bowen_vla
收藏Hugging Face2026-05-10 更新2026-05-11 收录
下载链接:
https://huggingface.co/datasets/bowen0923i/bowen_vla
下载链接
链接失效反馈官方服务:
资源简介:
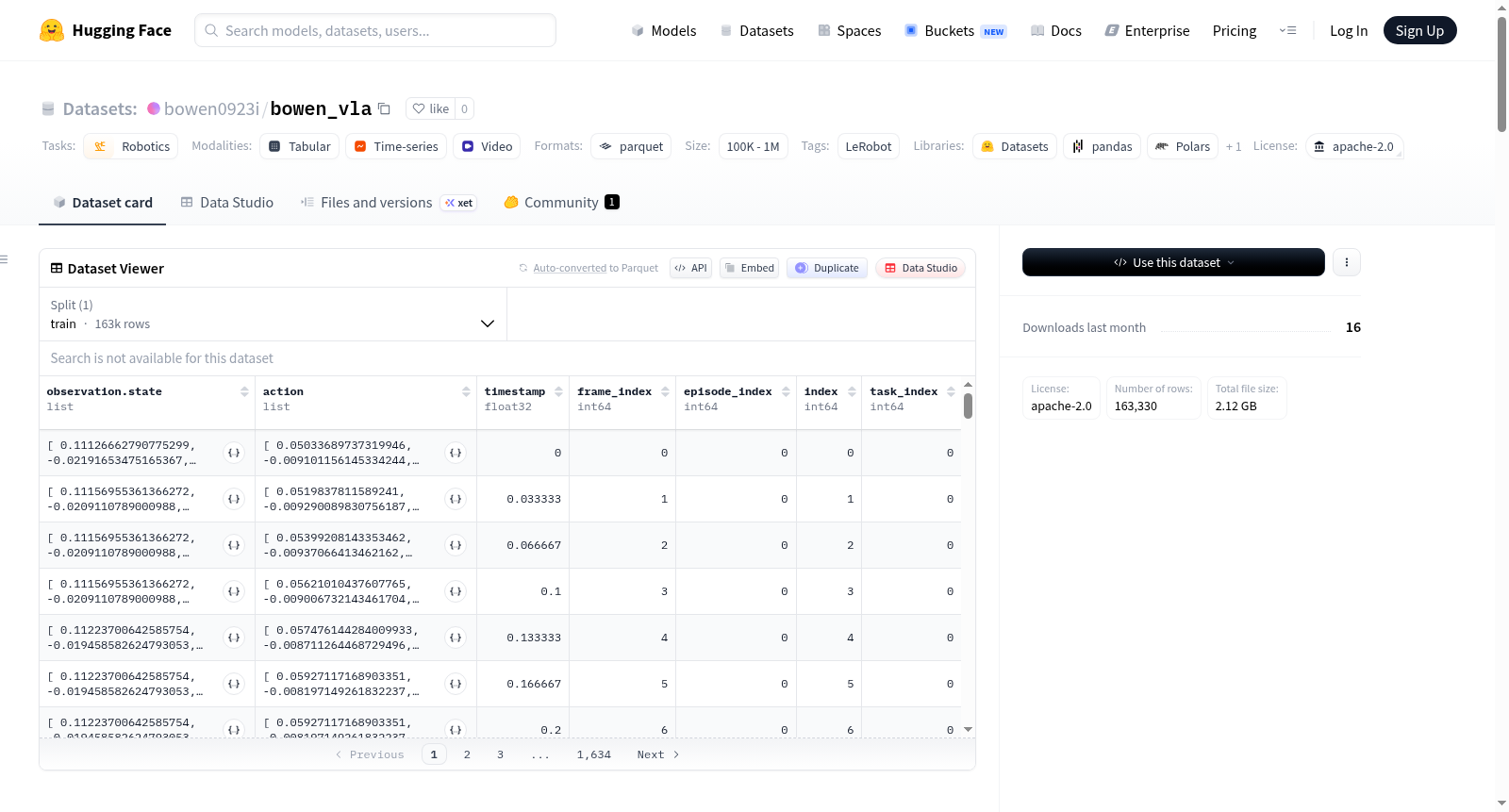
该数据集由LeRobot项目创建,专为机器人技术研究设计,采用Apache 2.0许可证。数据集包含216个训练集片段,总计163,330帧数据,覆盖2种任务类型,并包含648段视频。数据采集自Unitree_G1_Gripper机器人,帧率为30fps。数据集结构包括机器人状态观测(16维浮点数组,描述左右肩、肘、腕及夹持器的关节角度)、动作数据(同构的16维浮点数组)、三个摄像头(左肩高、左腕、右腕)的RGB视频流(480x640分辨率,AV1编码,30fps),以及时间戳、帧索引等辅助字段。所有数据以Parquet格式存储,适用于机器人控制、行为克隆、强化学习等研究场景。
This dataset is created by the LeRobot project, specifically designed for robotics research, and uses the Apache 2.0 license. It includes 216 training segments, totaling 163,330 frames, covering 2 task types, and contains 648 videos. Data is collected from a Unitree_G1_Gripper robot with a frame rate of 30fps. The dataset structure comprises robot state observations (a 16-dimensional floating-point array describing joint angles of left and right shoulders, elbows, wrists, and grippers), action data (a similarly structured 16-dimensional floating-point array), RGB video streams from three cameras (left shoulder high, left wrist, right wrist) at 480x640 resolution, AV1 encoded, 30fps, as well as auxiliary fields like timestamps and frame indices. All data is stored in Parquet format and is suitable for research scenarios such as robot control, behavior cloning, and reinforcement learning.
