格式统一与质量筛选消耗大量计算资源,而自动标注模型的预测误差会随数据规模放大。此外,跨模态对齐中文本描述与视觉特征的语义一致性保障,也对预训练模型的泛化能力提出严峻考验。
常用场景
经典使用场景
在计算机视觉领域,高分辨率图像数据集的构建对于生成模型和视觉理解任务至关重要。Joint-1.6M-1024px数据集通过整合多个公开来源的高质量图像,并结合先进的预测工具自动标注多种视觉标签,为生成对抗网络(GANs)和扩散模型提供了丰富的训练素材。其高分辨率特性(超过1024×1024像素)特别适合用于生成高保真度的图像,广泛应用于图像合成、超分辨率重建等任务。
实际应用
在实际应用中,该数据集支持了从创意设计到工业仿真的多种场景。设计师可以利用其生成多样化的视觉素材加速创作流程,游戏开发者能够基于多模态标签快速构建虚拟场景。在影视特效领域,高分辨率图像配合精确的深度和法线信息,大幅提升了三维场景重建的效率和质量。
衍生相关工作
基于该数据集衍生的经典工作包括跨模态生成模型的联合训练框架、多任务视觉理解系统等。特别值得注意的是,原团队提出的Jodi框架通过统一视觉生成与理解的联合建模,在arXiv论文中展示了显著的性能提升。后续研究也广泛采用该数据集验证了文本到图像生成、图像编辑等任务的创新方法。
以上内容由遇见数据集搜集并总结生成