创建时间:
2026-05-08
原始信息汇总
数据集概述
- 数据集名称: bowen_vla
- 数据集地址: https://huggingface.co/datasets/bowen0923i/bowen_vla
- 许可证: Apache-2.0
- 任务类别: 机器人学 (Robotics)
- 标签: LeRobot
数据集规模
- 总片段数 (episodes): 216
- 总帧数 (frames): 163,330
- 总任务数 (tasks): 2
- 总视频数 (videos): 648
- 总数据块数 (chunks): 1
- 帧率 (fps): 30
数据划分
- 训练集 (train): 片段 0 到 215 (共216个片段)
机器人类型
- 机器人型号: Unitree_G1_Gripper
特征结构
观测状态 (observation.state)
- 数据类型: float32
- 形状: [16]
- 关节名称:
- kLeftShoulderPitch, kLeftShoulderRoll, kLeftShoulderYaw, kLeftElbow, kLeftWristRoll, kLeftWristPitch, kLeftWristYaw
- kRightShoulderPitch, kRightShoulderRoll, kRightShoulderYaw, kRightElbow, kRightWristRoll, kRightWristPitch, kRightWristYaw
- kLeftGripper, kRightGripper
动作 (action)
- 数据类型: float32
- 形状: [16]
- 关节名称: 与观测状态相同
图像观测 (observation.images)
- 相机视角:
- cam_left_high
- cam_left_wrist
- cam_right_wrist
- 图像规格:
- 数据类型: video
- 形状: [3, 480, 640] (通道, 高度, 宽度)
- 编码: av1
- 像素格式: yuv420p
- 帧率: 30
- 通道数: 3
- 无音频
其他特征
- timestamp: float32, 形状 [1]
- frame_index: int64, 形状 [1]
- episode_index: int64, 形状 [1]
- index: int64, 形状 [1]
- task_index: int64, 形状 [1]
数据存储结构
- 数据文件路径:
data/chunk-{episode_chunk:03d}/episode_{episode_index:06d}.parquet - 视频文件路径:
videos/chunk-{episode_chunk:03d}/{video_key}/episode_{episode_index:06d}.mp4
其他信息
- 元数据文件: meta/info.json
- 代码库版本: v2.1
搜集汇总
数据集介绍
构建方式
在机器人学习领域,高质量的数据集是推动具身智能发展的基石。bowen_vla数据集依托LeRobot框架构建,采集自Unitree G1 Gripper双机械臂机器人,共包含216个演示回合、163330个时间帧,覆盖2类操作任务。数据以parquet格式存储于分块目录中,每回合的机器人状态与动作指令均以16维向量精确记录,对应左右臂各7个关节角度及2个夹爪状态。同时,三路摄像头(左高、左手腕、右手腕)以30帧/秒的速率同步采集640×480分辨率的AV1编码视频,为视觉-动作联合建模提供了丰富的多模态观测数据。
特点
该数据集的核心特点在于其高度的结构化与多模态对齐特性。所有回合均按照统一规范组织,状态、动作与视觉观测在时间轴上精确同步,帧索引和时间戳字段确保了时序信息的可追溯性。动作空间与状态空间维度完全一致,便于模仿学习中的直接回归建模。三路摄像头视角的设置为演示过程提供了多角度视觉上下文,能够有效缓解遮挡问题,提升模型在复杂环境中的泛化能力。此外,数据集包含2类不同任务,训练集占比100%,适用于端到端的策略学习研究。
使用方法
使用bowen_vla数据集时,研究者可通过LeRobot库中的数据集加载接口直接读取parquet文件与关联视频。具体而言,借助LeRobot的DataLoader工具,用户可以按回合为单位迭代获取观测状态、视觉图像帧和动作序列,并利用帧索引对齐多模态数据。该数据集可用于训练视觉运动策略,例如基于扩散模型的机器人操作策略或行为克隆网络。由于数据已预设好训练分割,研究者可将全部216个回合用于模型训练,并结合录制的多视角视频进行闭环策略评估与仿真。
背景与挑战
背景概述
在具身智能与机器人学习领域,将大规模视觉-语言模型与物理世界感知及动作执行相融合,是推动通用机器人自主操作能力跃升的关键前沿方向。bowen_vla数据集由研究团队基于LeRobot框架构建,核心研究问题聚焦于如何高效收集并标准化人形机器人在精细操作任务中的多模态演示数据。该数据集收录了Unitree_G1_Gripper机器人在216个操作片段中、总计超过16万帧的真实任务数据,涵盖双手协同、物体抓取等高精度动作,为视觉-语言-动作联合模型的训练提供了高保真的行为先验。其开源发布显著降低了人形机器人领域数据获取的门槛,对推动机器人基础模型从感知到执行的端到端学习具有重要方法论贡献。
当前挑战
该数据集所应对的领域挑战在于解决人形机器人双臂协作中的小样本泛化与精确定位问题。传统的基于规则的编程难以适应非结构化环境,而bowen_vla通过16维关节控制信号实时映射动作空间,为模仿学习提供了高分辨率的行为动态参照。构建过程中面临的挑战尤为突出:首先,确保16个自由度关节角度的同步记录与视觉观测帧率一致(30fps),对硬件同步与数据采集时序提出了严苛要求;其次,多视角视觉输入(左、右腕及左肩相机)的像素对齐与标定误差累积,直接干扰了模型对空间关系的理解;此外,在仅216个演示片段、2类任务约束下,如何保证行为策略的鲁棒性与跨实例迁移能力,仍是数据高效利用的核心瓶颈。
常用场景
经典使用场景
在具身智能与机器人学习领域,bowen_vla数据集为视觉-语言-动作(VLA)模型提供了高质量的训练素材。该数据集采集自Unitree G1 Gripper双机械臂平台,包含216个示范片段、超过16万帧图像与动作序列,覆盖2类操作任务。经典使用场景聚焦于模仿学习与行为克隆,研究者利用多视角视觉观测(包括左高位摄像头及左右腕部摄像头)与16维关节状态、动作指令,训练机器人从人类示范中习得精细的操作策略,如抓取、转移与释放物体,为端到端机器人技能学习奠定了坚实基础。
解决学术问题
bowen_vla数据集针对机器人操作学习中数据稀疏性与泛化能力不足的瓶颈,提供了高频率(30fps)、多模态对齐的示范数据。学术上,它助力解决从视觉观测到连续动作空间映射的核心挑战,即如何将高维图像与本体感知状态有效融合,生成鲁棒的运动策略。该数据集的公开推进了迁移学习与元学习在机器人领域的应用,使跨任务、跨场景的策略泛化成为可能,对理解机器人如何通过观察-行动循环进行自主决策具有深远影响,加速了通用操作智能的理论探索。
衍生相关工作
基于bowen_vla数据集,衍生出一系列代表性研究工作。例如,利用其多视觉输入特性开发的分层模仿学习框架,将任务分解为视觉感知与动作规划子模块;融合扩散模型的动作生成方法,从示范数据中学习高保真轨迹分布,提升操作平滑性。此外,在表征学习方面,该数据集被用于训练视觉-语言联合嵌入,实现自然语言指令到机器人执行的动态映射。这些工作不仅深化了对行为克隆局限性的理解,还催生了对抗性模仿学习与因果推理等前沿方向,持续推动机器人学习研究边界的拓展。
以上内容由遇见数据集搜集并总结生成


